GeForce GTX 970: Correcting The Specs & Exploring Memory Allocation
by Ryan Smith on January 26, 2015 1:00 PM ESTSegmented Memory Allocation in Software
So far we’ve talked about the hardware, and having finally explained the hardware basis of segmented memory we can begin to understand the role software plays, and how software allocates memory among the two segments.
From a low-level perspective, video memory management under Windows is the domain of the combination of the operating system and the video drivers. Strictly speaking Windows controls video memory management – this being one of the big changes of Windows Vista and the Windows Display Driver Model – while the video drivers get a significant amount of input in hinting at how things should be laid out.
Meanwhile from an application’s perspective all video memory and its address space is virtual. This means that applications are writing to their own private space, blissfully unaware of what else is in video memory and where it may be, or for that matter where in memory (or even which memory) they are writing. As a result of this memory virtualization it falls to the OS and video drivers to decide where in physical VRAM to allocate memory requests, and for the GTX 970 in particular, whether to put a request in the 3.5GB segment, the 512MB segment, or in the worst case scenario system memory over PCIe.
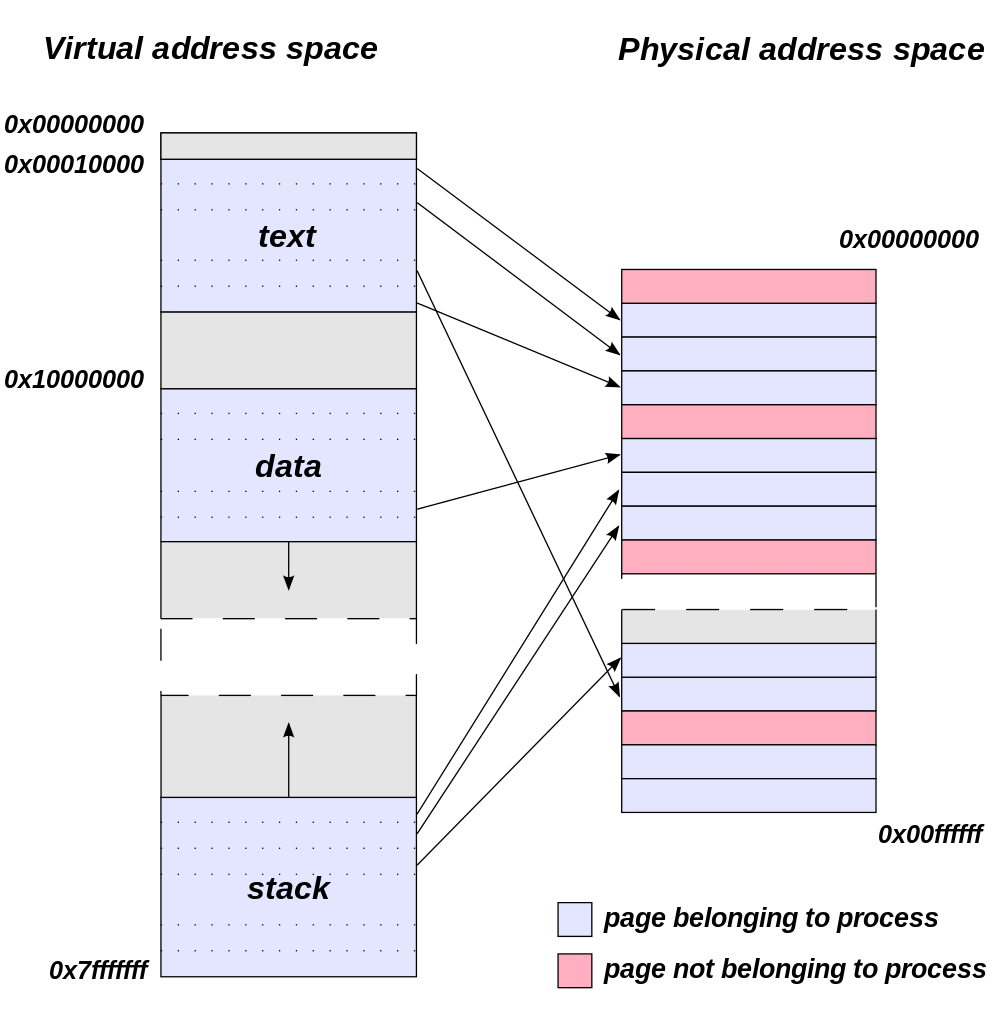
Virtual Address Space (Image Courtesy Dysprosia)
Without going quite so far to rehash the entire theory of memory management and caching, the goal of memory management in the case of the GTX 970 is to allocate resources over the entire 4GB of VRAM such that high-priority items end up in the fast segment and low-priority items end up in the slow segment. To do this NVIDIA focuses up to the first 3.5GB of memory allocations on the faster 3.5GB segment, and then finally for memory allocations beyond 3.5GB they turn to the 512MB segment, as there’s no benefit to using the slower segment so long as there’s available space in the faster segment.
The complex part of this process occurs once both memory segments are in use, at which point NVIDIA’s heuristics come into play to try to best determine which resources to allocate to which segments. How NVIDIA does this is very much a “secret sauce” scenario for the company, but from a high level identifying the type of resource and when it was last used are good ways to figure out where to send a resource. Frame buffers, render targets, UAVs, and other intermediate buffers for example are the last thing you want to send to the slow segment; meanwhile textures, resources not in active use (e.g. cached), and resources belonging to inactive applications would be great candidates to send off to the slower segment. The way NVIDIA describes the process we suspect there are even per-application optimizations in use, though NVIDIA can clearly handle generic cases as well.
From an API perspective this is applicable towards both graphics and compute, though it’s a safe bet that graphics is the more easily and accurately handled of the two thanks to the rigid nature of graphics rendering. Direct3D, OpenGL, CUDA, and OpenCL all see and have access to the full 4GB of memory available on the GTX 970, and from the perspective of the applications using these APIs the 4GB of memory is identical, the segments being abstracted. This is also why applications attempting to benchmark the memory in a piecemeal fashion will not find slow memory areas until the end of their run, as their earlier allocations will be in the fast segment and only finally spill over to the slow segment once the fast segment is full.
| GeForce GTX 970 Addressable VRAM | |||
| API | Memory | ||
| Direct3D | 4GB | ||
| OpenGL | 4GB | ||
| CUDA | 4GB | ||
| OpenCL | 4GB | ||
The one remaining unknown element here (and something NVIDIA is still investigating) is why some users have been seeing total VRAM allocation top out at 3.5GB on a GTX 970, but go to 4GB on a GTX 980. Again from a high-level perspective all of this segmentation is abstracted, so games should not be aware of what’s going on under the hood.
Overall then the role of software in memory allocation is relatively straightforward since it’s layered on top of the segments. Applications have access to the full 4GB, and due to the fact that application memory space is virtualized the existence and usage of the memory segments is abstracted from the application, with the physical memory allocation handled by the OS and driver. Only after 3.5GB is requested – enough to fill the entire 3.5GB segment – does the 512MB segment get used, at which point NVIDIA attempts to place the least sensitive/important data in the slower segment.








{kind=link}
398 Comments
View All Comments
MrWhtie - Thursday, January 29, 2015 - link
"they set themselves up to hike prices in the future" hyperbole at its finest. Try again once you calm down and start speaking with some logic and reason.Casecutter - Wednesday, January 28, 2015 - link
^ It's simple they can't... They fused off one damaged defective L2 as they didn't have the volume of good GM204 to go to market with enough 970 parts. I would believe that the GTX 980M is a 12SMX part alought has all the L2 as the GTX980. They realy screw th pouch by touting "the GTX 970 ships with THE SAME MEMORY SUBSYSTEM AS OUR FLAGSHIP GEFORCE GTX 980".Nvidia came out and said "This team (PR) was unaware that with "Maxwell," you could segment components previously thought indivisible, or that you could "partial disable" components."
Had Nvidia called it 3.5Gb with Active Boost... or 4Gb Memory Compression... or something like that and explained I think a lot of folks would've taken interest and weigh that when making a choice... But we weren't privy to that information.
Elixer - Wednesday, January 28, 2015 - link
Looks like Nvidia is trying to make good.They will help you get a refund/credit for your 970 if you feel you want one.
http://forums.anandtech.com/showpost.php?p=3712051...
"I totally get why so many people are upset. We messed up some of the stats on the reviewer kit and we didn't properly explain the memory architecture. I realize a lot of you guys rely on product reviews to make purchase decisions and we let you down.
It sucks because we're really proud of this thing. The GTX970 is an amazing card and I genuinely believe it's the best card for the money that you can buy. We're working on a driver update that will tune what's allocated where in memory to further improve performance.
Having said that, I understand that this whole experience might have turned you off to the card. If you don't want the card anymore you should return it and get a refund or exchange. If you have any problems getting that done, let me know and I'll do my best to help."
MrWhtie - Wednesday, January 28, 2015 - link
Yeah right, they can't have my 970 back :P What am I going to buy instead, an AMD? (LOL!)CX71 - Wednesday, January 28, 2015 - link
> "What am I going to buy instead, an AMD? (LOL!)"That would be a good move ... TROLOLOLOLOL
mudz78 - Wednesday, January 28, 2015 - link
That's great news. Good see a company owning their mistakes and doing the right thing by consumers.The GTX 970 is still a good card, but purchasers have a right to make an informed decision before handing over their hard earned dollars.
Man_Of_Steele - Thursday, January 29, 2015 - link
If they really are accepting returns and refunds regardless of when you purchased your card, that would make this seem like it really was an honest mistake - despite the mistake seeming highly unlikely.As for me, 3.5gb VRAM isn't enough to justify $350-$400 (EVGA SC or SSC). I will wait and see what AMD does with the 390x, and wait and see if nVIDIA launches an 8gb (read 7gb) 970
Man_Of_Steele - Wednesday, January 28, 2015 - link
I understand that the cache isn't a huge issue, but as far as a future proof card, only 3.5gb VRAM..?You guys can form your own opinions, but that is a lot of people within the company that this error just so happened to slip past. There is also a notable stutter in Shadow of Mordor for those who haven't seen that yet.
What I am curious to see, is if there is a way to re-enable the ROPs and increase the clock on that last 500mb vram. This may be impossible and I'm just ignorant on the issue, but if someone knows please let me know if its possible!
MrWhtie - Thursday, January 29, 2015 - link
I don't think its possible, that last 500mb is slow because it only has one of its ROP/L2 units disabled (compared with 8 fully active on the 980). This causes one of the remaining ROP/L2 units to communicate with TWO of the 500mb DRAM sections (instead of 8 ROP/L2 each with their own 500mb DRAM.) Since it cannot access both 500mb secitions at once, it can only use 500mb in a "fast mode". When it tries to access both the speed is cut in half since normal operation is ONE ROP per 500mb DRAM. (The diagram on the second page illustrates this.)Its a hardware thing, its not a software issue whatsoever.
Man_Of_Steele - Thursday, January 29, 2015 - link
I saw the diagrams on a couple different sites, I just wasn't sure if they disabled it the smart way or the lazy way.Thanks for the clarification!