NVIDIA’s DGX-2: Sixteen Tesla V100s, 30 TB of NVMe, only $400K
by Ian Cutress on March 27, 2018 2:00 PM EST
Ever wondered why the consumer GPU market is not getting much love from NVIDIA’s Volta architecture yet? This is a minefield of a question, nuanced by many different viewpoints and angles – even asking the question will poke the proverbial hornet nest inside my own mind of different possibilities. Here is one angle to consider: NVIDIA is currently loving the data center, and the deep learning market, and making money hand-over-fist. The Volta architecture, with CUDA Tensor cores, is unleashing high performance to these markets, and the customers are willing to pay for it. So introduce the latest monster from NVIDIA: the DGX-2.

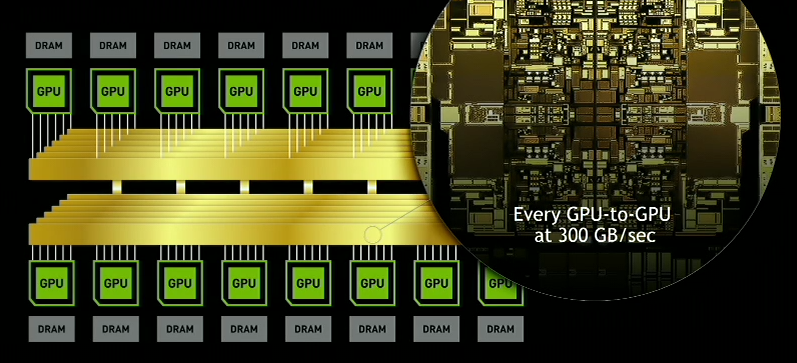
DGX-2 builds upon DGX-1 in several ways. Firstly, it introduces NVIDIA’s new NVSwitch, enabling 300 GB/s chip-to-chip communication at 12 times the speed of PCIe. This, with NVLink2, enables sixteen GPUs to be grouped together in a single system, for a total bandwidth going beyond 14 TB/s. Add in a pair of Xeon CPUs, 1.5 TB of memory, and 30 TB of NVMe storage, and we get a system that consumes 10 kW, weighs 350 lbs, but offers easily double the performance of the DGX-1. NVIDIA likes to tout that this means it offers a total of ~2 PFLOPs of compute performance in a single system, when using the tensor cores.
| NVIDIA DGX Series (with Volta) | ||
| DGX-2 | DGX-1 | |
| CPUs | 2 x Intel Xeon Platinum |
2 x Intel Xeon E5-2600 v4 |
| GPUs | 16 x NVIDIA Tesla V100 32GB HBM2 |
8 x NVIDIA Tesla V100 16 GB HBM2 |
| System Memory | Up to 1.5 TB DDR4 | Up to 0.5 TB DDR4 |
| GPU Memory | 512 GB HBM2 (16 x 32 GB) |
256 GB HBM (8 x 32 GB) |
| Storage | 30 TB NVMe Up to 60 TB |
4 x 1.92 TB NVMe |
| Networking | 8 x Infiniband or 8 x 100 GbE |
4 x IB + 2 x 10 GbE |
| Power | 10 kW | 3.5 kW |
| Size | 350 lbs | 134 lbs |
| GPU Throughput | Tensor: 1920 TFLOPs FP16: 480 TFLOPs FP32: 240 TFLOPs FP64: 120 TFLOPs |
Tensor: 960 TFLOPs FP16: 240 TFLOPs FP32: 120 TFLOPs FP64: 60 TFLOPs |
| Cost | $399,000 | $149,000 |
NVIDIA’s overall topology relies on a dual stacked system. The high level concept photo provided indicates that there are actually 12 NVSwitches (216 ports) in the system in order to maximize the amount of bandwidth available between the GPUs. With 6 ports per Tesla V100 GPU, each running in the larger 32GB of HBM2 configuration, this means that the Teslas alone would be taking up 96 of those ports if NVIDIA has them fully wired up to maximize individual GPU bandwidth within the topology.
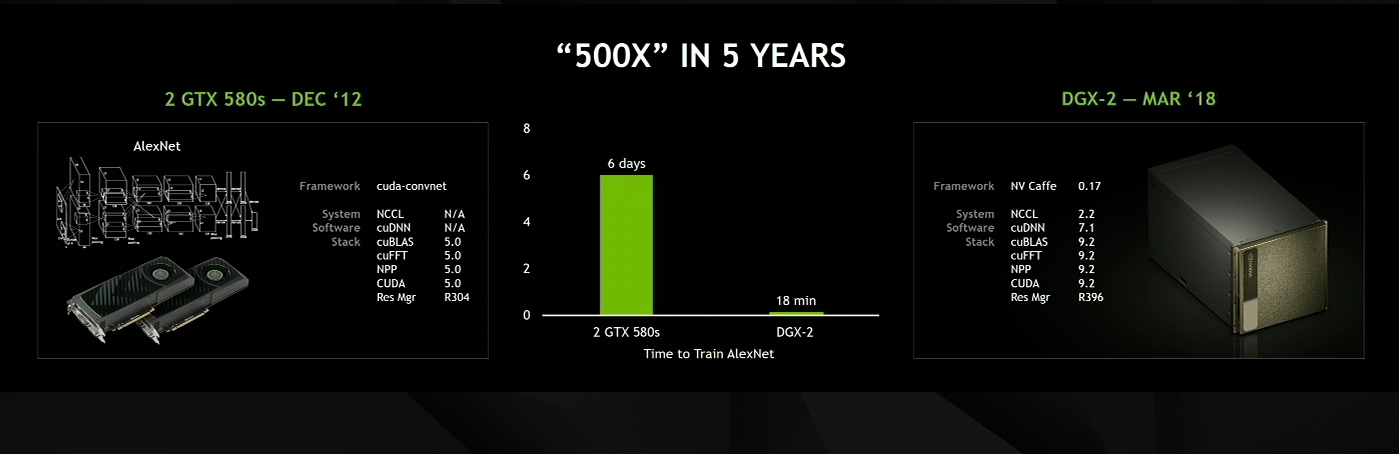
AlexNET, the network that 'started' the latest machine learning revolution, now takes 18 minutes
Notably here, the topology of the DGX-2 means that all 16 GPUs are able to pool their memory into a unified memory space, though with the usual tradeoffs involved if going off-chip. Not unlike the Tesla V100 memory capacity increase then, one of NVIDIA’s goals here is to build a system that can keep in-memory workloads that would be too large for an 8 GPU cluster. Providing one such example, NVIDIA is saying that the DGX-2 is able to complete the training process for FAIRSEQ – a neural network model for language translation – 10x faster than a DGX-1 system, bringing it down to less than two days total rather than 15.
Otherwise, similar to its DGX-1 counterpart, the DGX-2 is designed to be a powerful server in its own right. Exact specifications are still TBD, but NVIDIA has already told us that it’s based around a pair of Xeon Platinum CPUs, which in turn can be paired with up to 1.5TB of RAM. On the storage side the DGX-2 comes with 30TB of NVMe-based solid state storage, which can be further expanded to 60TB. And for clustering or further inter-system communications, it also offers InfiniBand and 100GigE connectivity, up to eight of them.
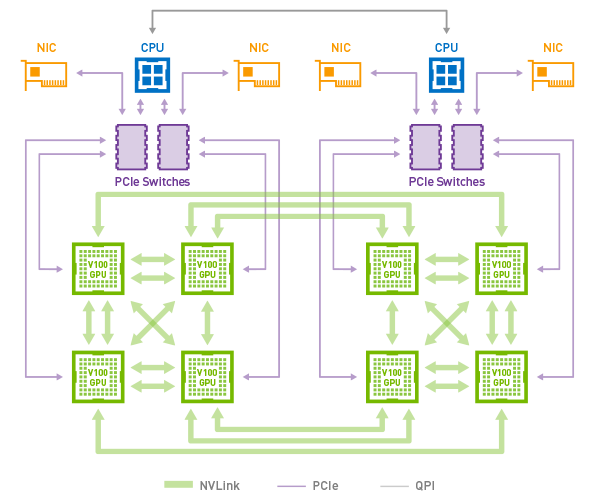
The new NVSwitches means that the PCIe lanes of the CPUs can be redirected elsewhere, most notably towards storage and networking connectivity.
Ultimately the DGX-2 is being pitched at an even higher-end segment of the deep-learning market than the DGX-1 is. Pricing for the system runs at $400k, rather than the $150k for the original DGX-1. For more than double the money, the user gets Xeon Platinums (rather than v4), double the V100 GPUs each with double the HBM2, triple the DRAM, and 15x the NVMe storage by default.
NVIDIA has stated that DGX-2 is already certified for the major cloud providers.
Related Reading
- Big Volta Comes to Quadro: NVIDIA Announces Quadro GV100
- The NVIDIA GTC 2018 Keynote Live Blog
- NVIDIA Develops NVLink Switch: NVSwitch, 18 Ports For DGX-2 & More
- NVIDIA Volta Unveiled: GV100 GPU and Tesla V100 Accelerator Announced
- NVIDIA Ships First Volta-based DGX Systems
- NVIDIA Unveils the DGX-1 HPC Server: 8 Teslas, 3U, Q2 2016








28 Comments
View All Comments
o0rainmaker0o - Tuesday, June 19, 2018 - link
IBM doesn't use the PCI bus for GPU-GPU links (it has PCIe4 available for other uses however). Bandwidth for GPU-GPU (and CPU-GPU) communications is 300GB/s, same as DGX-2 above. The difference is all 16 GPUs (4xV100 for air-cooled servers) in the IBM box enjoy that bandwidth, not just the 4 GPUs on each V100 card (because they are attached to a PCIe bus in regular x86 servers). IBM has another advantage -- the memory can be extended to system RAM (max of 2TB per server). IBM is not limited to "just" 16GB or 32GB per card. GPU bandwidth and memory sizing are really important for scaling GPU jobs past a few V100 cards. IBM's Distributed Deep Learning library, for example, has already been shown to scale to 512 GPUs in a cluster-like design.Kvaern1 - Tuesday, March 27, 2018 - link
Well, don't call gamers useless. Footing the research bill for supercomputers, self driving cars and whatnot since AMD went defunct.StrangerGuy - Tuesday, March 27, 2018 - link
All NV needs to do is sell one DGX-2 and it would made more profit than all of Vega combined.Yojimbo - Tuesday, March 27, 2018 - link
First of all, NVIDIA started investing in GPU compute when AMD was at its peak. Second of all, NVIDIA's data center business is profitable, highly profitable, in fact.The major part gaming plays is that it gives NVIDIA economy of scale when designing and producing the chips.
Yojimbo - Tuesday, March 27, 2018 - link
It's also worth mentioning that gaming also benefits from NVIDIA's AI efforts. Without AI there would probably be no denoising solution for real time ray tracing, or at least it would run a lot more slowly because there would be no tensor cores and no work on TensorRT.Santoval - Friday, March 30, 2018 - link
When did real time ray tracing actually become a thing? I heard about the recently announced ray tracing extensions to the DirectX 12 and Vulcan APIs, but is this something that makes sense (performance/FPS wise) for the current generation of GPUs or do they just prepare for the next one?If we are talking about the current one which GPU card would be powerful enough to fully ray trace a game at 30+ fps? Would the 1080Ti be powerful enough, even at 1080p (higher resolutions must be out of the question)? Or are they just talking about "ray tracing effects" with perhaps 15 - 20% of each scene ray traced and the rest of it rasterized?
jbo5112 - Monday, April 23, 2018 - link
Pixar's Renderman software has been used by pretty much every winner of a Best Visual Effect Oscar, and the software itself even won a lifetime achievement Academy Award. The Renderman software did not support ray tracing until Pixar made the movie Cars (2006) because it was too computationally expensive for movies. However computational speed has been ramping up quickly.Real time ray tracing started in 2005 with a SIGGRAPH demo. In 2008 Intel did a 15-30 fps demo of Enemy Territory: Quake Wars using real time ray tracing on a 16 core, ~3GHz machine. This was their third attempt, but I couldn't find any info on the first two. They did a 40-80 fps demo in 2010 of the 2009 title Wolfenstein, but they had to use a cluster of 4 computers, each with a Knights Ferry card. For comparison, a single V100 chip is 5x as powerful as the entire cluster, and that's not counting the Tensor cores.
While ray tracing is currently much slower, it scales better with more complex scenes. GPU acceleration has also taken off. NVIDIA is now starting to push the idea of using real time ray tracing for some effects on their Volta chips (NVIDIA RTX Technology).
WorldWithoutMadness - Wednesday, March 28, 2018 - link
will someone use it for mining?steve wilson - Wednesday, March 28, 2018 - link
Correct me if I'm wrong, but isn't it cheaper to run 2 DGX-1's and get the same compute power? Also it uses less power. $399,000.00 vs $298,000.00 and 10KW vs 7KW.A5 - Wednesday, March 28, 2018 - link
For the people buying these, density is just as important as those other factors. Like they have a certain amount of rack space dedicated to DGX units, and now they can get double the GPU performance (along with more RAM/CPU/Storage) in the same space as before.