Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
The VISC Instruction Set and Global Front End
Common instruction set architectures (ISAs) such as x86, ARMv8, Power, SPARC and other more esoteric ones rely on system code converting into predefined instructions that each design can handle. VISC comes with its own ISA as well, separate from the others, which VISC cores and virtual cores use. When using native VISC code, the global front end will split the instructions into smaller ‘virtual hardware threadlets’ which are then dispatched to separate virtual cores. These virtual cores can then issue them to the available resources on any of the physical cores and keep track of where the data goes. Multiple virtual cores can push threadlets into the reorder buffer of a single physical core, which can split partial instructions and data from multiple threadlets through the execution ports at the same time. We were told that each ‘virtual core’ keeps track of the position of the relative output.
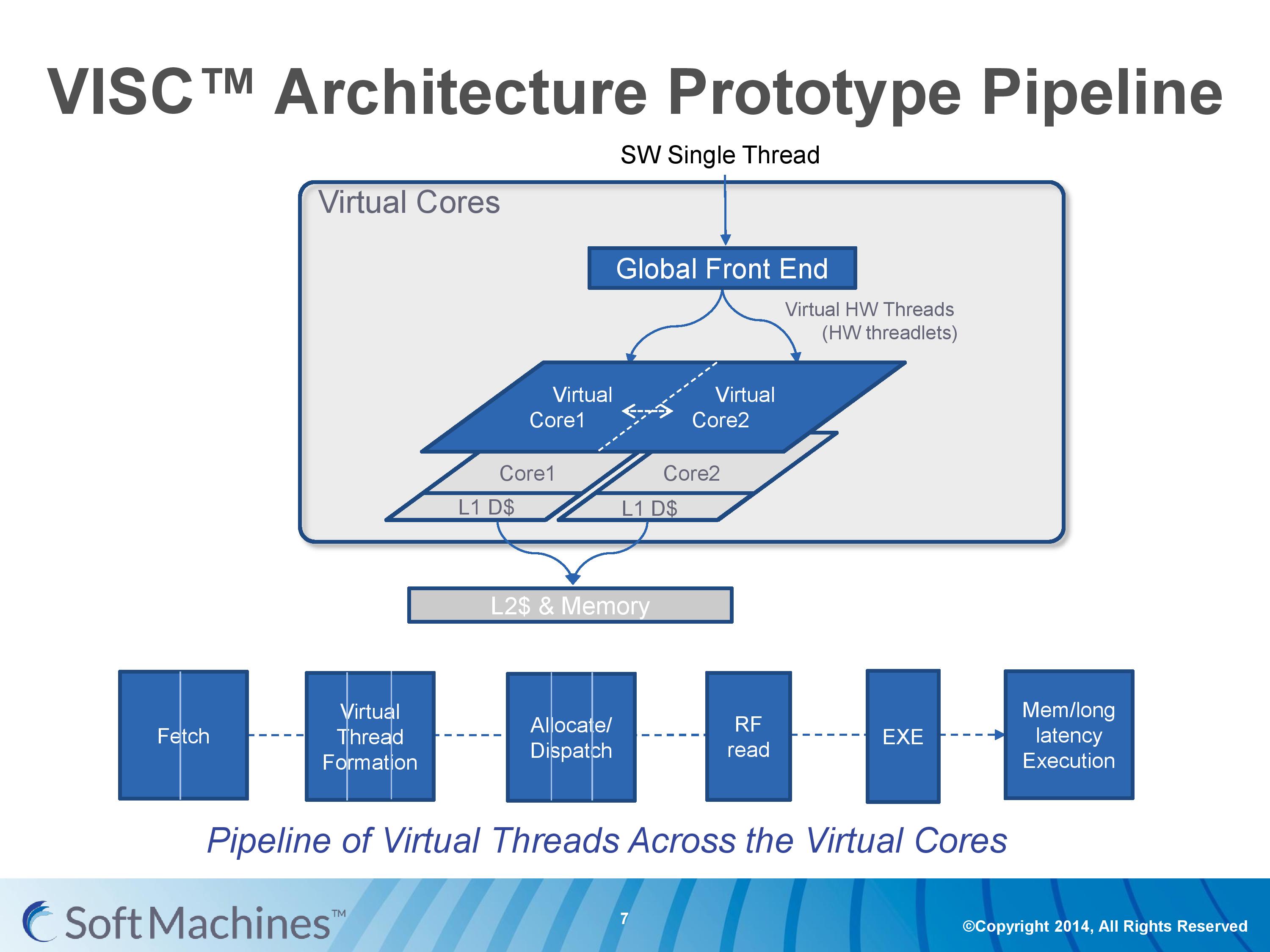
The true kicker (and so much of what sets VISC apart) is that when multiple virtual cores are in flight at one time, the core design allows the virtual core allocation of resources to be dynamic on a near-single cycle latency level (we were told from 1-4 cycles depending on the change in allocation). Thus if two virtual cores are competing for resources, there are appropriate algorithms in place to determine what resources are allocated where.
One big area of focus in optimizing processor designs for single-thread performance is speculation – being able to deal with branches in code and/or prefetch relevant data from memory when needed. Typically when speculation occurs, as the data for a single thread is contained within a core, it is easy enough to deal with code paths that rely on previous data or end up with bad speculation.
In the virtual core scenario however this becomes trickier. VISC tackles this in two ways – firstly, the threadlet generation is designed to minimize cross-core communication because this adds latency and reduces performance. Second, each core can communicate through either the register file or the L1 data caches. The register files have a single cycle latency for data but can only transmit tens of values, whereas the L1 cache has a 4-cycle latency but can transmit thousands of values.
Typically communicating through a register file is seen as a risky maneuver and difficult to control, especially when you have multiple physical cores and each core needs each other core to be able to place/take data into the right registers. Soft Machines told us that a large part of their design work has been in this area of speculation and data transfer. Specifically on speculation and branch prediction, we postulated that they were over ten years behind Intel in this, and the response we got was in a similar vein, stating that using Intel’s branch prediction methods could offer at least 20-30% better performance with branching code. However, we were told that the VISC design is quicker to recover in the event of a failed branch, needing only a few cycles.
The Pipeline
The first VISC core available for license is Shasta, a dual core part that enables up to two virtual cores or threads (2C/2VC), and we were given a base overview of the pipeline.
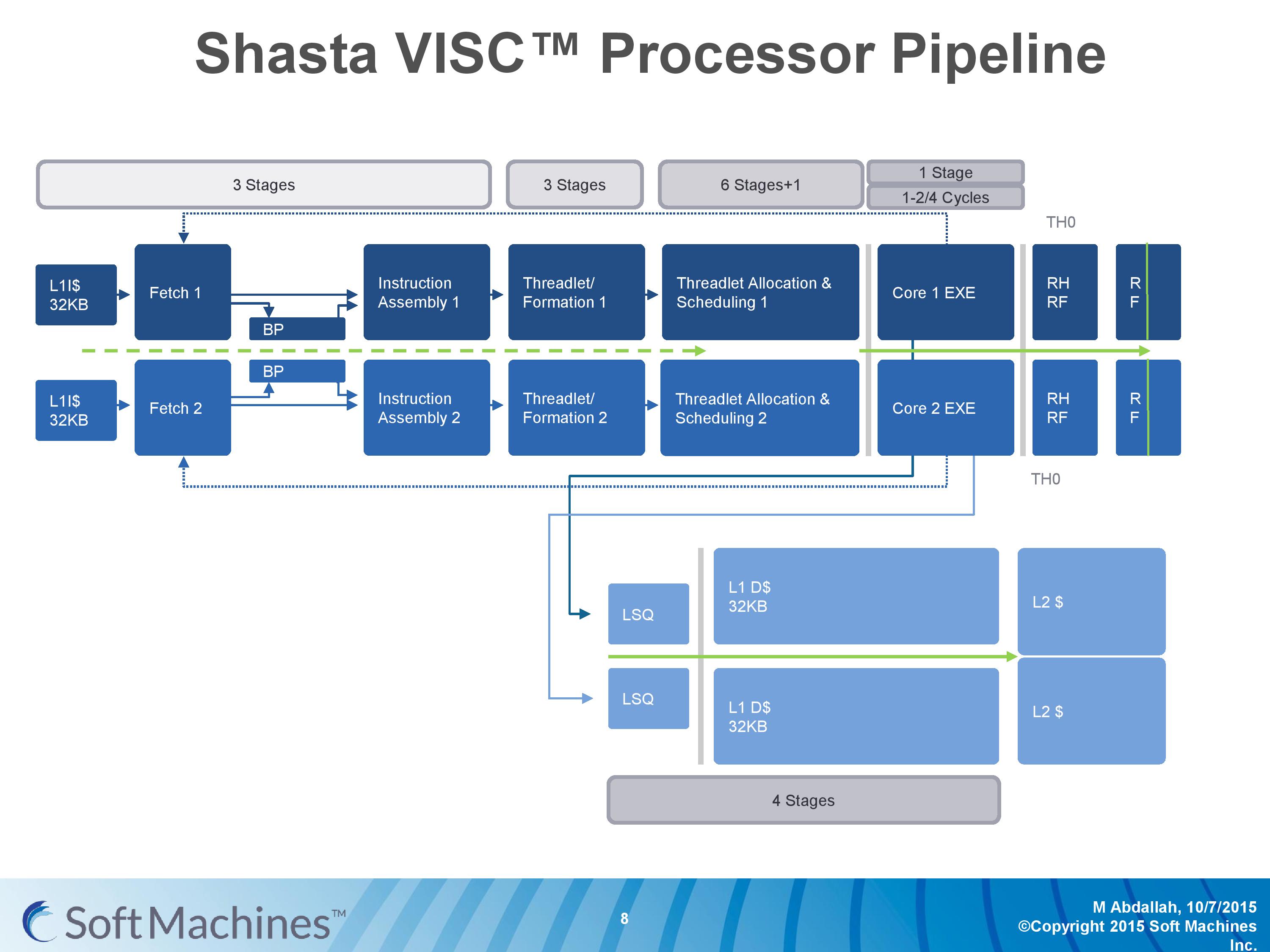
Normally we would see a pipeline of one core but this is a pipeline of both cores of Shasta. This pipeline, compared to the original VISC prototype, is also deeper. The pipeline looks relatively normal to others to start, where the thread either takes an instruction or issues a fetch for data into the instruction assembly. Making the VISC instructions and data into threadlets takes another three stages, but the allocation and scheduling takes six (plus one). On that subject, Soft Machines mentioned that keeping track of data across multiple cores per virtual core is tricky, as well as dealing with reorder buffers and parallel instruction management, that’s why there are a large amount of stages here. The plus one goes back to variable physical core allocation methodology, ensuring that if there are two threads active that the heavier one will get the most resources. The threadlets are then executed on the ports of each core, with a possible 1-4 cycle delay if data needs to be transferred across the core boundaries via registers or L1 cache.
With the variable allocation of fractions of a core to a virtual core, VISC is designed for this situation:
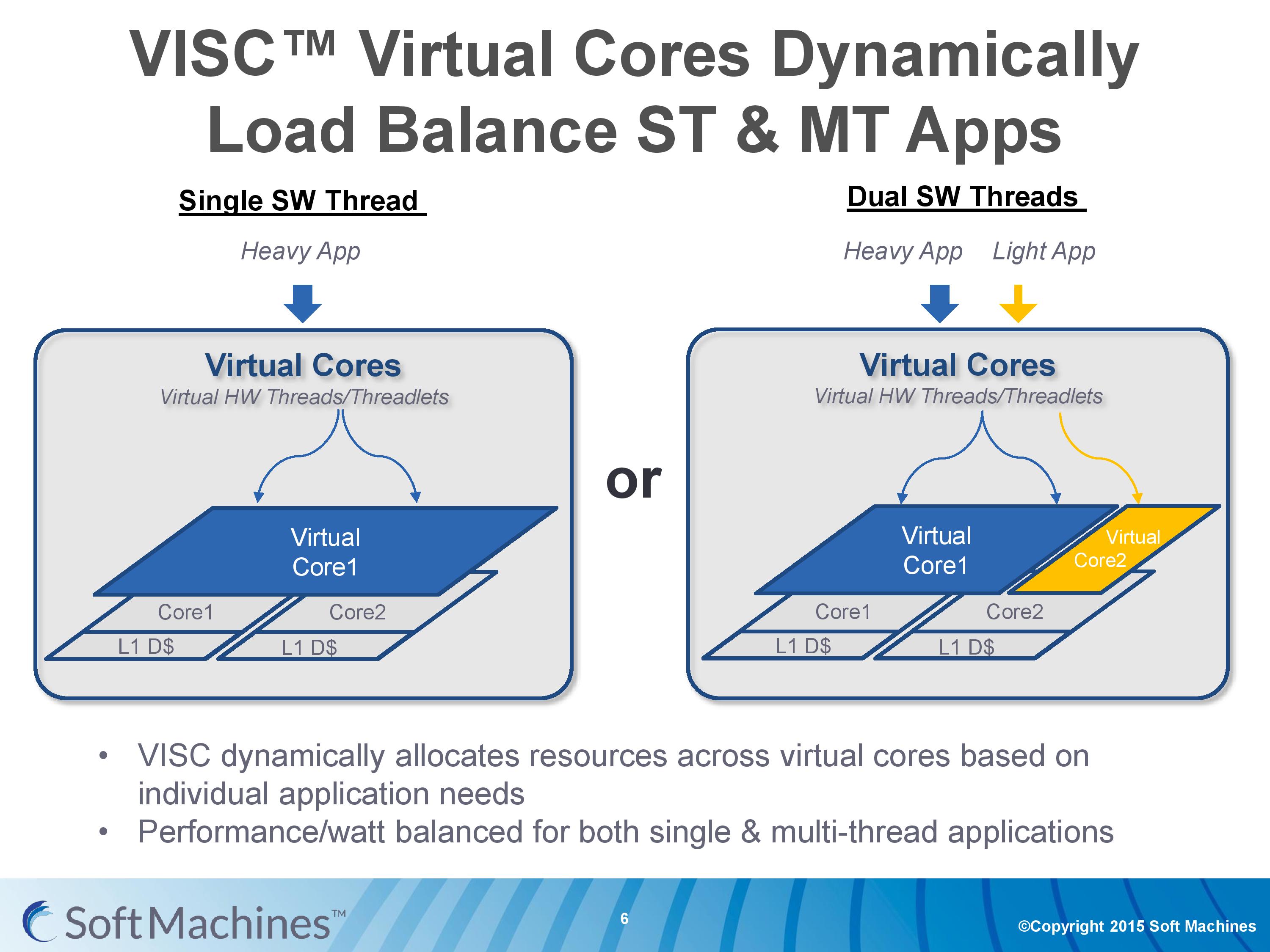
If one heaver thread needs more resources, it can take them from idle ports on a second core (or third, or fourth). The virtual cores can be configured at the software stage as well to limit their use (e.g. keep a VC to half a physical core), and this can be configured at runtime at the expense of 10-12 cycles. There is a quality of service implementation as well, so if a virtual core takes a high priority thread, it will have access to more resources by default.








97 Comments
View All Comments
xdrol - Saturday, February 13, 2016 - link
The Cruzoe was (and Denver is) a VLIW design, it needed software translation to run *anything*, telling what pipeline ports to schedule (a hard optimization problem). Here the translation is supposedly just an ARMv8 to internal ISA mapping, scheduling is still done by hardware like with a normal superscalar design.Jtaylor1986 - Friday, February 12, 2016 - link
Excellent article Ian. Thanksjjj - Friday, February 12, 2016 - link
1 more thing.Any clue about thermal management? Can they turn off individual physical cores or they just lower clocks? Being able to do both would be interesting.
matt321 - Friday, February 12, 2016 - link
This would make sense for someone like Apple to buy/invest/license the technology for their own processor development. They could have common cores with translations for both ARM and x86 (for iOS and OS X respectively) with the long-term goal of migrating completely to VISC ISA.extide - Friday, February 12, 2016 - link
This is interesting, because I have thought of doing a processor design somewhat like this for a long time. Remember when BD was coming out, there were rumors of "reverse Hyperthreading" well this is kinda that.I had thought that someone should make a suuuper wide cpu, like 20 or 30 wide, put TONS of execution resources on it, and then put a bunch of hyperthreads. That way a single thread could use all 20-30 execution resources, if possible, or you could have multiple threads sharing all that. Like instead of a quad core, with 2 threads/core have like a super core with 8+ threads, and then maybe a couple of those.
extide - Friday, February 12, 2016 - link
Although, I had always thought that engineers had thought of this already, and that maybe it was a bad idea due to some reason I don't understand, and that's why we haven't ever seen a design like that. Well, this is pretty similar to my idea, except they aren't making a super core, they are allowing a thread to use resources from several cores, if it needs.Exophase - Friday, February 12, 2016 - link
The problem is that going wider decreases efficiency and slows down critical paths. So the processor that's N * 2 wide will have to be a lot slower and/or less efficient than the one that's N wide. If software can rarely extract enough parallelism to go beyond N wide then the N * 2 wide version will almost always be worse. There's a good balance point to be found here.Some components in the CPU even scale worse than linearly as they increase in width. The wiring can increase quadratically or even exponentially.
In practice, a lot of the code that you could realistically extract a ton of ILP from is the type of code that's easiest to vectorize or thread (and a lot of vector + thread friendly can run well on GPUs). What remains, outside of some benchmarks anyway, is mostly a lot of code that has fairly limited ILP due to eventually hitting mispredicted branches or from very long dependency chains. Branch mispredictions are particularly bad on a CPU that has a ton of instructions in flight due to being very wide because that much more energy is wasted on failed speculation.
Oxford Guy - Friday, February 12, 2016 - link
So why wasn't Prescott really great (narrow and deep) versus the G5 (very wide and shallow)?Exophase - Saturday, February 13, 2016 - link
It's like I said, "there's a good balance point to be found here."Faster clocks need higher voltage which scales super-linearly with power consumption. They require longer pipelines which have worse branch misprediction penalties. They take more cycles to talk to other components that don't scale with CPU clock like RAM. More transistors (more space, power) are thrown at these things to try to compensate, like better branch predictors and more reordering, more aggressive prefetching, etc.
So there's a balancing act between two extremes and what makes the most sense will depend on the manufacturing process, target market and various other things.
G5 was actually not very wide and shallow anyway. It was a 2.7GHz processor in 2003 and was supposed to hit 3GHz. It had a 16-21 stage pipeline with up to > 200 instructions in flight. That's not shallow at all. 4 wide decode with 2x ALU + 2x L/S is not really that wide either.
AlexTi - Friday, February 12, 2016 - link
If algorithm is developed which can split current single-threaded code into "threadlets", which can be run in parallel, why can't it be used in compilers to make multi-threaded code to run on existing architecture? Especially in enviroments which use JIT?