Intel 12th Gen Core Alder Lake for Desktops: Top SKUs Only, Coming November 4th
by Dr. Ian Cutress on October 27, 2021 12:00 PM EST- Posted in
- CPUs
- Intel
- DDR4
- DDR5
- PCIe 5.0
- Alder Lake
- Intel 7
- 12th Gen Core
- Z690
Thread Director: Windows 11 Does It Best
Every operating system runs what is called a scheduler – a low-level program that dictates where workloads should be on the processor depending on factors like performance, thermals, and priority. A naïve scheduler that only has to deal with a single core or a homogenous design has it pretty easy, managing only power and thermals. Since those single core days though, schedulers have grown more complex.
One of the first issues that schedulers faced in monolithic silicon designs was multi-threading, whereby a core could run more than one thread simultaneously. We usually consider that running two threads on a core usually improves performance, but it is not a linear relationship. One thread on a core might be running at 100%, but two threads on a single core, while overall throughput might increase to 140%, it might mean that each thread is only running at 70%. As a result, schedulers had to distinguish between threads and hyperthreads, prioritizing new software to execute on a new core before filling up the hyperthreads. If there is software that doesn’t need all the performance and is happy to be background-related, then if the scheduler knows enough about the workload, it might put it on a hyperthread. This is, at a simple level, what Windows 10 does today.
This way of doing things maximizes performance, but could have a negative effect on efficiency, as ‘waking up’ a core to run a workload on it may incur extra static power costs. Going beyond that, this simple view assumes each core and thread has the same performance and efficiency profile. When we move to a hybrid system, that is no longer the case.
Alder Lake has two sets of cores (P-cores and E-cores), but it actually has three levels of performance and efficiency: P-cores, E-Cores, and hyperthreads on P-cores. In order to ensure that the cores are used to their maximum, Intel had to work with Microsoft to implement a new hybrid-aware scheduler, and this one interacts with an on-board microcontroller on the CPU for more information about what is actually going on.
The microcontroller on the CPU is what we call Intel Thread Director. It has a full scope view of the whole processor – what is running where, what instructions are running, and what appears to be the most important. It monitors the instructions at the nanosecond level, and communicates with the OS on the microsecond level. It takes into account thermals, power settings, and identifies which threads can be promoted to higher performance modes, or those that can be bumped if something higher priority comes along. It can also adjust recommendations based on frequency, power, thermals, and additional sensory data not immediately available to the scheduler at that resolution. All of that gets fed to the operating system.

The scheduler is Microsoft’s part of the arrangement, and as it lives in software, it’s the one that ultimately makes the decisions. The scheduler takes all of the information from Thread Director, constantly, as a guide. So if a user comes in with a more important workload, Thread Director tells the scheduler which cores are free, or which threads to demote. The scheduler can override the Thread Director, especially if the user has a specific request, such as making background tasks a higher priority.
What makes Windows 11 better than Windows 10 in this regard is that Windows 10 focuses more on the power of certain cores, whereas Windows 11 expands that to efficiency as well. While Windows 10 considers the E-cores as lower performance than P-cores, it doesn’t know how well each core does at a given frequency with a workload, whereas Windows 11 does. Combine that with an instruction prioritization model, and Intel states that under Windows 11, users should expect a lot better consistency in performance when it comes to hybrid CPU designs.
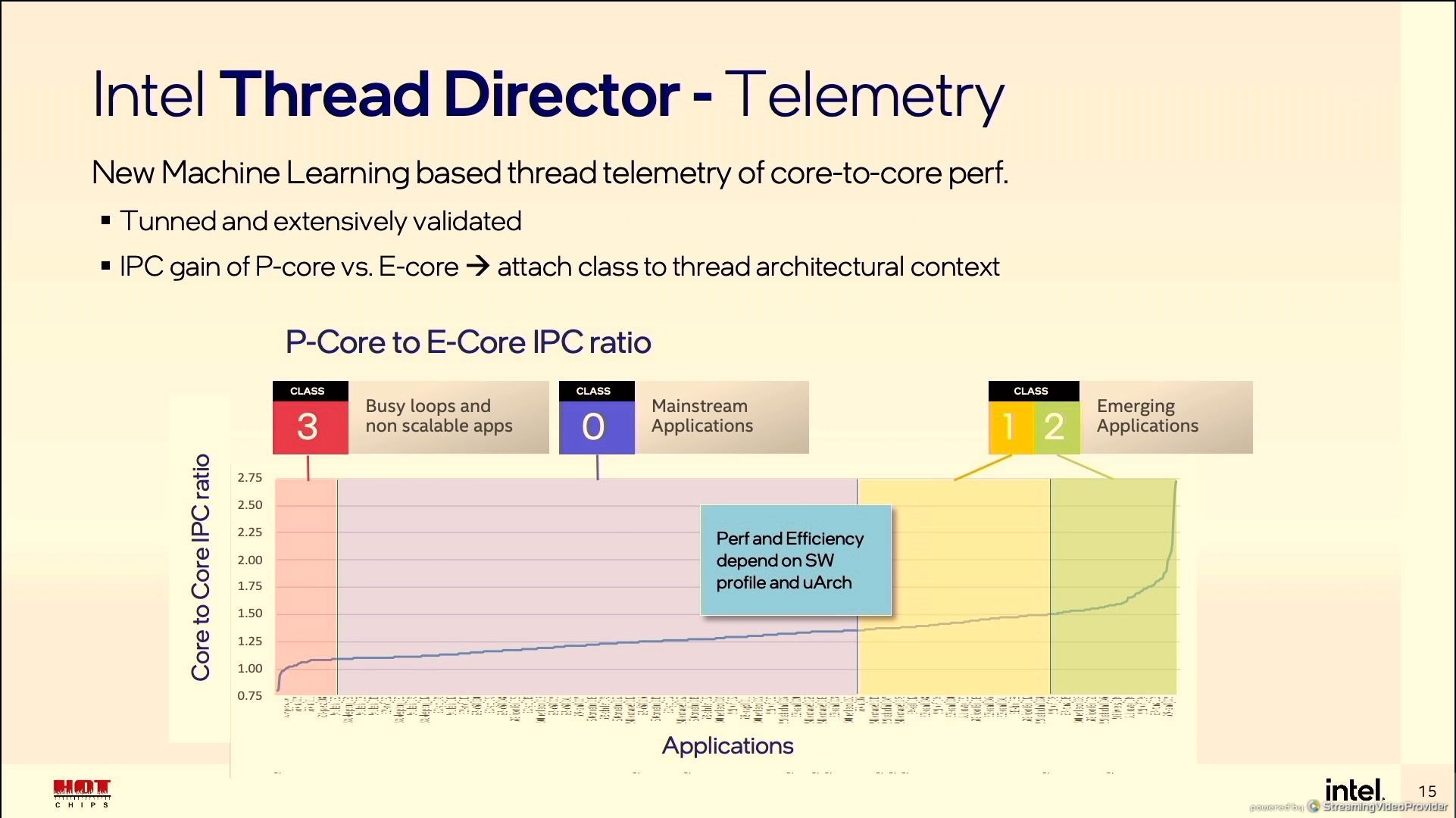
Under the hood, Thread Director is running a pre-trained algorithm based on millions of hours of data gathered during the development of the feature. It identifies the effective IPC of a given workflow, and applies that to the performance/efficiency metrics of each core variation. If there’s an obvious potential for better IPC or better efficiency, then it suggests the thread is moved. Workloads are broadly split into four classes:
- Class 3: Bottleneck is not in the compute, e.g. IO or busy loops that don’t scale
- Class 0: Most Applications
- Class 1: Workloads using AVX/AVX2 instructions
- Class 2: Workloads using AVX-VNNI instructions
Anything in Class 3 is recommended for E-cores. Anything in Class 1 or 2 is recommended for P cores, with Class 2 having higher priority. Everything else fits in Class 0, with frequency adjustments to optimize for IPC and efficiency if placed on the P-cores. The OS may force any class of workload onto any core, depending on the user.
There was some confusion in the press briefing as to whether Thread Director can ‘learn’ during operation, and how long it would take – to be clear, Thread Director doesn’t learn, it already knows from the pre-trained algorithm. It analyzes the instruction flow coming into a core, identifies the class as listed above, calculates where it is best placed (which takes microseconds), and communicates that to the OS. I think the confusion came with the difference in the words ‘learning’ and ‘analyzing’. In this case, it’s ‘learning’ what the instruction mix to apply to the algorithm, but the algorithm itself isn’t updated in the way that it is ‘learning’ and adjusting the classes. Ultimately even if you wanted to make the algorithm self-learn your workflow, the algorithm can’t actually see which thread relates to which program or utility – that’s something on the operating system level, and down to Microsoft. Ultimately, Thread Director could suggest a series of things, and the operating system can choose to ignore them all. That’s unlikely to happen in normal operation though.
One of the situations where this might rear its head is to do with in-focus operation. As showcased by Intel, the default behavior of Windows changes depending on whether on the power plan.
When a user is on the balanced power plan, Microsoft will move any software or window that is in focus (i.e. selected) onto the P-cores. Conversely, if you click away from one window to another, the thread for that first window will move to an E-core, and the new window now gets P-core priority. This makes perfect sense for the user that has a million windows and tabs open, and doesn’t want them taking immediate performance away.
However, this way of doing things might be a bit of a concern, or at least it is for me. The demonstration that Intel performed was where a user was exporting video content in one application, and then moved to another to do image processing. When the user moved to the image processing application, the video editing threads were moved to the E-cores, allowing the image editor to use the P-cores as needed.
Now usually when I’m dealing with video exports, it’s the video throughput that is my limiting factor. I need the video to complete, regardless of what I’m doing in the interim. By defocusing the video export window, it now moves to the slower E-cores. If I want to keep it on the P-cores in this mode, I have to keep the window in focus and not do anything else. The way that this is described also means that if you use any software that’s fronted by a GUI, but spawns a background process to do the actual work, unless the background process gets focus (which it can never do in normal operation), then it will stay on the E-cores.
In my mind, this is a bad oversight. I was told that this is explicitly Microsoft’s choice on how to do things.
The solution, in my mind, is for some sort of software to exist where a user can highlight programs to the OS that they want to keep on the high-performance track. Intel technically made something similar when it first introduced Turbo Max 3.0, however it was unclear if this was something that had to come from Intel or from Microsoft to work properly. I assume the latter, given the OS has ultimate control here.
I was however told that if the user changes the Windows Power Plan to high-performance, this behavior stops. In my mind this isn’t a proper fix, but it means that we might see some users/reviews of the hardware with lower performance if the workload doing the work is background, and the reviewer is using the default Balanced Power Plan as installed. If the same policy is going to apply to Laptops, that’s a bigger issue.








395 Comments
View All Comments
lmcd - Wednesday, October 27, 2021 - link
You don't remember correctly at all. Apple's little cores are stupidly fast for little cores. Andrei flails in every Apple SoC review how stupid it is that there's no ARM licensed core answer to Apple's little cores.Intel probably roadmapped Alder Lake the minute they saw how performant Apple little cores were in even the iPhone 6S.
Atom has been surprisingly good for a while. No need to make up conspiracies when you can buy a Jasper Lake SKU that confirms Intel Atom is far from slow.
name99 - Thursday, October 28, 2021 - link
Apple's small cores are- about 1/3 the performance at
- about 1/0th the power, net result being
- same amount of computation takes about 1/3 the energy.
The Intel cores appear (based on what's claimed) to be substantially faster -- BUT at the cost of substantially more power and thus net energy.
If they are 70% of a P core but also use 70% of the power, that's net equal energy! No win!
It won't be that bad, but if it's something like 70% of a P core at 35% of the power, that's still only half the net energy. Adequate, but not as good as Apple. My guess is we won't get as good as that, we'll land up at something like 50% of the power, so net 70% of the energy of a P core.
(And of course you have to be honest in the accounting. Apple integrates the NoC speed, cache speeds, DRAM speed all ramped up or down in tandem with demand, so that if you're running only E cores it's your entire energy footprint that's reduced to a third. Will Intel drop the E-*core* energy quite a bit, but it makes no real difference because everything from the NoC to the L3 to the DRAM to the PCIe is burning just as much power as before?)
Essentially Apple is optimizing for energy usage by the small cores, whereas Intel seems to be optimizing for something like "performance per area".
That's not an utterly insane design point, but it's also not clear that it's a *great* design point. In essence, it keeps Intel on the same track as the past ten years or so -- prioritizing revenue issues over performance (broadly defined, to include things like energy and new functionality). And so it keeps Intel on track with the Intel faithful -- but does nothing to expand into new markets, or to persuade those who are close to giving up on Intel.
Or to put it more bluntly, it allows Intel to ship a box that scores higher in Cinebench-MT at the same chip area -- but that's unlikely to provide an notably different, "wow", experience from its predecessor, either in energy use or "normal" (ie not highly-threaded) apps.
Of course we'll see when the Anandtech review comes out. But this is what it looks like to me, as the salient difference between how Apple (and, just not as well, ARM) think of big vs little, compared to Intel.
nandnandnand - Thursday, October 28, 2021 - link
"It won't be that bad, but if it's something like 70% of a P core at 35% of the power, that's still only half the net energy."I don't know how it will compare to Apple, but if it has a performance-per-area *and* a performance-per-watt advantage, it is a major improvement for x86. Especially as Intel iterates and puts 16 or 32 E-cores alongside 8 P-cores.
Basically, Intel can continue to tinker with the P-cores to get the best possible single-threaded performance, knowing that 8 P-cores is enough for anyone™, but spamming many E-cores is Intel's path to more multi-threaded performance.
Alder Lake can be considered a beta test. The benefits will really be felt when we see 40 cores, 48 threads (8+32) at the die space equivalent of 16 P-cores. The next node shrink after "Intel 7" will help keep power under control.
vogonpoetry - Wednesday, October 27, 2021 - link
User-rewritable SPDs are a total game-changer for RAM overclockers. Many times I have wished for such a feature. As is on-the-fly power/frequency adjustment (though I wish we could change timings too).As for "Dynamic Memory Boost", doesnt Power Down Mode already do something similar currently? My DDR4 laptop memory frequency can be seen changing depending on workload.
Oxford Guy - Thursday, October 28, 2021 - link
All overclocking is dead.Oxford Guy - Thursday, October 28, 2021 - link
I should have said: 'All user overclocking is dead'.Vendor-approved overclocking (i.e. going beyond JEDEC) is another matter.
Silver5urfer - Wednesday, October 27, 2021 - link
On paper it looks okay. Staring with the Z690 chipset is a really deserved upgrade, lot of I/O plus RAID mode optimizations. AMD RAID is so bad, Level1Techs also showed how awful it was.STIM is interesting, given how 10900K and 11900K improved vastly with Delidding and LM. So that's a plus. Then the whole Win11 BS is annoying garbage. The WIn11 OS is horrible anti user anti desktop anti computing it reeks desperation to imitate Apple as an Ape. It looks ugly, has Win32 downgrades with integration to UWP, Taskbar downgrades, Awful explorer UI. It's outright unacceptable.
Now the big part CPU and Price - Looks like Intel is pricing it wayy lower than AMD. For unknown reasons as Intel never does it, I find it disrupting. Also the CPU OC features are somewhat okay I was expecting lower clocks but looks like 5.1GHz but looking that the new PL1 system I do not have a problem at all since I want full performance now no more BS by GN and etc citing omg the power limits 125W must be kept on a damn K unlocked processor. But there were rumors on power consumption going past 350W like RKL once OCed that's the reason why Intel is going 8C max unlike Sapphire Rapids Xeon at 14C. DDR5 is also on it's new life not worth investing money into the DDR5 new adopter tax if DDR4 works which is what I'm curious about RKL Gear 1 4000Mhz is impossible. I wonder how this will fare.
The leaked performance preview shows mediocre improvements, the ST is definitely a lead on the P cores, real cores. But the SMT / HT is really what I'm interested vs 10900K and Ryzen 5900X. RKL is also fast in ST but SMT was okay not great because 14nm backport.
I'll be waiting to see how Intel executes this, not going to invest tbh because new chipset, new CPU design, Win11 and I want to run Windows 7. I'd rather settle for a 10900K on Z590. PCIe SSDs are not much of a value for me, they have no use beyond load times and boot times for my use case, MLC 860 Pro SATA SSD is way better, runs cool, long lasting as well.
Gothmoth - Wednesday, October 27, 2021 - link
people who do raid without a dedicated PCIe RAID controller have no clue anyway.while most focus on performance i am waiting on performance per WATT figures.
vegemeister - Wednesday, October 27, 2021 - link
Hardware RAID is a recipe for weird bugs and data loss, and provides no benefit over software RAID on top of the same controller running as a dumb HBA.Motherboard fake RAID is similarly pointless.
Gigaplex - Thursday, October 28, 2021 - link
I'd rather do mdadm software RAID or use ZFS vs a PCIe RAID controller.