GeForce GTX 970: Correcting The Specs & Exploring Memory Allocation
by Ryan Smith on January 26, 2015 1:00 PM ESTSegmented Memory Allocation in Software
So far we’ve talked about the hardware, and having finally explained the hardware basis of segmented memory we can begin to understand the role software plays, and how software allocates memory among the two segments.
From a low-level perspective, video memory management under Windows is the domain of the combination of the operating system and the video drivers. Strictly speaking Windows controls video memory management – this being one of the big changes of Windows Vista and the Windows Display Driver Model – while the video drivers get a significant amount of input in hinting at how things should be laid out.
Meanwhile from an application’s perspective all video memory and its address space is virtual. This means that applications are writing to their own private space, blissfully unaware of what else is in video memory and where it may be, or for that matter where in memory (or even which memory) they are writing. As a result of this memory virtualization it falls to the OS and video drivers to decide where in physical VRAM to allocate memory requests, and for the GTX 970 in particular, whether to put a request in the 3.5GB segment, the 512MB segment, or in the worst case scenario system memory over PCIe.
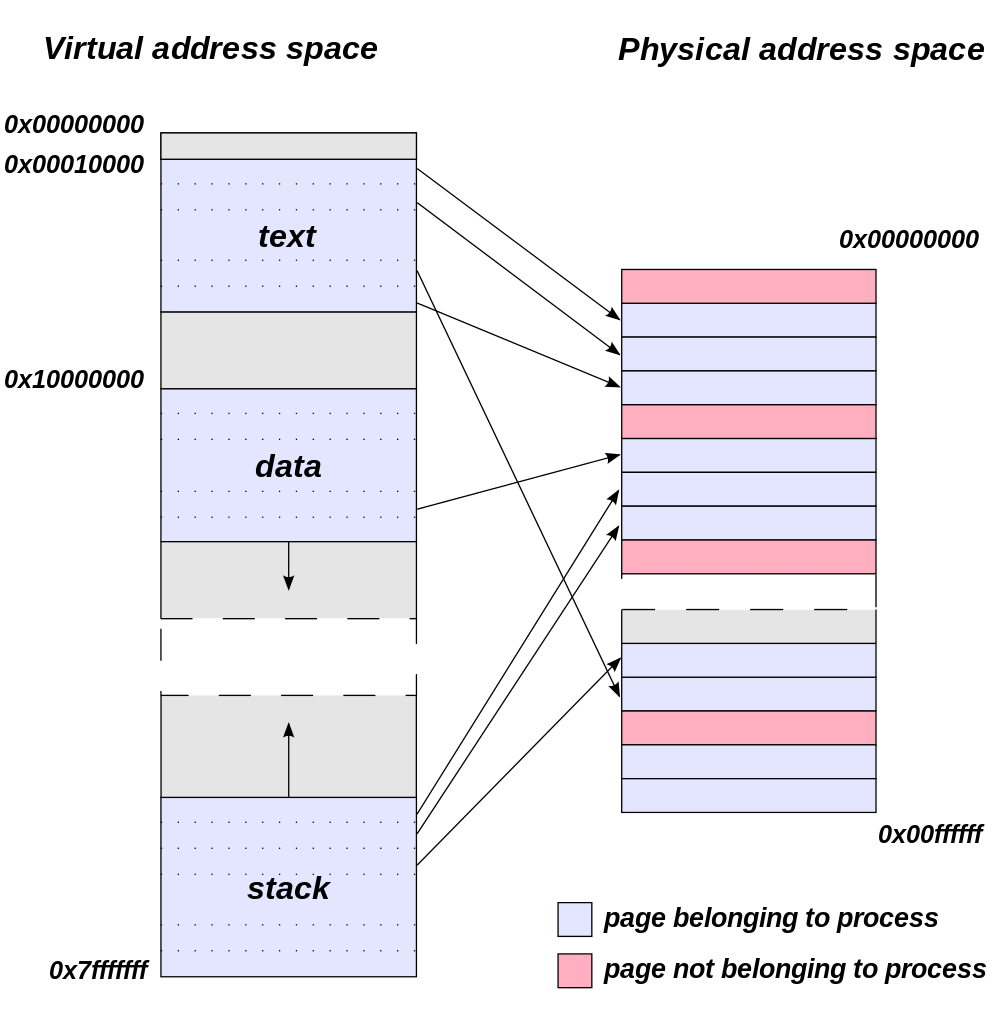
Virtual Address Space (Image Courtesy Dysprosia)
Without going quite so far to rehash the entire theory of memory management and caching, the goal of memory management in the case of the GTX 970 is to allocate resources over the entire 4GB of VRAM such that high-priority items end up in the fast segment and low-priority items end up in the slow segment. To do this NVIDIA focuses up to the first 3.5GB of memory allocations on the faster 3.5GB segment, and then finally for memory allocations beyond 3.5GB they turn to the 512MB segment, as there’s no benefit to using the slower segment so long as there’s available space in the faster segment.
The complex part of this process occurs once both memory segments are in use, at which point NVIDIA’s heuristics come into play to try to best determine which resources to allocate to which segments. How NVIDIA does this is very much a “secret sauce” scenario for the company, but from a high level identifying the type of resource and when it was last used are good ways to figure out where to send a resource. Frame buffers, render targets, UAVs, and other intermediate buffers for example are the last thing you want to send to the slow segment; meanwhile textures, resources not in active use (e.g. cached), and resources belonging to inactive applications would be great candidates to send off to the slower segment. The way NVIDIA describes the process we suspect there are even per-application optimizations in use, though NVIDIA can clearly handle generic cases as well.
From an API perspective this is applicable towards both graphics and compute, though it’s a safe bet that graphics is the more easily and accurately handled of the two thanks to the rigid nature of graphics rendering. Direct3D, OpenGL, CUDA, and OpenCL all see and have access to the full 4GB of memory available on the GTX 970, and from the perspective of the applications using these APIs the 4GB of memory is identical, the segments being abstracted. This is also why applications attempting to benchmark the memory in a piecemeal fashion will not find slow memory areas until the end of their run, as their earlier allocations will be in the fast segment and only finally spill over to the slow segment once the fast segment is full.
| GeForce GTX 970 Addressable VRAM | |||
| API | Memory | ||
| Direct3D | 4GB | ||
| OpenGL | 4GB | ||
| CUDA | 4GB | ||
| OpenCL | 4GB | ||
The one remaining unknown element here (and something NVIDIA is still investigating) is why some users have been seeing total VRAM allocation top out at 3.5GB on a GTX 970, but go to 4GB on a GTX 980. Again from a high-level perspective all of this segmentation is abstracted, so games should not be aware of what’s going on under the hood.
Overall then the role of software in memory allocation is relatively straightforward since it’s layered on top of the segments. Applications have access to the full 4GB, and due to the fact that application memory space is virtualized the existence and usage of the memory segments is abstracted from the application, with the physical memory allocation handled by the OS and driver. Only after 3.5GB is requested – enough to fill the entire 3.5GB segment – does the 512MB segment get used, at which point NVIDIA attempts to place the least sensitive/important data in the slower segment.








{kind=link}
398 Comments
View All Comments
loguerto - Saturday, February 7, 2015 - link
Such a shame ...fuckNvidia - Monday, February 9, 2015 - link
Just because you are happy being lied to don't mean everyone else should be. Just because you believe NVIDIA made a mistake don't mean it's ok they falsely advertised the gpu. What can NVIDIA gain out this? a high volume of sales and profit from false advertising. which is fraud so yeah i want my damn money back for both my 970's. Thanks anandtech.com for supporting false advertisement.Oxford Guy - Saturday, February 14, 2015 - link
8800 GT has twice the VRAM bandwidth of the 970's bad partition: 57.6 GB/s. It also doesn't have weird XOR contention problems.Midrange card from 2007...
ElGuapoK20 - Monday, February 16, 2015 - link
As a process engineer I can tell you what probably happened. Salesmen misinterpreted what engineers said, engineers saw the semi-published information and tried to correct the salesmen. Salesmen decided they were too far into it and nobody would notice, engineers aren't supposed to be involved with sales so they can't do anything except say, OK then.Yea, been there, done that before. I don't believe it's a big conspiracy at all, because it's not, just misinterpretation and then laziness.
Oxford Guy - Wednesday, February 18, 2015 - link
Nonsense. This flawed design was purposefully chosen by Nvidia executives. No one just says "Sure, we'll let the engineers come up with a design that provides 28 GB/s of bandwidth and XOR contention, just because".Nvidia made a big mistake by using this flawed design and was able to hide it from consumers for months.
Oxford Guy - Wednesday, February 18, 2015 - link
And what kind of engineer is going to come up with such a flawed gimped design in the first place? It's always management that comes up with these hare-brained schemes. Apple is famous for it, like when it gimped various computers (e.g. Apple IIgs) to prevent them from competing with favored models. Apple's hare-brained scheming with the Apple II vs. Mac line (trying to make the Mac a success at the cost of the Apple II line) cost them the schools market which they had totally dominated.No engineer who is competent enough to get a job at a high-profile tech company is going to say "Let's invent a way to create XOR contention and cut down VRAM bandwidth to half the speed of a 2007 midrange card for a $300+ product." Never ever. Engineers aren't the type of people who see virtue in hobbling things and designing awful flaws. It's the antithesis of engineering which is about creating something better than what came before. Management is the one who comes up with these schemes because it's not about product quality but about profit.
Oxford Guy - Wednesday, February 18, 2015 - link
When OCZ started selling Vertex 2 ssds with half the NAND chips (and the reduction in performance and capacity that went with that) it was the engineers not communicating well with the executives, right?If you believe that I have some excellent swampland in Florida for your perusal.
P39Airacobra - Monday, June 22, 2015 - link
Nothing to see here move along please! Pay no attention to that man behind the curtain! https://www.youtube.com/watch?v=YWyCCJ6B2WE