The AMD 2nd Gen Ryzen Deep Dive: The 2700X, 2700, 2600X, and 2600 Tested
by Ian Cutress on April 19, 2018 9:00 AM ESTTranslating to IPC: All This for 3%?
Contrary to popular belief, increasing IPC is difficult. Attempt to ensure that each execution port is fed every cycle requires having wide decoders, large out-of-order queues, fast caches, and the right execution port configuration. It might sound easy to pile it all on, however both physics and economics get in the way: the chip still has to be thermally efficient and it has to make money for the company. Every generational design update will go for what is called the ‘low-hanging fruit’: the identified changes that give the most gain for the smallest effort. Usually reducing cache latency is not always the easiest task, and for non-semiconductor engineers (myself included), it sounds like a lot of work for a small gain.
For our IPC testing, we use the following rules. Each CPU is allocated four cores, without extra threading, and power modes are disabled such that the cores run at a specific frequency only. The DRAM is set to what the processor supports, so in the case of the new CPUs, that is DDR4-2933, and the previous generation at DDR4-2666. I have recently seen threads which dispute if this is fair: this is an IPC test, not an instruction efficiency test. The DRAM official support is part of the hardware specifications, just as much as the size of the caches or the number of execution ports. Running the two CPUs at the same DRAM frequency gives an unfair advantage to one of them: either a bigger overclock/underclock, and deviates from the intended design.
So in our test, we take the new Ryzen 7 2700X, the first generation Ryzen 7 1800X, and the pre-Zen Bristol Ridge based A12-9800, which is based on the AM4 platform and uses DDR4. We set each processors at four cores, no multi-threading, and 3.0 GHz, then ran through some of our tests.
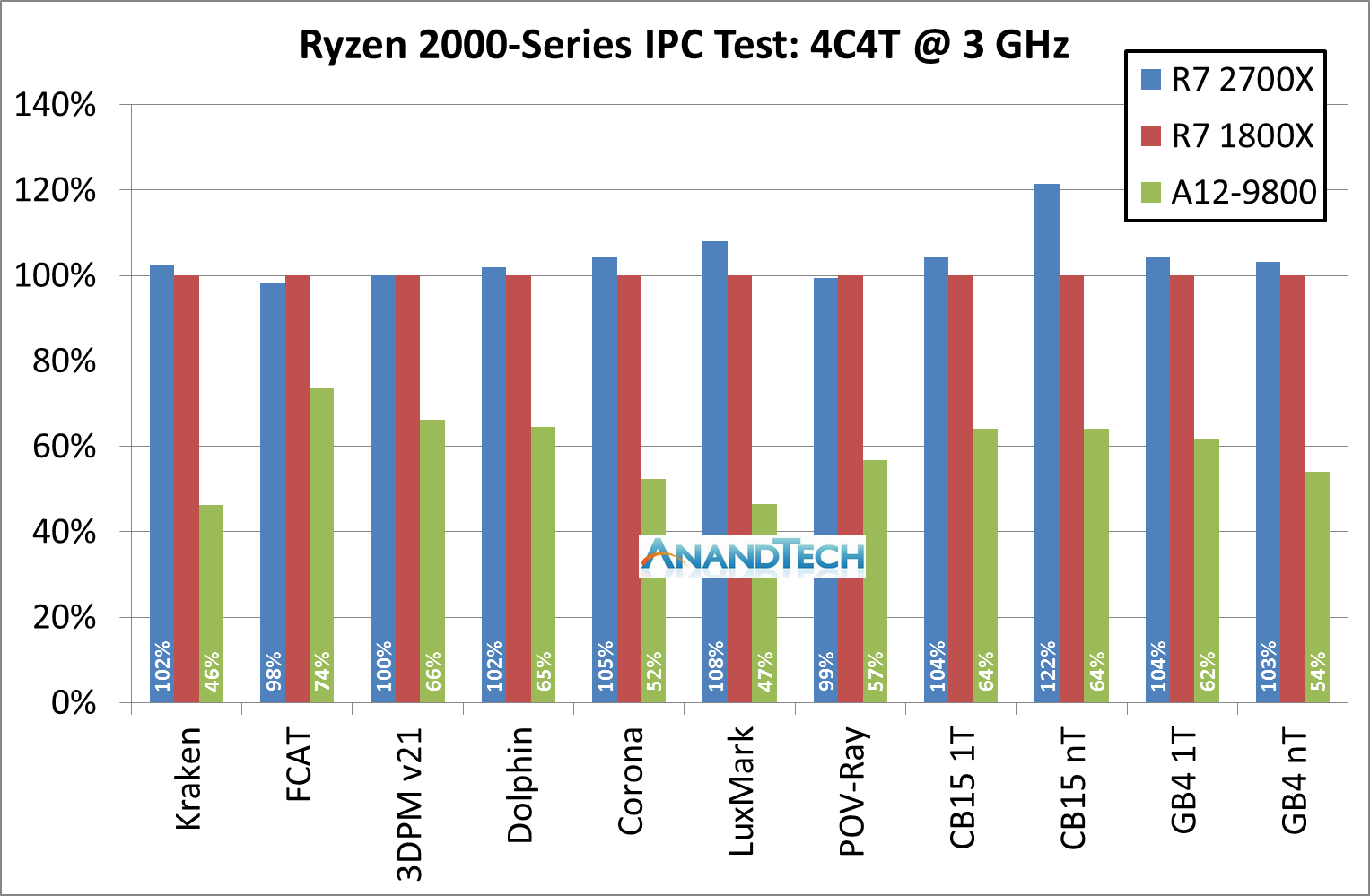
For this graph we have rooted the first generation Ryzen 7 1800X as our 100% marker, with the blue columns as the Ryzen 7 2700X. The problem with trying to identify a 3% IPC increase is that 3% could easily fall within the noise of a benchmark run: if the cache is not fully set before the run, it could encounter different performance. Shown above, a good number of tests fall in that +/- 2% range.
However, for compute heavy tasks, there are 3-4% benefits: Corona, LuxMark, CineBench and GeekBench are the ones here. We haven’t included the GeekBench sub-test results in the graph above, but most of those fall into the 2-5% category for gains.
If we take out Cinebench R15 nT result and the Geekbench memory tests, the average of all of the tests comes out to a +3.1% gain for the new Ryzen 2700X. That sounds bang on the money for what AMD stated it would do.
Cycling back to that Cinebench R15 nT result that showed a 22% gain. We also had some other IPC testing done at 3.0 GHz but with 8C/16T (which we couldn’t compare to Bristol Ridge), and a few other tests also showed 20%+ gains. This is probably a sign that AMD might have also adjusted how it manages its simultaneous multi-threading. This requires further testing.
AMD’s Overall 10% Increase
With some of the benefits of the 12LP manufacturing process, a few editors internally have questioned exactly why AMD hasn’t redesigned certain elements of the microarchitecture to take advantage. Ultimately it would appear that the ‘free’ frequency boost is worth just putting the same design in – as mentioned previously, the 12LP design is based on 14LPP with performance bump improvements. In the past it might not have been mentioned as a separate product line. So pushing through the same design is an easy win, allowing the teams to focus on the next major core redesign.
That all being said, AMD has previously already stated its intentions for the Zen+ core design – rolling back to CES at the beginning of the year, AMD stated that they wanted Zen+ and future products to go above and beyond the ‘industry standard’ of a 7-8% performance gain each year.
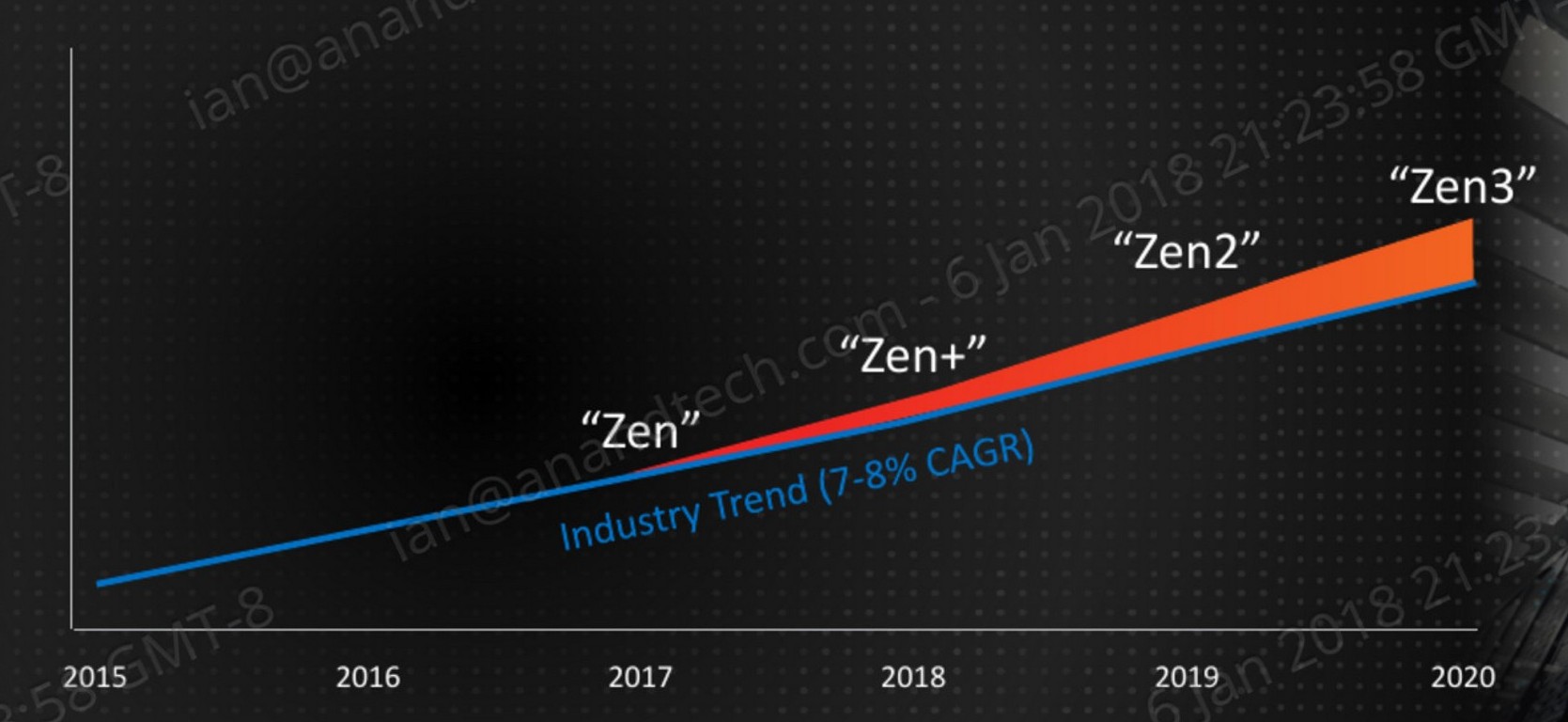
Clearly 3% IPC is not enough, so AMD is combining the performance gain with the +250 MHz increase, which is about another 6% peak frequency, with better turbo performance with Precision Boost 2 / XFR 2. This is about 10%, on paper at least. Benchmarks to follow.








545 Comments
View All Comments
fallaha56 - Sunday, April 22, 2018 - link
hey smart guy is that spectre1 or spectre2 patches...coburn_c - Sunday, April 22, 2018 - link
If you compare the 'web' numbers in Ian's Coffee Lake review to this article there is a huge performance drop across the board; both original Ryzen and Intel numbers. I think that rules out cooler performance as the source of the anomaly. Also, those numbers shouldn't really be affected by vulnerability patching. That article lists the same version of benchmarks, on the same browser, and they are not allowing it to update. Those tests should see limited affect from any updates due to spectre and meltdown if I am to believe what we are being told (I'm no programmer, I hated programming.)There is something to be explained here, but I've yet to hear any good theories.
coburn_c - Sunday, April 22, 2018 - link
Hmm.. Guru3D has the 2700x performing a 965ms on Kraken, in line with these numbers. Their 1700x in the graph shows 752ms, in line with the Coffee Lake review numbers. Either this new chip is much slower, or those are old numbers. Their Intel numbers are in line with the Coffee Lake review numbers as well. Most certainly old numbers. They make no comment on this aberration. Perhaps this is due to Microsoft patching.coburn_c - Sunday, April 22, 2018 - link
This is huge, a 20% loss in javascript interpreting? And these companies are saying minor performance impact? Please tell me this is a mistake.SaturnusDK - Sunday, April 22, 2018 - link
It's not a mistake. Anandtech uses the Windows 10 Enterprise edition vs. the Windows 10 Home or Pro most other reviewers. The Spectre/Meltdown mitigations on the Windows 10 Enterprise and Education versions are safer, and therefore incur a higher performance penalty.29a - Sunday, April 22, 2018 - link
Can you supply a source to backup your claim that Win 10 Enterprise and Education are getting different patches than Home and Pro?Th-z - Sunday, April 22, 2018 - link
If people at Anandtech can test Intel and AMD chips under Pro or Home, and it's been a while people compare numbers from different operating systems. According to Steam survey most people still use Windows 7.RafaelHerschel - Sunday, April 22, 2018 - link
People who get a new CPU / new system are likely to use Win 10. Anyway, if Enterprise behaves differently performance wise than Pro, then that is the real story. And AnandTech missed it.mapesdhs - Monday, April 23, 2018 - link
Though if true, then those here who've accused AT of deliberate deception should apologise.RafaelHerschel - Sunday, April 22, 2018 - link
There is a lot of speculation because AnandTech isn't able to provide a clarification in a timely matter. I'm going to avoid AnandTech from now on.If there is a specific reason for the strange results they got (other than AnandTech mucking things up), that would be an interesting story. A serious tech journalist would have realized that right away.
The gaming benchmarks are disappointing anyway, since the scope of the gaming test is very limited.
And right now I don't care that much about the productivity test since an 8-core Ryzen is obviously going to outperform an 6-core Intel i7 with optimized software.