The Intel Core i7-12700K and Core i5-12600K Review: High Performance For the Mid-Range
by Gavin Bonshor on March 29, 2022 8:00 AM ESTCPU Benchmark Performance: Encoding and Compression
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
We are using DDR5 memory at the following settings:
- DDR5-4800(B) CL40
Encoding
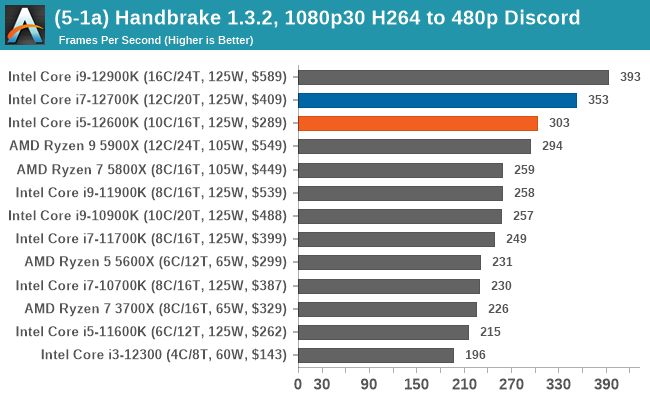
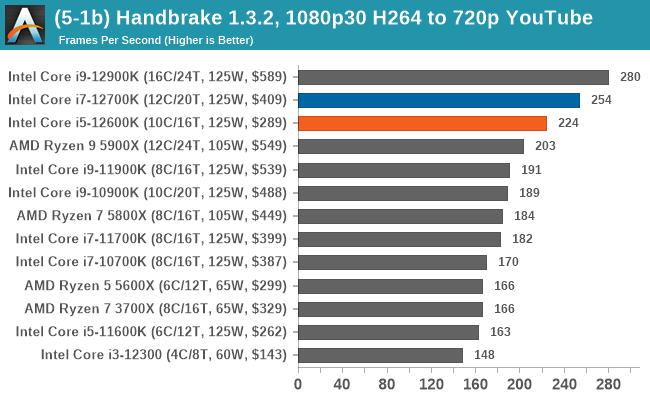
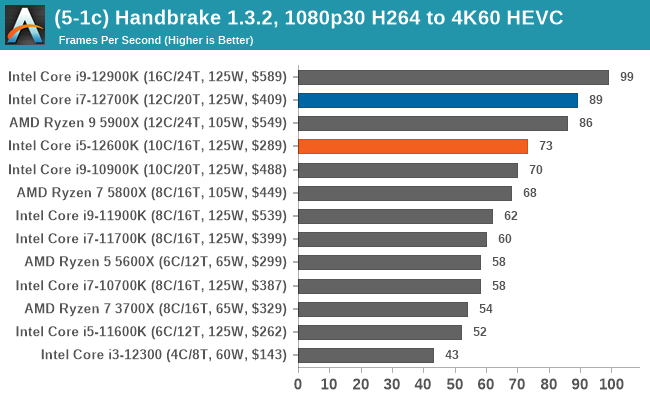
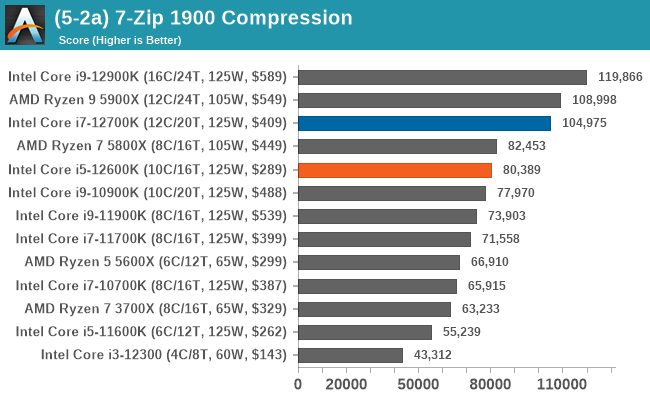
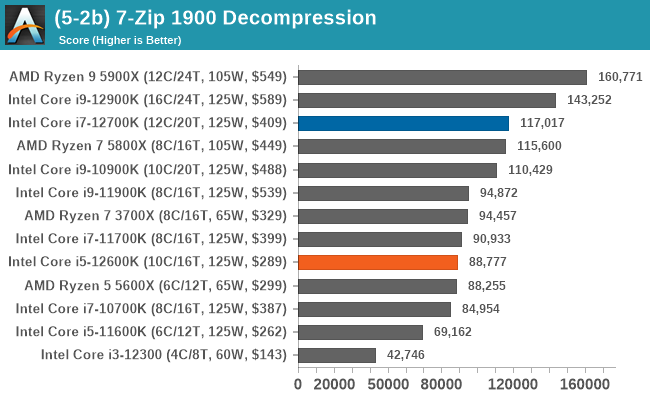
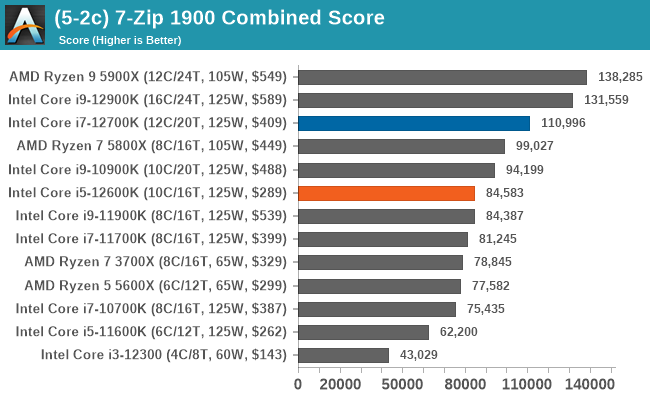
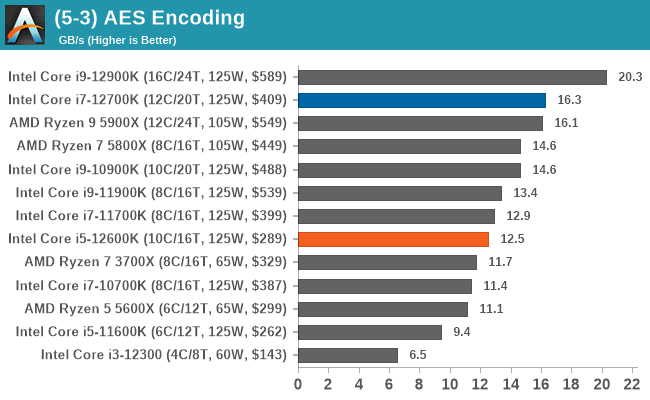
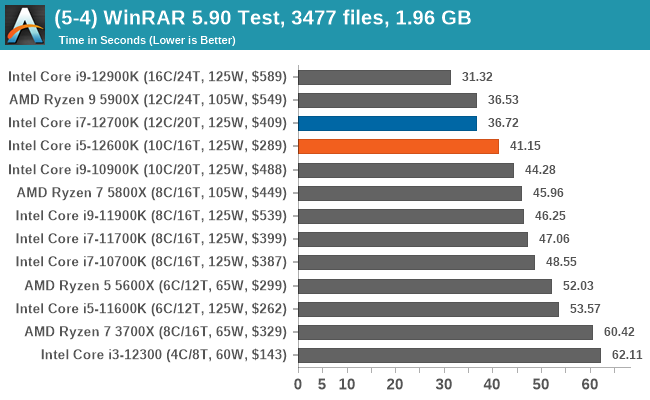
In terms of encoding and compression, Intel's 12th Gen Core gains some wins, but AMD's Ryzen 5000 also wins. It's a very competitive segment, but in the case of the Core i7-12700K and Core i5-12600K, both remain competitive against the competition.








196 Comments
View All Comments
Otritus - Wednesday, March 30, 2022 - link
Chiplets should not give much of a pricing advantage. Going from monolithic dies to chiplets adds manufacturing, validation, and design costs. You save money from the chiplets having better yields and being able to reuse chiplets (like AMD did with their IO die). Intel’s consumer processors aren’t that big and yields are good, so it’s probably a wash overall in pricing (excluding the money Intel saves from in-house manufacturing). Chiplets would be a competitive advantage for big processors (EPYC vs Xeon or Navi 31 vs AD102) because of yields.vlad42 - Friday, April 1, 2022 - link
Nonsense, chiplets absolutely provide a price advantage once you are using more than one CPU chiplet. There's a reason why AMD has done so well in the HEDT, workstation, and server markets. The chiplets allow them to provide more cores for less money than Intel (the yields on those high core count monolithic chips are abysmal by comparison).Qasar - Friday, April 1, 2022 - link
ive read somewhere thats part of the reason why intel cant offer more cores then they do, and why they also went with the P/E core setup. they just can't make the cpus that big with the big cores.mode_13h - Saturday, April 2, 2022 - link
Die size gets expensive as you scale it up, because not only do you get fewer chips/wafer, but yield becomes a major factor. This is even more true on a young process, such as "Intel 7", and why smaller chips tend to be the first to utilize them.In one way or another, cost is *always* a factor, whenever companies are deciding on the parameters of a new chip.
Qasar - Saturday, April 2, 2022 - link
i think, the other reason was power consumption, if intel uses this much power with what 10 P cores ( and no e cores ) i dont want to know what 12, or even 16 cores would use.mode_13h - Sunday, April 3, 2022 - link
> if intel uses this much power with what 10 P cores ( and no e cores )> i dont want to know what 12, or even 16 cores would use.
That's not necessarily a direct tradeoff. They could cap the power (i.e. clocks) and still deliver more performance than 8 P-cores.
Of course, the other thing they could do is trade more die area & clock speed for a uArch with higher IPC, like Apple's. But die area costs $.
The sad reality (for the planet) is that the winning strategy seems to be making less-sophisticated cores that simply clock really high. That gets you winning headline numbers on lightly-threaded benchmarks. Then, wedge in some throughput-optimized cores, so you can also do well on heavily-threaded workloads.
Qasar - Sunday, April 3, 2022 - link
just saw a review of the 12900ks, to me, when a reviewer types " the Core i9-12900KS represents Intel throwing value and power consumption out the window in a no-holds-barred attempt to retain the performance crown, particularly in gaming. " screams desperation. looks like one of the ways intel is only able to compete, is by doing this.Mike Bruzzone - Tuesday, April 5, 2022 - link
@Otritus, I agree MCMs trade off packaging cost for monolithic die fabrication cost. Moving to Systems in Package in the near term will eclipse their dice fabrication costs; "manufacturing, validation, and design costs". mbKhanan - Thursday, April 7, 2022 - link
Last time I checked 5950X had still more performance despite being challenged by a 250W auto OC 12900K. I mean, imagine, you can easily activate auto OC on 5950X with activating PBO too. And yep it crushes the 12900K then. Reviews that don’t reflect this are as per usual kinda trashy.mode_13h - Wednesday, March 30, 2022 - link
> They have 90-95% of the performance for less than half, or in some cases, 1/3rd the power.I don't see how you can draw that conclusion, when the article only lists *peak* power. What's needed is joules per test, for the fixed-size tests.