The AMD 2nd Gen Ryzen Deep Dive: The 2700X, 2700, 2600X, and 2600 Tested
by Ian Cutress on April 19, 2018 9:00 AM ESTImprovements to the Cache Hierarchy
The biggest under-the-hood change for the Ryzen 2000-series processors is in the cache latency. AMD is claiming that they were able to knock one-cycle from L1 and L2 caches, several cycles from L3, and better DRAM performance. Because pure core IPC is intimately intertwined with the caches (the size, the latency, the bandwidth), these new numbers are leading AMD to claim that these new processors can offer a +3% IPC gain over the previous generation.

The numbers AMD gives are:
- 13% Better L1 Latency (1.10ns vs 0.95ns)
- 34% Better L2 Latency (4.6ns vs 3.0ns)
- 16% Better L3 Latency (11.0ns vs 9.2ns)
- 11% Better Memory Latency (74ns vs 66ns at DDR4-3200)
- Increased DRAM Frequency Support (DDR4-2666 vs DDR4-2933)
It is interesting that in the official slide deck AMD quotes latency measured as time, although in private conversations in our briefing it was discussed in terms of clock cycles. Ultimately latency measured as time can take advantage of other internal enhancements; however a pure engineer prefers to discuss clock cycles.
Naturally we went ahead to test the two aspects of this equation: are the cache metrics actually lower, and do we get an IPC uplift?
Cache Me Ousside, How Bow Dah?
For our testing, we use a memory latency checker over the stride range of the cache hierarchy of a single core. For this test we used the following:
- Ryzen 7 2700X (Zen+)
- Ryzen 5 2400G (Zen APU)
- Ryzen 7 1800X (Zen)
- Intel Core i7-8700K (Coffee Lake)
- Intel Core i7-7700K (Kaby Lake)
The most obvious comparison is between the AMD processors. Here we have the Ryzen 7 1800X from the initial launch, the Ryzen 5 2400G APU that pairs Zen cores with Vega graphics, and the new Ryzen 7 2700X processor.
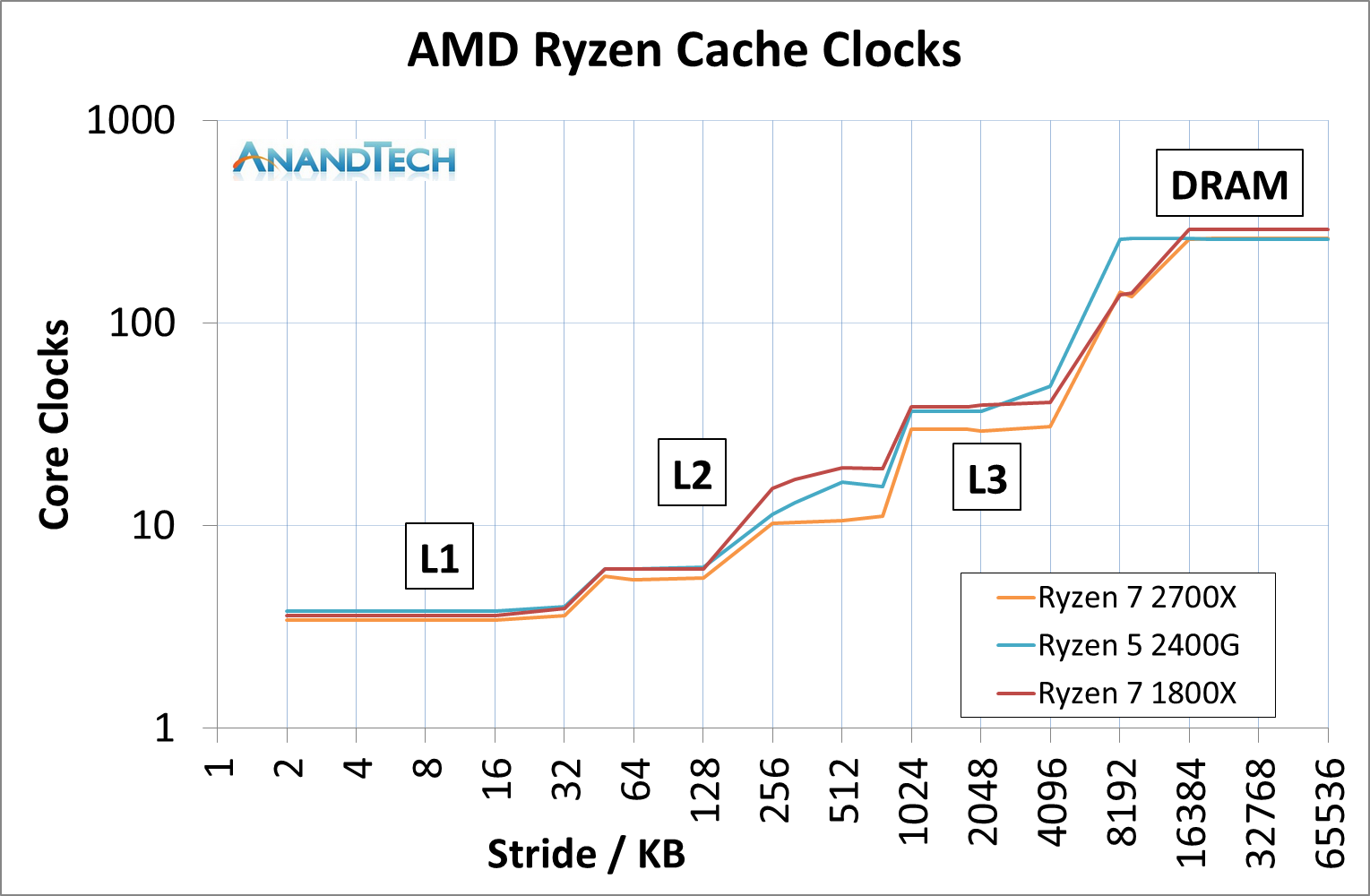
This graph is logarithmic in both axes.
This graph shows that in every phase of the cache design, the newest Ryzen 7 2700X requires fewer core clocks. The biggest difference is on the L2 cache latency, but L3 has a sizeable gain as well. The reason that the L2 gain is so large, especially between the 1800X and 2700X, is an interesting story.
When AMD first launched the Ryzen 7 1800X, the L2 latency was tested and listed at 17 clocks. This was a little high – it turns out that the engineers had intended for the L2 latency to be 12 clocks initially, but run out of time to tune the firmware and layout before sending the design off to be manufactured, leaving 17 cycles as the best compromise based on what the design was capable of and did not cause issues. With Threadripper and the Ryzen APUs, AMD tweaked the design enough to hit an L2 latency of 12 cycles, which was not specifically promoted at the time despite the benefits it provides. Now with the Ryzen 2000-series, AMD has reduced it down further to 11 cycles. We were told that this was due to both the new manufacturing process but also additional tweaks made to ensure signal coherency. In our testing, we actually saw an average L2 latency of 10.4 cycles, down from 16.9 cycles in on the Ryzen 7 1800X.
The L3 difference is a little unexpected: AMD stated a 16% better latency: 11.0 ns to 9.2 ns. We saw a change from 10.7 ns to 8.1 ns, which was a drop from 39 cycles to 30 cycles.
Of course, we could not go without comparing AMD to Intel. This is where it got very interesting. Now the cache configurations between the Ryzen 7 2700X and Core i7-8700K are different:
| CPU Cache uArch Comparison | ||
| AMD Zen (Ryzen 1000) Zen+ (Ryzen 2000) |
Intel Kaby Lake (Core 7000) Coffee Lake (Core 8000) |
|
| L1-I Size | 64 KB/core | 32 KB/core |
| L1-I Assoc | 4-way | 8-way |
| L1-D Size | 32 KB/core | 32 KB/core |
| L1-D Assoc | 8-way | 8-way |
| L2 Size | 512 KB/core | 256 KB/core |
| L2 Assoc | 8-way | 4-way |
| L3 Size | 8 MB/CCX (2 MB/core) |
2 MB/core |
| L3 Assoc | 16-way | 16-way |
| L3 Type | Victim | Write-back |
AMD has a larger L2 cache, however the AMD L3 cache is a non-inclusive victim cache, which means it cannot be pre-fetched into unlike the Intel L3 cache.
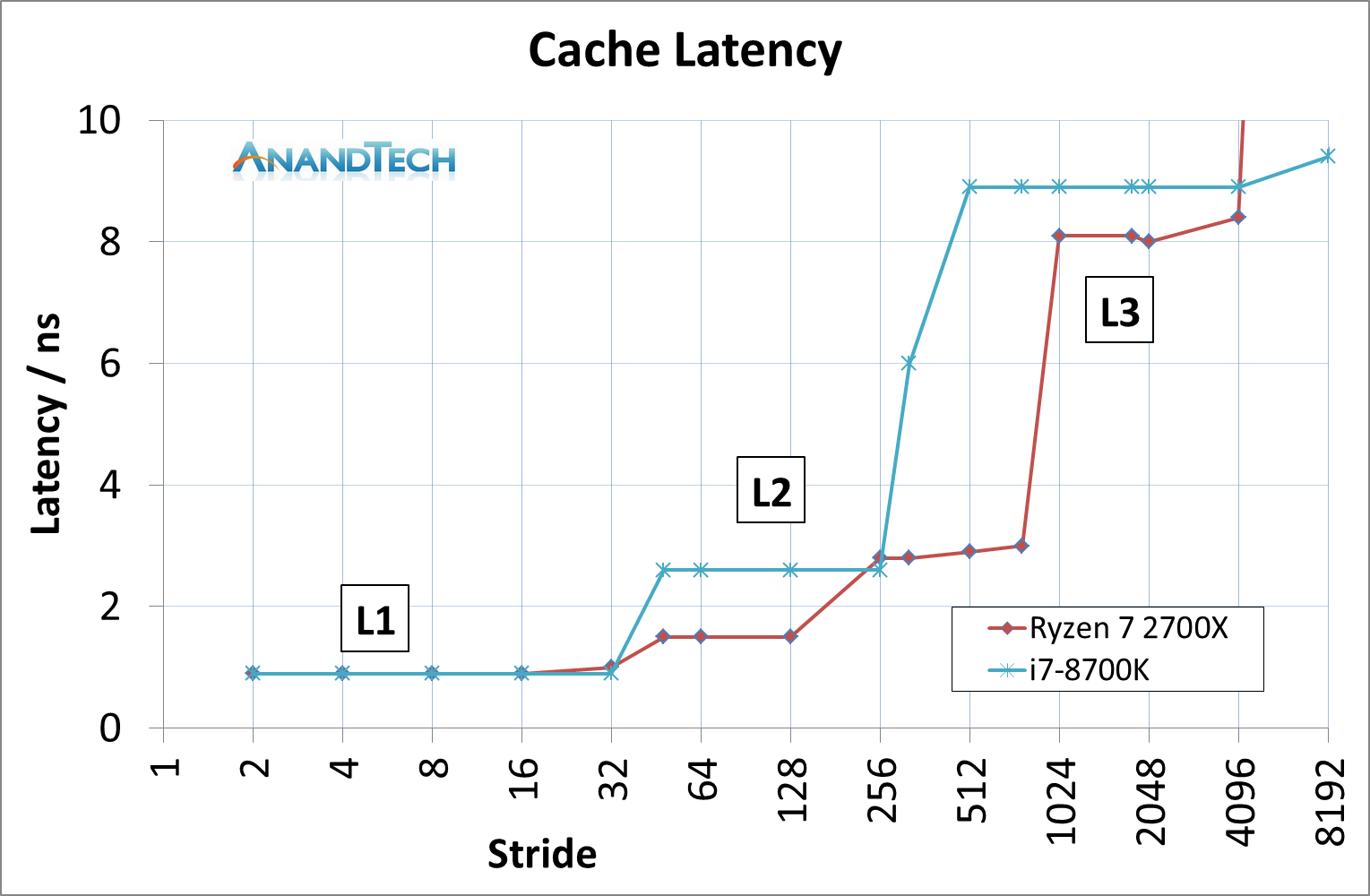
This was an unexpected result, but we can see clearly that AMD has a latency timing advantage across the L2 and L3 caches. There is a sizable difference in DRAM, however the core performance metrics are here in the lower caches.
We can expand this out to include the three AMD chips, as well as Intel’s Coffee Lake and Kaby Lake cores.

This is a graph using cycles rather than timing latency: Intel has a small L1 advantage, however the larger L2 caches in AMD’s Zen designs mean that Intel has to hit the higher latency L3 earlier. Intel makes quick work of DRAM cycle latency however.








545 Comments
View All Comments
fallaha56 - Sunday, April 22, 2018 - link
hey smart guy is that spectre1 or spectre2 patches...coburn_c - Sunday, April 22, 2018 - link
If you compare the 'web' numbers in Ian's Coffee Lake review to this article there is a huge performance drop across the board; both original Ryzen and Intel numbers. I think that rules out cooler performance as the source of the anomaly. Also, those numbers shouldn't really be affected by vulnerability patching. That article lists the same version of benchmarks, on the same browser, and they are not allowing it to update. Those tests should see limited affect from any updates due to spectre and meltdown if I am to believe what we are being told (I'm no programmer, I hated programming.)There is something to be explained here, but I've yet to hear any good theories.
coburn_c - Sunday, April 22, 2018 - link
Hmm.. Guru3D has the 2700x performing a 965ms on Kraken, in line with these numbers. Their 1700x in the graph shows 752ms, in line with the Coffee Lake review numbers. Either this new chip is much slower, or those are old numbers. Their Intel numbers are in line with the Coffee Lake review numbers as well. Most certainly old numbers. They make no comment on this aberration. Perhaps this is due to Microsoft patching.coburn_c - Sunday, April 22, 2018 - link
This is huge, a 20% loss in javascript interpreting? And these companies are saying minor performance impact? Please tell me this is a mistake.SaturnusDK - Sunday, April 22, 2018 - link
It's not a mistake. Anandtech uses the Windows 10 Enterprise edition vs. the Windows 10 Home or Pro most other reviewers. The Spectre/Meltdown mitigations on the Windows 10 Enterprise and Education versions are safer, and therefore incur a higher performance penalty.29a - Sunday, April 22, 2018 - link
Can you supply a source to backup your claim that Win 10 Enterprise and Education are getting different patches than Home and Pro?Th-z - Sunday, April 22, 2018 - link
If people at Anandtech can test Intel and AMD chips under Pro or Home, and it's been a while people compare numbers from different operating systems. According to Steam survey most people still use Windows 7.RafaelHerschel - Sunday, April 22, 2018 - link
People who get a new CPU / new system are likely to use Win 10. Anyway, if Enterprise behaves differently performance wise than Pro, then that is the real story. And AnandTech missed it.mapesdhs - Monday, April 23, 2018 - link
Though if true, then those here who've accused AT of deliberate deception should apologise.RafaelHerschel - Sunday, April 22, 2018 - link
There is a lot of speculation because AnandTech isn't able to provide a clarification in a timely matter. I'm going to avoid AnandTech from now on.If there is a specific reason for the strange results they got (other than AnandTech mucking things up), that would be an interesting story. A serious tech journalist would have realized that right away.
The gaming benchmarks are disappointing anyway, since the scope of the gaming test is very limited.
And right now I don't care that much about the productivity test since an 8-core Ryzen is obviously going to outperform an 6-core Intel i7 with optimized software.