Intel Details Manufacturing through 2023: 7nm, 7+, 7++, with Next Gen Packaging
by Ian Cutress & Anton Shilov on May 8, 2019 4:35 PM EST
At Intel's Investor Day today, CEO Bob Swan and Murthy Renduchintala spoke to the ability of the company with respect to its manufacturing capabilities. Intel has historically been strong in its ability to execute on its process technology, however the delay of its 10nm process has obviously raised multiple question marks, and has done for several years. The two Intel executives went into a little detail about what Intel was doing in the interim, and how it has learned from the issues.

Back in 2013, Intel envisoned its 10nm to succeed the 14nm by providing 2.7x density, with new technologies such as Self-Aligned Quad Patterning (SAQP), Contact over Active Gate (COAG), Cobolt Interconnects, and new packaging technologies such as EMIB and Foveros. Intel admits that this was an ambitious plan, and the goals were not clearly defined with the teams and it was ultimately overly complex and not managed in an ideal way.
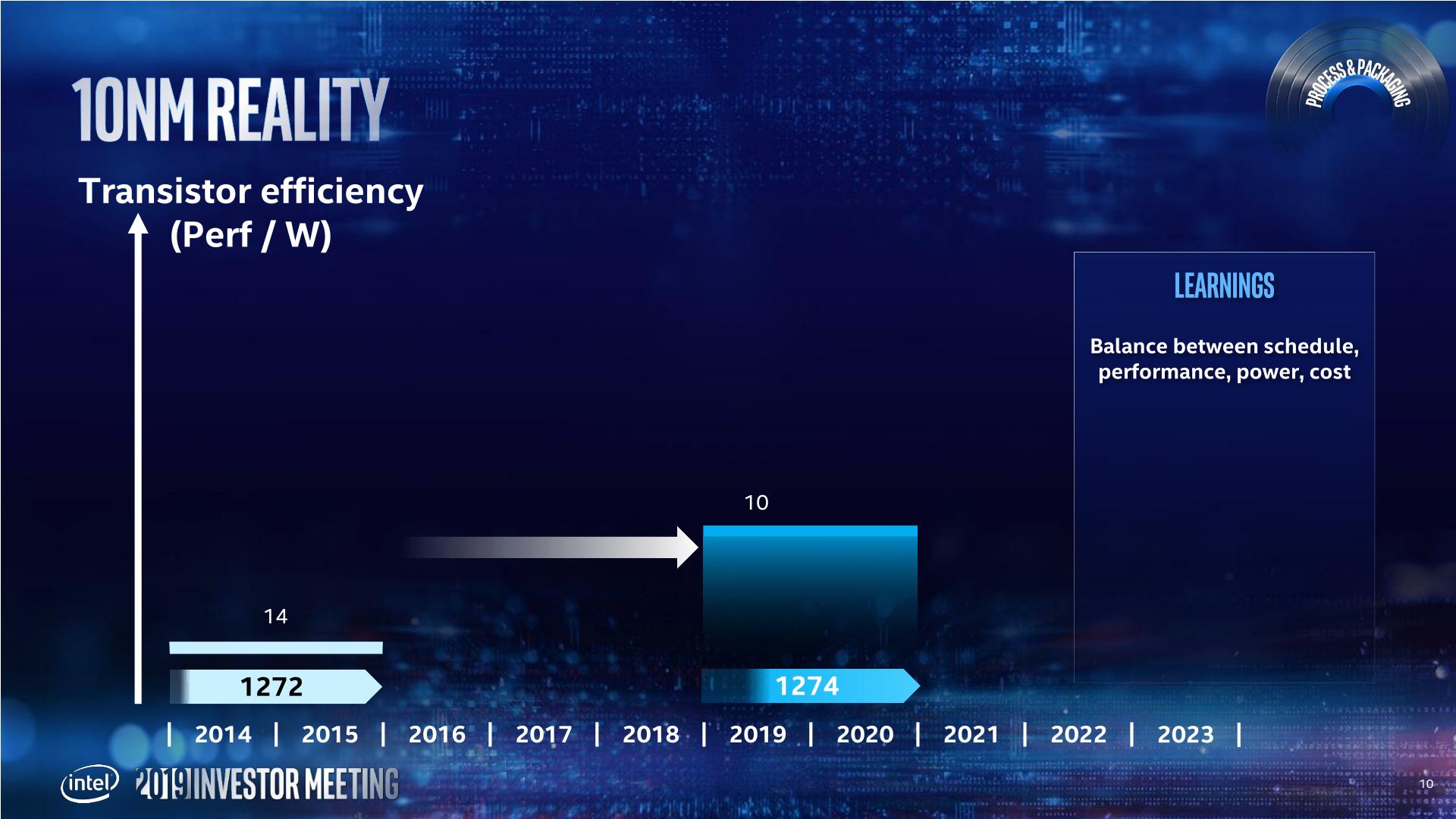
This ended up pushing 10nm out into a later time frame. In this case, Intel pushed 10nm out to 2019 (technically they shipped Cannon Lake in small quantities on 10nm in 2017, however that is nothing more than a curio in the timeline of semiconductors), and filled the gap with 14+ and 14++.
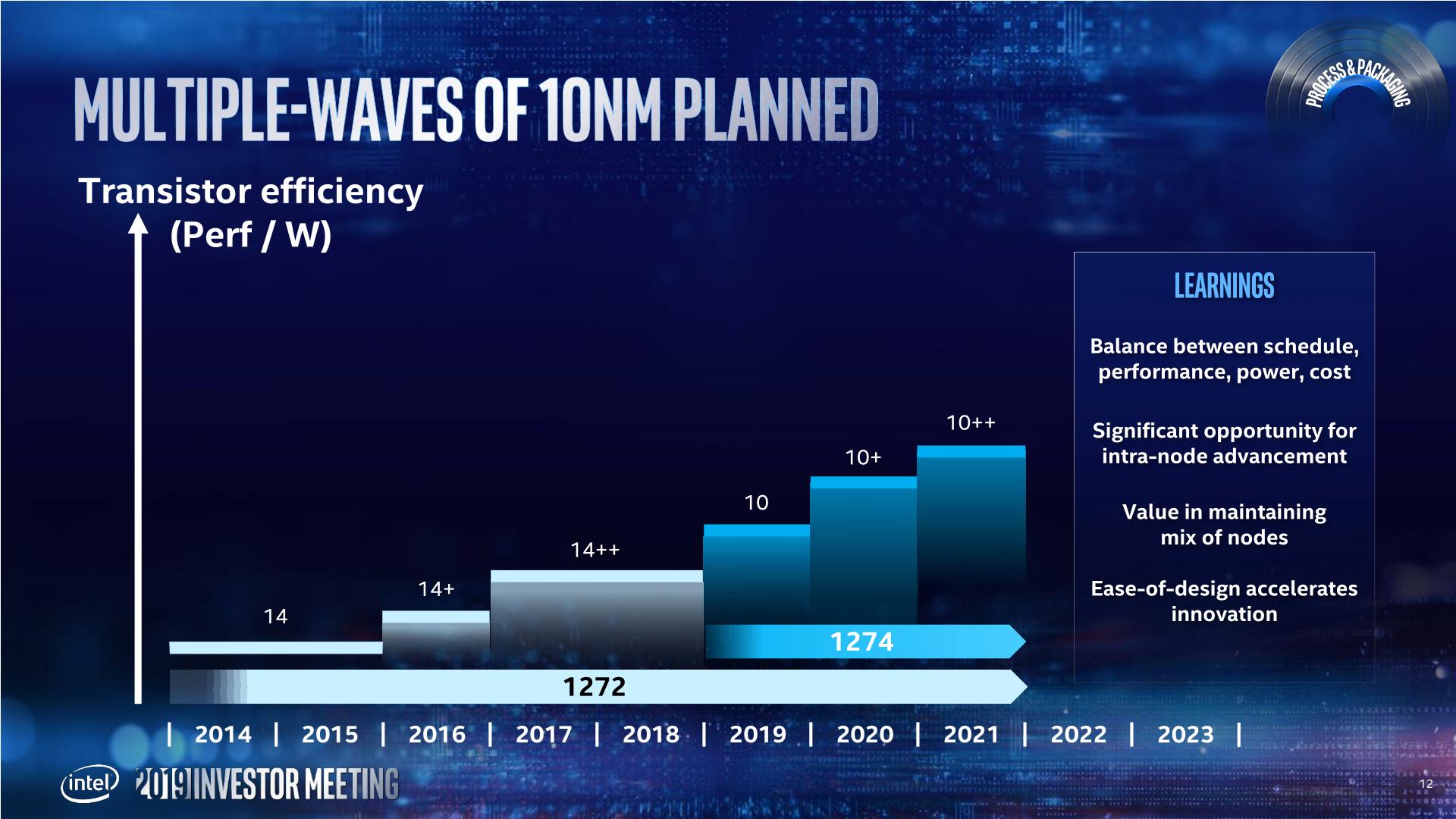
Intels 14+ and 14++ processes extracted more than 20% more performance (from Broadwell to Whiskey Lake) from the process since its inception. As a result, Intel is prepared to not only get ready for future intra-node optimizations, but actually adjust the roadmap to compensate for it. Murthy made it clear that Intel wants to introduce a Moore's Law-like gain at the beginning of a new process, and another similar gain by the end of the process.
Intel has stated that its 10nm product family (beyond Cannon Lake) will start to be available from the middle of this year (2019), with Ice Lake on client platforms (notebooks).

Intel will be launching multiple 10nm products through 2019 and 2020, including server based 10nm in the first half of 2020:

In the above slide, Intel states that it will have 7nm in production and launching a product in 2021. That sounds very aggressive for a company that has had issues with 10nm. It even shows in Intels radmap, with 10nm (and 10+ and 10++) having a much shorter life cycle than the 14nm family of processes.
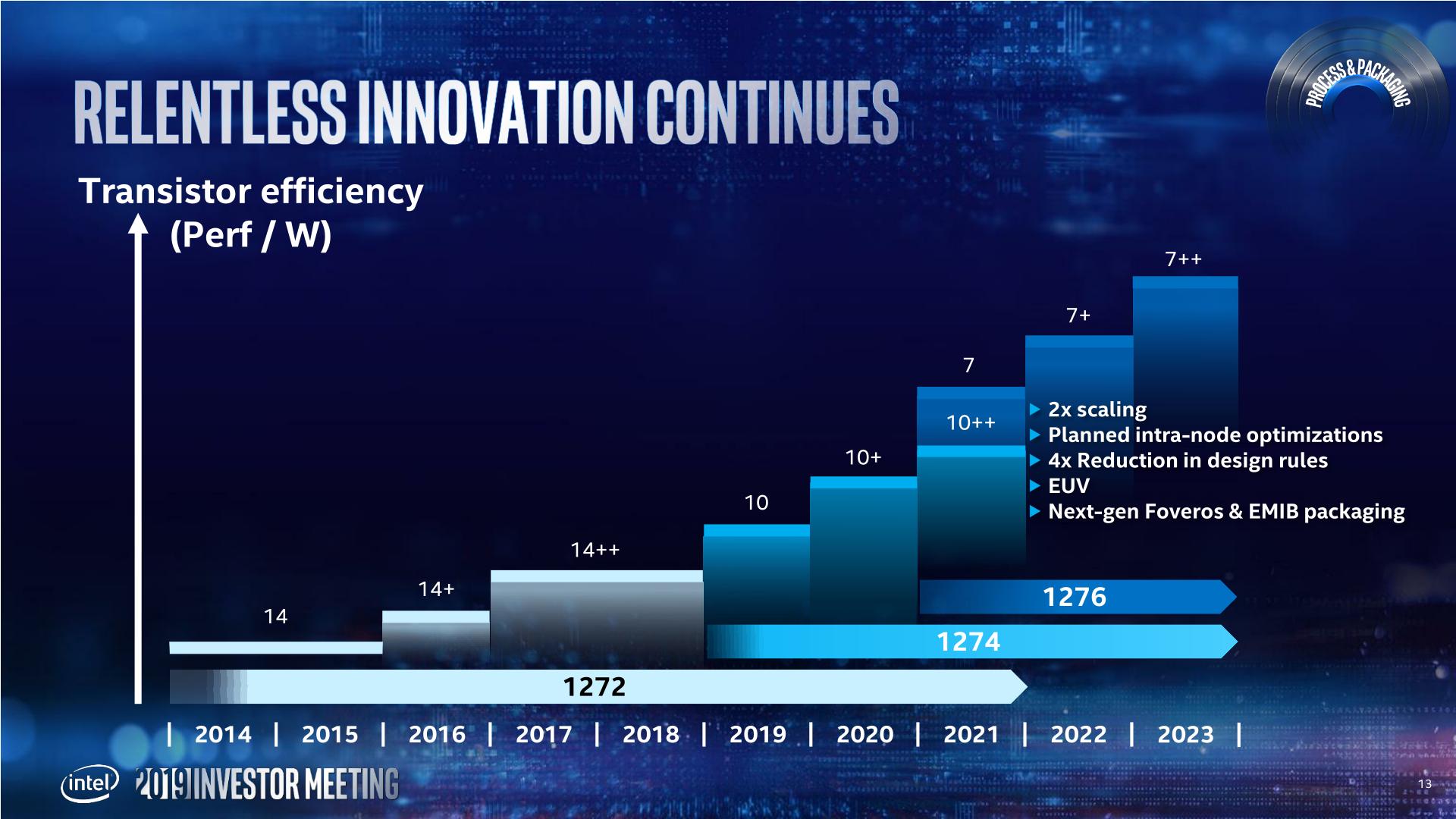
With this in mind, Intel's 7nm is going to be the combination of what Intel has learned from the 14nm and 10nm family of products. Intel wants that 2x scaling (Moores Law), but with intra-node optimations planned as part of the roadmap. Intel is also reducing its number of design rules, which should help with execution. 7nm will also be where Intel intersects with EUV, and also introduce next-gen Foveros and EMIB packainging.

Intel provided this slide, which shows a monolithic PC-Centric die with a multi-die Data-Centric chip built on both Foveros and EMIB. This corroborates our discussion with Intel's chiplet and packaging team, who also stated that we would see Foveros and EMIB on a combined product - specifically the GPU.

Intel announced that its lead 7nm product (lead = top, or lead = first?) would be its new GPGPU, built on the Xe graphics architecture. Intel has stated that its Xe product stack will feature two different microarchitectures from mobile client up to GPGPU, with one of those architectures called Arctic Sound - technically Intel will launch its first discrete GPU in 2020 according to its press release, however the 7nm GPGPU will be launched in 2021.
More information is coming out of Intel's Event, more to follow.
Related Reading
- Intel: EUV-Enabled 7nm Process Tech is on Track
- Intel Starts Qualification of Ice Lake CPUs, Raises 10nm Volume Expectation for 2019
- Intel Agilex: 10nm FPGAs with PCIe 5.0, DDR5, and CXL
- Intel to Equip Fab 42 for 7 nm
- Intel Discloses Plans to Spend $5 Billion on Fab 28 Expansion in Israel
- Intel Submits Ireland Fab Expansion Plan: $8 Billion Price Tag, With a 4 Year Lead Time
- Intel Details Plans for Its Oregon Fab Expansion: D1X Phase 3
- Intel to Expand Production Capacities at Multiple Fabs
Source: Intel








237 Comments
View All Comments
Butterfish - Saturday, May 11, 2019 - link
Centriq use Samsung’s 10nm LPE (Lower Power Early) process. It is basically made like a scale up mobile chip. And your claimed of Centriq has 3X the density of Intel is also false. According to another Anandtech article it was 45.2MTr/mm2 compared to 37.5MTr/mm2 on Intel’s 14nm Skylake XCC server chip.Wilco1 - Saturday, May 11, 2019 - link
Your 37.5 MT/mm^2 figure is the marketing density of the 14nm process, so that's not the correct figure to use for Skylake. Checkout https://en.wikipedia.org/wiki/Transistor_count for actual densities achieved in the real world, Skylake does barely 16MT/mm^2.10nm from Samsung and TSMC are fairly close, the same is true for 7nm EUV processes, so which is used does not matter much. Centriq beats Skylake on performance and has much higher base and sustained frequencies than Skylake. And yet you try to claim it's a mobile chip?
Butterfish - Saturday, May 11, 2019 - link
It use the same type of library as mobile process that is the point, and since Qualcomm abandon the project most performance figure found online are just their marketing materials which hardly prove it can do better than Intel in real world.If you want a high density Intel 14nm chip look for their Stratix 10 FPGA line. 17billion transistors in 560mm2, slightly over 30 MTr/mm2
blu42 - Monday, May 13, 2019 - link
@Butterfish Centriq uses 10LPE since it doesn't need anything else to achieve its 2.2/2.6GHz. What are the clocks of 48-core Cascade Lakes Xeons again (hint: if they're below, say, 3GHz will you consider them mobile chips?) And why does Centriq need to do *better* than Skylakes in order to be considered in the same category?Butterfish - Friday, May 24, 2019 - link
The turbo are 1.2Ghz lower though. And intel’s process node are proven to be able to clock at significantly higher clock by their consumer facing product. There is also no third party benchmark that confirmed Centriq’s advertised performance. Two CPU can be clock the same but performance quite differently. Also we are talking about process node tech not final chips. If you argue LPE has little impact on the performance of cheerypicked lower cloaked high core count server chip, so is density. Finally, I have proven intel does has high density library for 14nm that they use on their FPGA chip which debunk Wiloc1’s entire conspiracy theory which is what this thread really is about.Jorgp2 - Wednesday, May 8, 2019 - link
Transistors are measured differently based on who's counting them.HStewart - Wednesday, May 8, 2019 - link
So true and also the lower nm rating by one manufacture does not mean more transistor compare to another manufacture .Lord of the Bored - Friday, May 10, 2019 - link
Which doesn't change the fact that Intel is SUPER late with their process improvements.peevee - Thursday, May 9, 2019 - link
Sorry, transistors are transistors. But for what the marketoids industry did to nanometer, they all must sued for fraud. Too bad our FTC does not have any brains, only lawyers.ats - Thursday, May 9, 2019 - link
Not actually true. How you count transistors can vary widely because there are reasonable differences of opinion on how you should count fingered and parallel devices.