Infrastructure as a Service: Benchmarking Cloud Computing
by Johan De Gelas on June 2, 2011 8:50 PM EST- Posted in
- IT Computing
- IT Computing general
- Cloud Computing
Response Time
Our current virtualization stress tests are focused on measuring the maximum throughput of a certain server CPU or server platform. As a result we try to maximize CPU load by using high amounts of concurrent (simulated) users. In other words, the concurrencies are quite a bit higher than what the (virtual or physical) machine can cope with, in order to attain 95-100% CPU load. As a result, the response times are inflated above what would be acceptable in the real world. Still, it would be interesting to get an idea of the response times for our server versus the cloud server.
Our vApus Mark II test starts off with 400 concurrent users and ends with 800 concurrent users. The 400 concurrent users still cause very high CPU load on most machines (80-90%), but that should still give us a "worst case" response time scenario. In the next graph we list the response time at the lowest concurrency. Terremark's data center was in Amsterdam, and we had an 11 to 20 ms round trip delay from our lab, so to be fair to Terremark you should deduct 11 to 20 ms from the Terremark numbers.
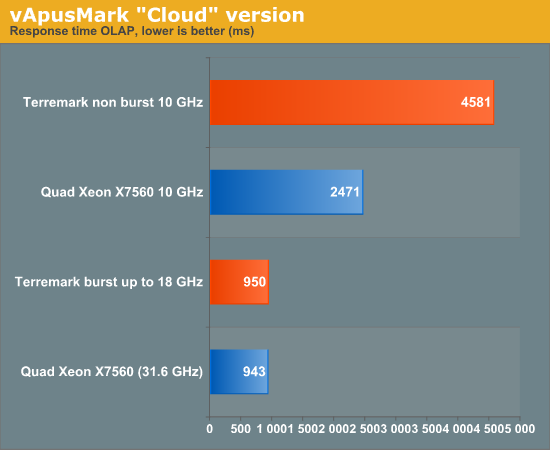
Both the "in house" server with 10GHz resource pool and the 10GHz Terremark "cloud server" get hit very hard by 400 concurrent MS SQL server connections, but the 10GHz resource pool that we get from the Terremark cluster is less powerful as it needs up to 85% more time to respond. The reason for that is twofold.
First, while the limit of the resource pool is at 10GHz, only 5GHz is reserved. So depending on how hard the parent resource pool is loaded by other VMs, we probably get somewhere between 5 and 10GHz of CPU power. Second, there is some extra overhead coming from the firewalls, routers, and load balancers between us and the VM. The infrastructure of Terremark is--for safety and security reasons--quite a bit more complex than our testing environment. That could add a few tens of ms too.
We also noticed that some parts of the Terremark cluster were using slightly older drivers (vmxnet 2 instead of vmxnet 3 for example), which might result in a few lost CPU cycles. But we are nitpicking and Terremark told us it is just a matter of time before the drivers get updated to the latest version.
And there is good news too. If you are willing to pay the premium for "bursting", the Terremark cluster scales very well and is capable of giving response times similar to what an "in house" server delivers. That is the whole point of cloud computing: pay and use peak capacity only when you actually need it.








29 Comments
View All Comments
TRodgers - Thursday, June 2, 2011 - link
I like the way you have broken this subject it to small succinct snipets of value information. I work in a place where many of our physical resources are being converted into virtual ones, and it is so often difficult to break down the process, the reasoning, and benefit trees etc to the many different audiences we have.johnsom - Friday, June 3, 2011 - link
You said:Renting 5GB of RAM is pretty straightforward: it means that our applications should be able to use up to 5GB of RAM space.
However this is not always the case with IaaS. vSphere allows memory over committing which allows you to allocate more memory across the virtual machines than the physical hardware makes available. If physical RAM is exhausted your VM gets swap file space tanking your VM memory performance. Likely killing performance when you need it most, peak memory usage.
GullLars - Friday, June 3, 2011 - link
If the pools are well dimentioned, this should almost never happen.If the pagefile is on something like an ioDrive, performance wouldn't tank but be a noticable bit slower. If the pagefile is on spinning disks, the performance would be horrible if your task is memory intensive.
duploxxx - Sunday, June 5, 2011 - link
THat is designing resource pools, if a service company is that idiot they will run out of business.Although swapping on SSD (certainly on next gen vsphere) is another way to avoid the slow performance as much as possible it is still slower and provides Hypervisor overhead.
Ram is cheap, well chosen servers have enough memory allocation.
ckryan - Friday, June 3, 2011 - link
I'm quite pleased with the easy, informative way the article has been presented; I for one would like to see more, and I'm sure future articles on the way. Keep it up, I think it's facinating.JohanAnandtech - Sunday, June 5, 2011 - link
Thank you for taking the time to let us know that you liked the article. Such readers have kept me going for the past 13 years (started in 1998 at Ace's ) :-).HMTK - Monday, June 6, 2011 - link
Yes, you're old :p The main reason I read Anand's these days is exactly for your articles. I liked them at Ace's, like them even more now. Nevertheless, nostalgia sometimes strikes when I think of Aces's and the hight quality of the articles and forums there.bobbozzo - Friday, June 3, 2011 - link
Hi, please include costs of the systems benchmarked... in the case of the Cloud, in $/hour or $/month, and in the case of the server, a purchase price and a lease price would be ideal.Thanks for all the articles!
bobbozzo - Friday, June 3, 2011 - link
Oh, and include electric consumption for the server.krazyderek - Friday, June 3, 2011 - link
i agree, showing a simple cost comparison would have really rounded out this article, it was mentioned several time "you pay for bursting" but how much? put it in perspective for us, relate it to over purchasing hardware for your own data center.