GeForce GTX 970: Correcting The Specs & Exploring Memory Allocation
by Ryan Smith on January 26, 2015 1:00 PM ESTSegmented Memory Allocation in Software
So far we’ve talked about the hardware, and having finally explained the hardware basis of segmented memory we can begin to understand the role software plays, and how software allocates memory among the two segments.
From a low-level perspective, video memory management under Windows is the domain of the combination of the operating system and the video drivers. Strictly speaking Windows controls video memory management – this being one of the big changes of Windows Vista and the Windows Display Driver Model – while the video drivers get a significant amount of input in hinting at how things should be laid out.
Meanwhile from an application’s perspective all video memory and its address space is virtual. This means that applications are writing to their own private space, blissfully unaware of what else is in video memory and where it may be, or for that matter where in memory (or even which memory) they are writing. As a result of this memory virtualization it falls to the OS and video drivers to decide where in physical VRAM to allocate memory requests, and for the GTX 970 in particular, whether to put a request in the 3.5GB segment, the 512MB segment, or in the worst case scenario system memory over PCIe.
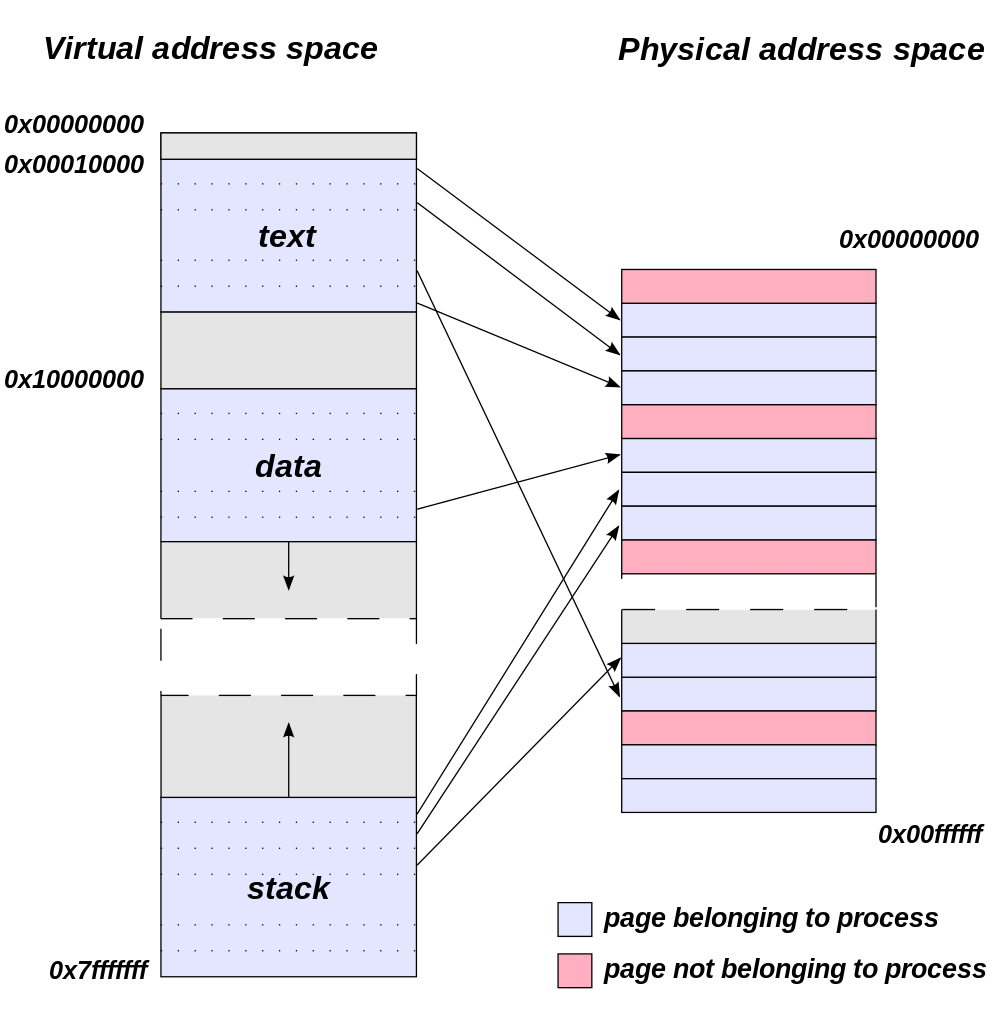
Virtual Address Space (Image Courtesy Dysprosia)
Without going quite so far to rehash the entire theory of memory management and caching, the goal of memory management in the case of the GTX 970 is to allocate resources over the entire 4GB of VRAM such that high-priority items end up in the fast segment and low-priority items end up in the slow segment. To do this NVIDIA focuses up to the first 3.5GB of memory allocations on the faster 3.5GB segment, and then finally for memory allocations beyond 3.5GB they turn to the 512MB segment, as there’s no benefit to using the slower segment so long as there’s available space in the faster segment.
The complex part of this process occurs once both memory segments are in use, at which point NVIDIA’s heuristics come into play to try to best determine which resources to allocate to which segments. How NVIDIA does this is very much a “secret sauce” scenario for the company, but from a high level identifying the type of resource and when it was last used are good ways to figure out where to send a resource. Frame buffers, render targets, UAVs, and other intermediate buffers for example are the last thing you want to send to the slow segment; meanwhile textures, resources not in active use (e.g. cached), and resources belonging to inactive applications would be great candidates to send off to the slower segment. The way NVIDIA describes the process we suspect there are even per-application optimizations in use, though NVIDIA can clearly handle generic cases as well.
From an API perspective this is applicable towards both graphics and compute, though it’s a safe bet that graphics is the more easily and accurately handled of the two thanks to the rigid nature of graphics rendering. Direct3D, OpenGL, CUDA, and OpenCL all see and have access to the full 4GB of memory available on the GTX 970, and from the perspective of the applications using these APIs the 4GB of memory is identical, the segments being abstracted. This is also why applications attempting to benchmark the memory in a piecemeal fashion will not find slow memory areas until the end of their run, as their earlier allocations will be in the fast segment and only finally spill over to the slow segment once the fast segment is full.
| GeForce GTX 970 Addressable VRAM | |||
| API | Memory | ||
| Direct3D | 4GB | ||
| OpenGL | 4GB | ||
| CUDA | 4GB | ||
| OpenCL | 4GB | ||
The one remaining unknown element here (and something NVIDIA is still investigating) is why some users have been seeing total VRAM allocation top out at 3.5GB on a GTX 970, but go to 4GB on a GTX 980. Again from a high-level perspective all of this segmentation is abstracted, so games should not be aware of what’s going on under the hood.
Overall then the role of software in memory allocation is relatively straightforward since it’s layered on top of the segments. Applications have access to the full 4GB, and due to the fact that application memory space is virtualized the existence and usage of the memory segments is abstracted from the application, with the physical memory allocation handled by the OS and driver. Only after 3.5GB is requested – enough to fill the entire 3.5GB segment – does the 512MB segment get used, at which point NVIDIA attempts to place the least sensitive/important data in the slower segment.








{kind=link}
398 Comments
View All Comments
slickr - Monday, January 26, 2015 - link
O come on. You sound like Nvidia PR. So after working months/years on this architecture, you won't take several days rest and look at some of the reviews on your baby, on your product? No one in their company did? No one even skimmed through the first page of reviews and news?We've had reviews from when the cards officially launched, to months later reviews of custom cards, etc...
To me you sound like you are on Nvidia's pay check. I'm sorry, but I expect critical view from the media, not PR talk. Either you change the definition of this site from "Website" to "fansite" or start doing critical journalism, not this white washing PR bullshit!
Ryan Smith - Monday, January 26, 2015 - link
To truly understand this, you probably would need to have been on the phone with Jonah. The team that designed the architecture is not the team that picked the individual product configurations, and as a result they have no clue how many ROPs a part is supposed to have. Never mind the fact that they haven't looked at the architecture in a year or more.Modern product development is highly specialized, with each team working on its own little niche. This means they're generally blind to what everyone else is doing.
Whether you find that answer satisfactory or not is up to you. But the employees reading the review are generally not going to be the employees who know that 64 is the wrong number of ROPs on one specific SKU.
OrphanageExplosion - Monday, January 26, 2015 - link
I find that hard to believe to be honest, Ryan.You think a guy like, say, Tom Petersen who knows the product and knows the press inside out doesn't read the reviews and doesn't know the true specification of the GTX 970?
anandreader106 - Monday, January 26, 2015 - link
"....But the employees reading the review are generally not going to be the employees who know that 64 is the wrong number of ROPs on one specific SKU."So the employees that would know that 64 was the wrong number do not read reviews on the internet?
JarredWalton - Monday, January 26, 2015 - link
Correct, because they're doing hardware design. I highly doubt Jonah even does more than a cursory glance at most of the reviews. He's paid too much to be doing that. Even guys like Jen Hsun aren't going to read all the hardware reviews -- they'll get the executive summary of how the launch went.mapesdhs - Monday, January 26, 2015 - link
In the 1990s I knew someone involved with CPU development who told me about the nature
of his work, the pay, the hours, etc. I full agree with Jarred, these people work very hard and
are extremely well paid; they're not going to be reading reviews, they're far too busy, almost
certainly working on whatever's coming next.
Ian.
alacard - Monday, January 26, 2015 - link
Hook, line, and sinker. Watching all these tech journalists rushing to Nvidia's defense is just priceless. Guys, when your master's knock some shit off their table for you to eat, have some self respect and try to recognize it for what it is so you can treat it accordingly in your write-ups because as it stands right now you're all Exhibit A in the inevitable inquiry into the death and total collapse of the fourth estate.dragonsqrrl - Monday, January 26, 2015 - link
Yes, all these credible tech journalists are conspiring with Nvidia to cover this all up. Has Demerjian issued a statement yet?yannigr2 - Tuesday, January 27, 2015 - link
When AMD released Hawaii and the hardware sites where seeing the core clock throttling, it was not about performance, but about the core clock of the GPU. Now that Nvidia lied about the specs, it's not about the specs, but about how small is the performance penalty. Do you see the difference?OrphanageExplosion - Tuesday, January 27, 2015 - link
So nobody from the NVIDIA tech team read the reviewer's guide either then? I genuinely think it probably was a mistake, but the notion that nobody at NVIDIA noticed that *all* the public specs on the card are incorrect beggars belief and the notion of journalists *literally* making excuses for NVIDIA is stunning.The bottom line is this: GTX 970 is a fantastic card, the perf is stunning, but NVIDIA released dodgy specs, didn't correct them when they became public and should have been transparent about the 512MB partition right from the get-go. It wouldn't have changed anything in the reviews, and the card would still have been a huge success, 56 ROPs or not.
This is far less a perf issue and much more about trust.