Arm Announces Armv9 Architecture: SVE2, Security, and the Next Decade
by Andrei Frumusanu on March 30, 2021 2:00 PM ESTFuture Arm CPU Roadmaps
Not directly related to v9, however tied into the technology roadmap of the upcoming v9 designs in the near future, Arm also talked about some points regarding their projected performance of v9 designs in the next 2 years.
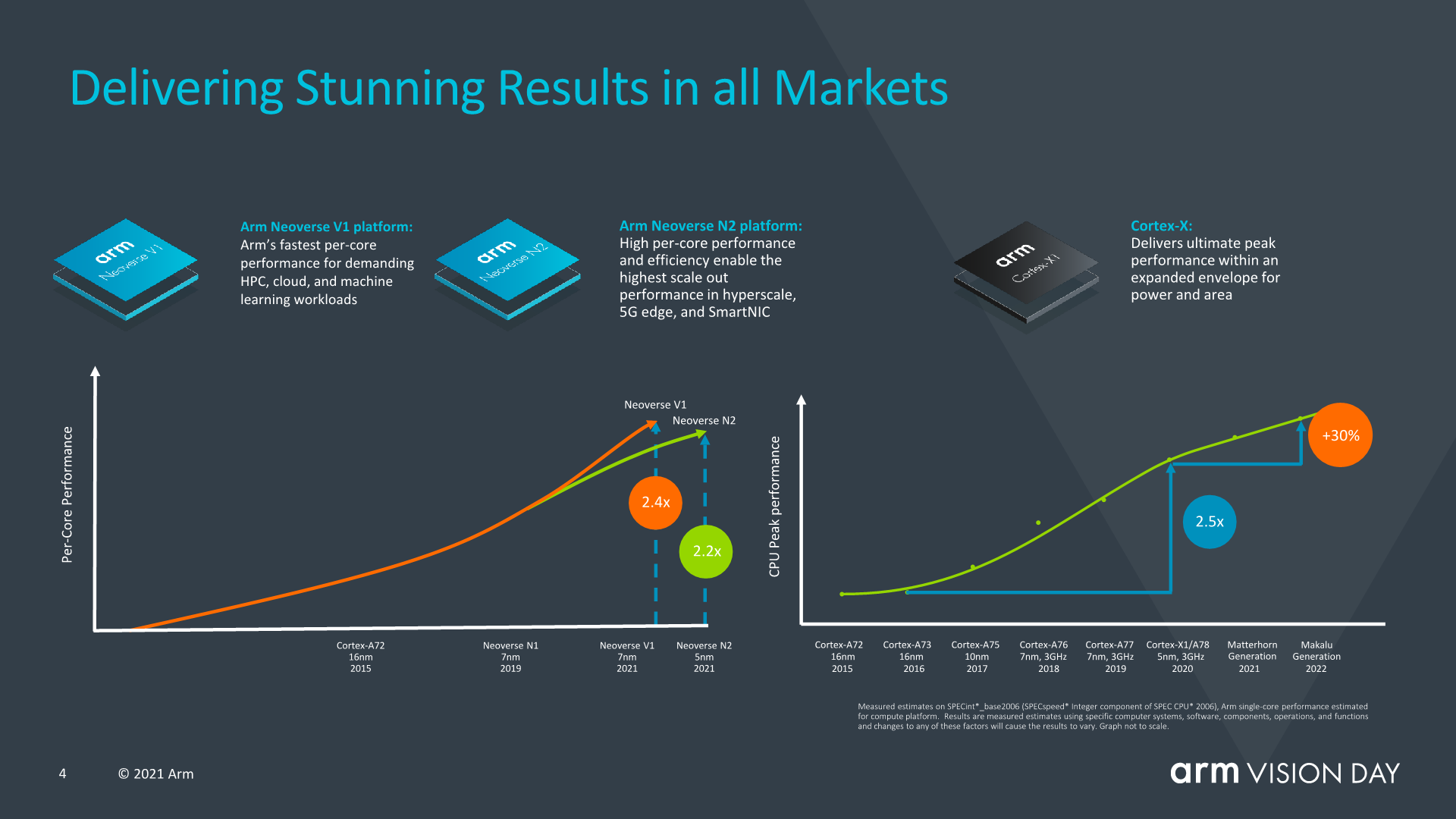
Arm talked about how the mobile space had seen performance increases of 2.4x (we’re talking purely ISO-process design IPC here) of this year’s X1 devices compared to the Cortex-A73 a few years ago in 2016.
Interestingly, Arm also talked about Neoverse V1 designs and how they’re achieving 2.4x the performance of A72 class designs, and discloses that they are expecting the first V1 devices to he released later this year.
For the next-generation mobile IP cores, code-named Matterhorn and Makalu, the company is disclosing an aggregate expected 30% IPC gain across these two generations, excluding frequency or any other additional performance gains which could be reached by SoC designers. This actually represents a 14% generational increases across these two new designs, and as showcased in the performance curve in the slide, would indicate that improvements are slowing down relative to what Arm had managed over the past few years since the A76. Still, the company states that the rate of advancement is still well beyond the industry average – admittedly that is being dragged down by some players.
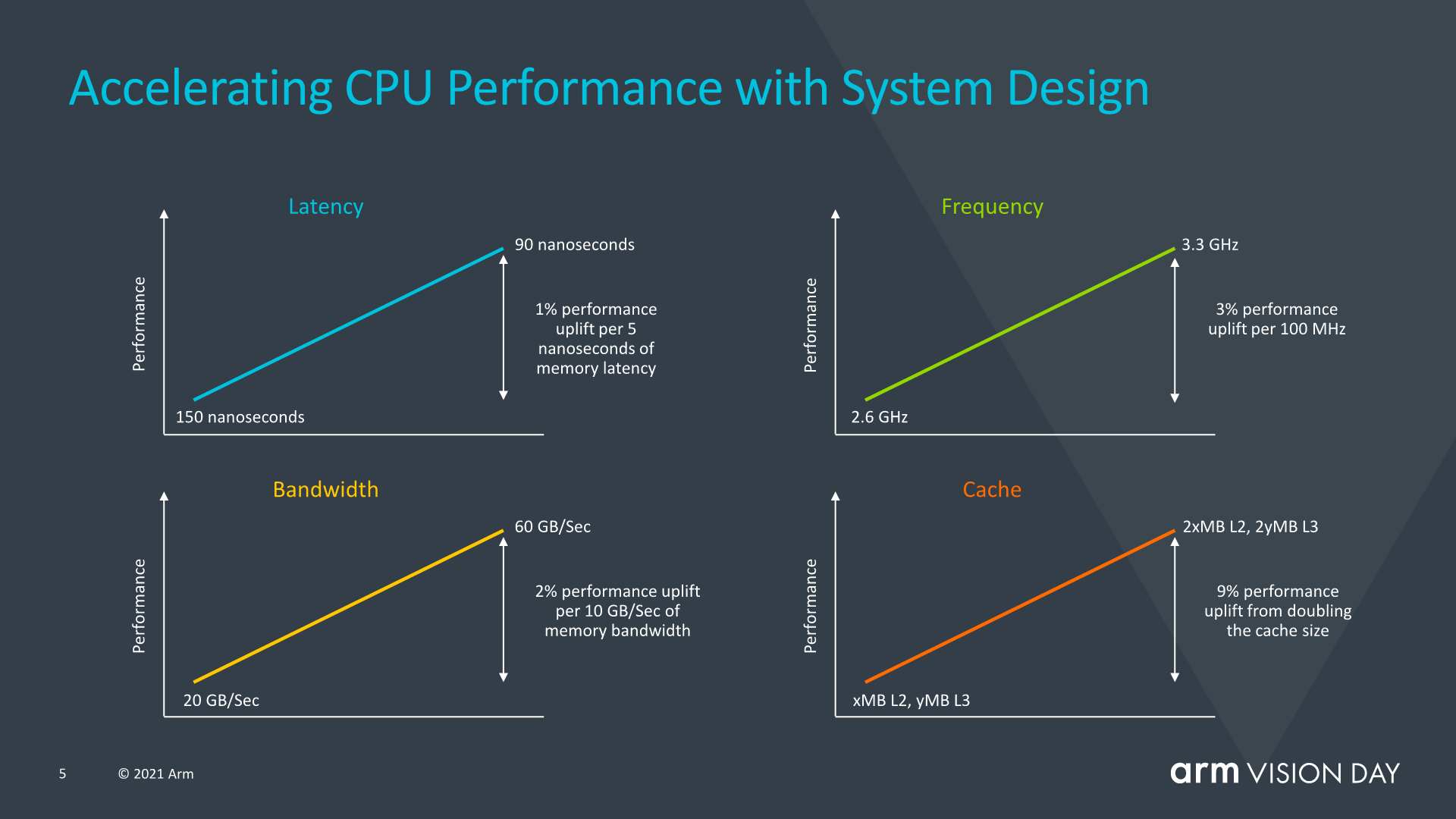
Oddly enough, Arm also included a slide that wanted to focus on the system-side impact on performance, rather than just CPU IP performance. Some of the figures presented here, such as 1% of performance per 5ns of memory latency have been figures that we had talked about extensively for a few generations now, but Arm here also points out that there’s a whole generation of CPU performance that can be squeezed out if one focuses on improving various other aspects of an implementations by improving the memory path, increasing caches, or optimising frequency capabilities. I consider this to be a veiled shot at the current conservative approaches from SoC vendors which are not fully utilising the expected performance headroom of X1 cores, and subsequently also not reaching the expected performance projections of the new core.

Arm continues to see the CPU as the most versatile compute block for the future. While dedicated accelerators or GPUs will have their place, they have a hard time to address important points such as programmability, protection, pervasiveness (essentially ability to run them on any device), and proven abilities to work correctly. Currently, the compute ecosystem is extremely fragmented in how things are run, not only differing between device types, but also differing between device vendors and operating systems.
SVE2 and Matrix multiplication can vastly simplify the software ecosystem, and allow compute workloads to take a step forward with a more unified approach that will be able to run on any device in the future.

Lastly, Arm had a nugget of new information on the future of Mali GPUs, disclosing that the company is working on new technologies such as VRS and in particular Ray Tracing. The latter point is quite surprising to hear, and signals that the desktop and console ecosystem push by AMD’s and Nvidia’s introduction of RT is also expected to push the mobile GPU ecosystem towards RT.
Armv9 designs to be unveiled soon, devices in early 2022
Today’s announcement came in an extremely high-level format, and we expect Arm to talk more about the various details of Armv9 and new features such as CCA in the company’s usual yearly tech disclosures in the coming months.
In general, Armv9 appears to be a mix between a more fundamental ISA shift, which SVE2 can be seen as, and a general re-baselining for the software ecosystem to aggregate the last decade of v8 extensions, and build the foundation for the next decade of the Arm architecture.
Arm had already talked about the Neoverse V1 and N2 late last year, and I do expect the N2 at least to be eventually unveiled as a v9 design. Arm further discloses to expect more Armv9 CPU designs, likely the mobile-side Cortex-A78 and X1 successors, to be unveiled this year, with the new CPUs likely to have already been taped-in by the usual SoC vendors, and expected to be seen in commercial devices in early 2022.








74 Comments
View All Comments
mdriftmeyer - Thursday, April 1, 2021 - link
You're deluded. The amount of Work in Clang on C/C++ should be clear these are the foundational languages. Apple made the mistake of listening to Lattner before he bailed and developed Swift. If they're smart the fully modernize ObjC and turn Swift into a training language.name99 - Tuesday, March 30, 2021 - link
"The benefit of SVE and SVE2 beyond addition various modern SIMD capabilities is in their variable vector size, ranging from 128b to 2048b, allowing variable 128b granularity of vectors, irrespective of what the actual hardware is running on"Not you too, Andrei :-(
This is WRONG! This increased width is a minor benefit outside a few specialized use cases. If you want to process 512 bits of vector data per cycle, you can do that today on an A14/M1 (4 wide NEON).
The primary value of SVE/2 is the introduction of new types of instructions that are a much better match to compilers, and to non-regular algorithms.
Variable width matters, but NOT in the sense that I can build a 128 bit or a 512 bit implementation; it matters in that I can write a single loop (without prologue or epilogue) targeting an arbitrary width array, without expensive overhead. Along with variable-width adjacent functionality like predicate and scatter/gather.
eastcoast_pete - Tuesday, March 30, 2021 - link
Could these properties of SVE2 make Armv9 designs more attractive for, for example, AV1 (and, to come AV2) video encoding?I could see some customer interest there, at least if hosted by AWS or Azure.
name99 - Tuesday, March 30, 2021 - link
I don't know what's involved with AV1 and AV2 encoding. With the older codecs that I do know, most of the encoding algorithm is in fact extremely regular, so there's limited win from providing support for non-regularity.My point is that SVE/2 is primarily a win for types of code that, today, do not benefit much from vectors. It's much less of a win for code that's already strongly improved by vectors.
Andrei Frumusanu - Tuesday, March 30, 2021 - link
That's literally what I meant, in a just less explicit way.Over17 - Thursday, April 8, 2021 - link
What is the "expensive overhead" in question? If you're writing a loop which processes 4 floats, then the tail is no longer than 3 floats. Even if you manually unroll it 4x, then it's 15 floats max to process in the epilogue. For SIMD to give any benefit, you should be processing large amounts of data so even 15 scalar operations is nothing comparing to the main loop.If we're talking about the size of code, then it's true; the predicates in SVE2 are making the code look smaller. So the overhead is more about the maintenance costs, isn't it?
eastcoast_pete - Tuesday, March 30, 2021 - link
Maybe it's just me, but did anyone else notice that Microsoft was prominently mentioned in several slides in ARM's presentation? To me, it means that both companies are very serious about Windows on ARM, including on the server side. I guess we'll see soon enough if the custom-ARM processor MS is apparently working on has Armv9 baked into it already. I would be surprised if it doesn't.And, here my standard complaint about the LITTLE cores: Quo usque tandem, ARM? When will we see a LITTLE core design with out-of-order execution, so that stock ARM designs aren't 2-3 times worse anymore on Perf/W vs Apple's LITTLE cores. That does matter for smartphones, because staying on the LITTLE cores longer and more often improves battery longevity. I know today was about the next big ISA, but some mentioning of "we're working on it" would have been nice.
SarahKerrigan - Tuesday, March 30, 2021 - link
Wouldn't surprise me if the ARMv9 little core looks more like the A65 - narrow OoO.BillBear - Tuesday, March 30, 2021 - link
I wonder if the Matrix Multiplication implementation currently shipping on Apple's M1 chip is just an early implementation of this new spec?https://medium.com/swlh/apples-m1-secret-coprocess...
Apple certainly had an ARM v8 implementation shipping well in advance of anyone else.
name99 - Thursday, April 1, 2021 - link
Seems unlikely.The ARMv8.6 matrix multiply instructions use the NEON or SVE registers
https://community.arm.com/developer/ip-products/pr...
and so can provide limited speedup;
the Apple scheme uses three totally new (and HUGE) registers, the X, Y, and Z registers. It runs within the CPU but "parallel" to the CPU, there are interlocks to ensure that the matrix instructions are correctly sequenced relative to the non-matrix instructions, but overall the matrix instructions run like an old-style (80s or so) coprocessor, not like part of the SIMD/fp unit.
The Apple scheme feels very much like they appreciate it's a stop-gap solution, an experiment that's being evolved. As such they REALLY don't want you to code directly to it, because I expect they will be modifying it (changing register sizes, register layout, etc) every year, and they can hide that behind API calls, but don't want to have to deal with legacy code that uses direct AMX instructions.