MIPS Strikes Back: 64-bit Warrior I6400 Arrives
by Stephen Barrett on September 2, 2014 10:00 AM ESTIntroduction
One of ARM’s most tangible business advantages is its offer of both CPUs and GPUs to SoC designers. Anyone with experience in business to business relationships knows just how complex forming and maintaining a mutually beneficial collaboration can be. Setting up contracts, forming rapport, defining goals, and even just understanding documentation and technical content formatting all takes time. Unless there is significant benefit to investing in two different relationships and technologies, it is simpler (read: cheaper) to single source contributing components of a design. There are down sides of single sourcing (see Boeing 787 battery fiasco), but depending on a business’ capacity for risk, the savings are undeniable. Especially when ARM undoubtedly offers bundle pricing promotions.
When Imagination Technologies acquired MIPS Technologies in 2012 for $100 million, their goal was very clear – attack ARM. Imagination’s GPU business was already wildly successful, with design wins in a bevy of high end mobile devices including those from Samsung and Apple. Adding the CPU cores from MIPS, with their decades of history designing and licensing IP, strategically positioned Imagination opposite ARM’s licensing business. Imagination’s executives have also stated they are prepared to offer aggressive IP bundling discounts.
Looking at Imagination’s product, press, demos, and interviews, it appears they are not (yet?) positioning MIPS cores to combat ARM cores at the high end of the market. Rather, they appear focused on being a viable alternative to ARM in multi-threaded and low power workloads. In fact, the vast majority of MIPS cores are currently used in network infrastructure where threading and power efficiency are paramount.
Today MIPS is announcing a major launch: the Warrior I6400 core. Based on the 64-bit MIPS64 instruction set (release 6), the Warrior I6400 core is the middle-class CPU core in a family of three, each targeting a different point in the power/performance curve. Imagination is releasing the I6400 core last, which is at the middle of the pack balancing performance with power. Imagination has already released their high-end P56xx series and low-end M51xx series.
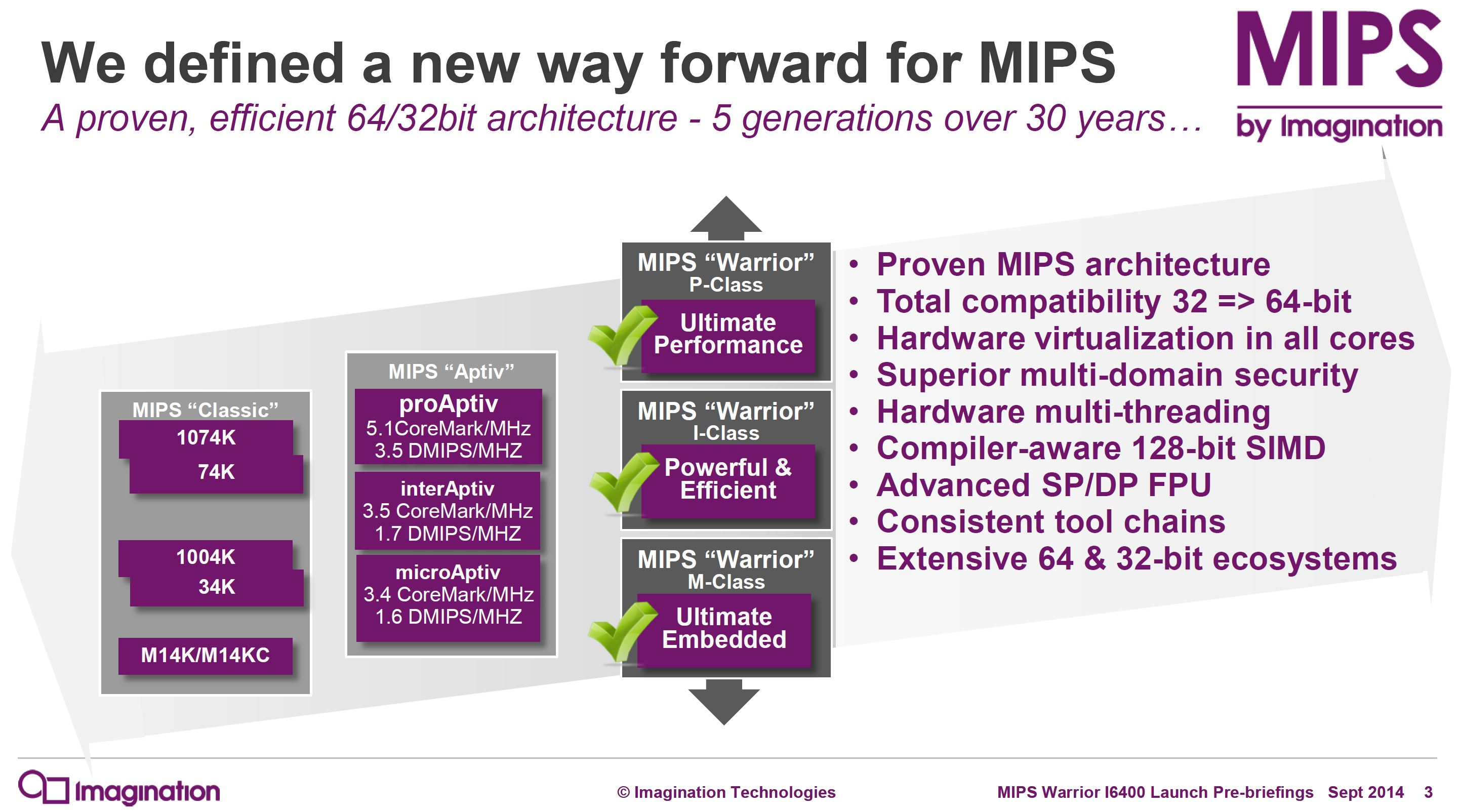
The most analogous ARM core to the I6400 appears to be the ARM Cortex-A53, but I6400 has some interesting features we haven’t seen in this market before and MIPS estimates it will deliver higher performance. I’ve produced a table here to help put performance in context. Note that only A57, A53, P5600, and I6400 are 64-bit processors.
| MIPS and ARM High End IP Cores in Order of Performance | ||
| MIPS |
Manufacturer Estimated DMIPS/MHz/core |
ARM |
| 5.0 | Cortex-A57 | |
| 4.0 |
Cortex-A17 Cortex-A15 |
|
| P5600 | 3.5 | |
| I6400 | 3.0 | |
| 2.5 | Cortex-A9 | |
| 2.3 | Cortex-A53 | |
| 1.9 | Cortex-A7 | |
Keep in mind that these processors use different instruction sets (ISAs) so DMIPS are not directly comparable. However, as they are both RISC processors, the DMIPS should hopefully be roughly comparable. I would like to use directly comparable CoreMark scores but only MIPS provides CoreMark numbers for their processors.
While no one can accurately predict if Imagination will grab additional market share away from ARM, we can educate ourselves on this alternative before it potentially arrives in our hands and homes. And besides, competition is always a good thing.








84 Comments
View All Comments
alexvoica - Tuesday, September 2, 2014 - link
You've (almost too) carefully forgot to mention the trap-and-emulate feature described in the spec.DMStern - Tuesday, September 2, 2014 - link
The documentation also says that only a subset can be trapped, and that some encodings have been re-used. I haven't studied the instruction encoding tables closely enough to know how many, and how serious the conflicts are. Presumably, as more instructions are added in later revisions, the less useful trapping will be.Daniel Egger - Tuesday, September 2, 2014 - link
Finally! I've been waiting a long time for new decent MIPS processors to show up as I've never quite warmed up with the ARM ISA.However the introduction is missing a couple of important facts (probably even more):
1) RISC is usually a load-and-store architecture, meaning there're registers in abundance and the only way to work with data is to load it into registers and store it back if the result is needed later
2) ... and that's also the reason why the instruction set is much simpler because there're less instruction variants because source and targets are known to be registers and in few cases immediates but almost never those funky combinations of different memory access types one can find in CISC
3) This also means that instruction size is constant on RISC vastly simplifying instruction fetching and decoding
4) Whether the code size increases or decreases compared to CISC very much depends on how the application and compiler can utilize the available registers because most of the bloat in RISC is actually caused by loads and stores, however thanks to register starvation on x86 there might be lots of cases where the addressing causes lots of bloat
I would say if there's a comparison between RISC and CISC it should be more detailed on the important differences. Otherwise, why bother at all?
darkich - Tuesday, September 2, 2014 - link
Great, but unfortunately for Imagination, ARM have already started licensing the successors to Cortex A53 and A57.They are codenamed Artemis and Maya
darkich - Tuesday, September 2, 2014 - link
..a bit of clarification, the Artemis refers to the big core while Maya is the small onetuxRoller - Tuesday, September 2, 2014 - link
Great article Stephen.Could you, at some point, go into a bit more depth on the relationships between out of order, superscalar and simultaneous multithreading? Your description of the dispatcher, and classification of this core as in-order, makes me wonder if I understand it at all. In particular, I didn't realise that superscalar is just a special case of out of order, as your text seems to imply (though you do say that it is not out of order, so it is puzzling).
heartinpiece - Tuesday, September 2, 2014 - link
Some inaccurate information:Snoop coherence protocol doesn't connect cores to other cores, or one core doesn't monitor cache lines of another core.
Instead coherence messages are broadcast to all cores of the system, and each core checks whether it has the cache that was broadcasted, and takes appropriate actions.
If 8 cores use snooping, they don't 'connect' to the other 7, but rather the amount of broadcasted coherence messages increases. (Which may clog the interconnect)
In the directory protocol, when a data is updated, the directory notifies the other cores which hold the data to the same address to invalidate the corresponding cache lines (instead of filling the other cores with the updated value).
The reason for such action is because sending the actual value would be too large, and also, even if it is updated in the other cores, if the other cores don't access the newly updated cacheline, then we have sent the updated value for no reason.
Rather, the invalidated approach takes a lazier approach and only fetches the updated value upon read/write to the cacheline.
Exophase - Wednesday, September 3, 2014 - link
More on snooping in Cortex-A53:"Each core has tag and dirty RAMs that contain the state of the cache line. Rather than access these for each snoop request the SCU contains a set of duplicate tags that permit each coherent data request to be checked against the contents of the other caches in the cluster. The duplicate tags filter coherent requests from the system so that the cores and system can function efficiently even with a high volume of snoops from the system."
Stephen Barrett - Wednesday, September 3, 2014 - link
Interesting! Thank you for this detail. I tried to find info about the SCU but I couldn't and my ARM contacts had not gotten back to me yet. I've added a paragraph about thistuxRoller - Wednesday, September 3, 2014 - link
You might also want to update this sentence as the reasoning no longer seems to apply:"This is likely a contributing factor in why the I6400 can be used in SMP clusters of 6, whereas the A53 is limited to SMP clusters of 4."