GeForce GTX 970: Correcting The Specs & Exploring Memory Allocation
by Ryan Smith on January 26, 2015 1:00 PM ESTSegmented Memory Allocation in Software
So far we’ve talked about the hardware, and having finally explained the hardware basis of segmented memory we can begin to understand the role software plays, and how software allocates memory among the two segments.
From a low-level perspective, video memory management under Windows is the domain of the combination of the operating system and the video drivers. Strictly speaking Windows controls video memory management – this being one of the big changes of Windows Vista and the Windows Display Driver Model – while the video drivers get a significant amount of input in hinting at how things should be laid out.
Meanwhile from an application’s perspective all video memory and its address space is virtual. This means that applications are writing to their own private space, blissfully unaware of what else is in video memory and where it may be, or for that matter where in memory (or even which memory) they are writing. As a result of this memory virtualization it falls to the OS and video drivers to decide where in physical VRAM to allocate memory requests, and for the GTX 970 in particular, whether to put a request in the 3.5GB segment, the 512MB segment, or in the worst case scenario system memory over PCIe.
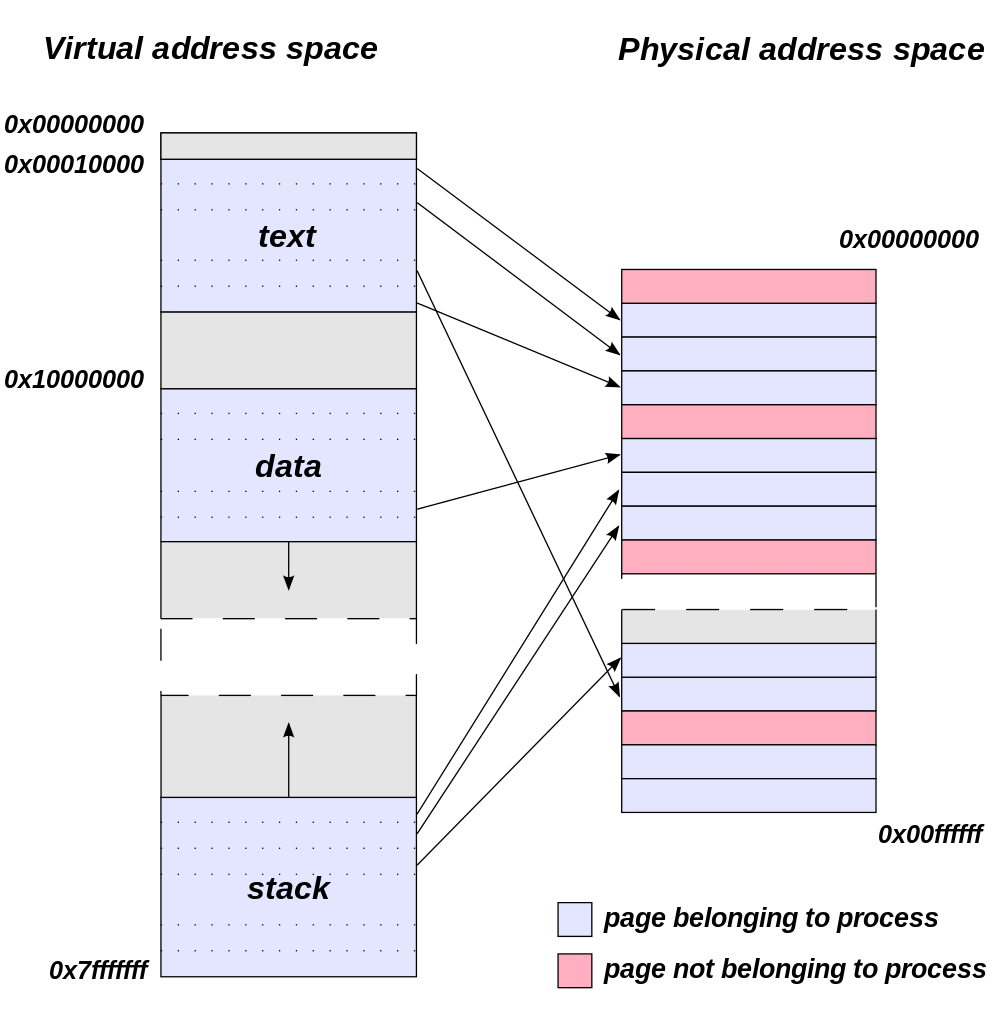
Virtual Address Space (Image Courtesy Dysprosia)
Without going quite so far to rehash the entire theory of memory management and caching, the goal of memory management in the case of the GTX 970 is to allocate resources over the entire 4GB of VRAM such that high-priority items end up in the fast segment and low-priority items end up in the slow segment. To do this NVIDIA focuses up to the first 3.5GB of memory allocations on the faster 3.5GB segment, and then finally for memory allocations beyond 3.5GB they turn to the 512MB segment, as there’s no benefit to using the slower segment so long as there’s available space in the faster segment.
The complex part of this process occurs once both memory segments are in use, at which point NVIDIA’s heuristics come into play to try to best determine which resources to allocate to which segments. How NVIDIA does this is very much a “secret sauce” scenario for the company, but from a high level identifying the type of resource and when it was last used are good ways to figure out where to send a resource. Frame buffers, render targets, UAVs, and other intermediate buffers for example are the last thing you want to send to the slow segment; meanwhile textures, resources not in active use (e.g. cached), and resources belonging to inactive applications would be great candidates to send off to the slower segment. The way NVIDIA describes the process we suspect there are even per-application optimizations in use, though NVIDIA can clearly handle generic cases as well.
From an API perspective this is applicable towards both graphics and compute, though it’s a safe bet that graphics is the more easily and accurately handled of the two thanks to the rigid nature of graphics rendering. Direct3D, OpenGL, CUDA, and OpenCL all see and have access to the full 4GB of memory available on the GTX 970, and from the perspective of the applications using these APIs the 4GB of memory is identical, the segments being abstracted. This is also why applications attempting to benchmark the memory in a piecemeal fashion will not find slow memory areas until the end of their run, as their earlier allocations will be in the fast segment and only finally spill over to the slow segment once the fast segment is full.
| GeForce GTX 970 Addressable VRAM | |||
| API | Memory | ||
| Direct3D | 4GB | ||
| OpenGL | 4GB | ||
| CUDA | 4GB | ||
| OpenCL | 4GB | ||
The one remaining unknown element here (and something NVIDIA is still investigating) is why some users have been seeing total VRAM allocation top out at 3.5GB on a GTX 970, but go to 4GB on a GTX 980. Again from a high-level perspective all of this segmentation is abstracted, so games should not be aware of what’s going on under the hood.
Overall then the role of software in memory allocation is relatively straightforward since it’s layered on top of the segments. Applications have access to the full 4GB, and due to the fact that application memory space is virtualized the existence and usage of the memory segments is abstracted from the application, with the physical memory allocation handled by the OS and driver. Only after 3.5GB is requested – enough to fill the entire 3.5GB segment – does the 512MB segment get used, at which point NVIDIA attempts to place the least sensitive/important data in the slower segment.








{kind=link}
398 Comments
View All Comments
Kevin G - Monday, January 26, 2015 - link
The weird thing is that the PS3 could off load vertex processing to Cell where it could be processed faster there. Also the FlexIO link between Cell and the RSX chip in the PS3 was remarkably faster than the 16x PCI 1.0 speed the 7800GT on the PC side had. This faster bus enabled things like vertex processing offloading and sharing the RDRAM memory pool or texture caching.Similarly the Xbox 360 had eDRAM for massive bandwidth and used a special 10 bit floating point format for HDR. That console could perform remarkably well for its actual hardware specs.
In reality, the greatest handicap the PC platform has isn't in hardware but rather software: Windows is a bloated mess. This is why API's like Mantle, DX12 and a rebirth of low level OpenGL have the hype as they cut away the cruft from Window's evolution.
Galidou - Monday, January 26, 2015 - link
It's not totally Windows's fault, the problem is it has to be so compatible with everything and god knows there's a HOLY ton of software and hardware it needs to consider that exists and doesn't exist yet.It's easier to design a link between a CPU and a GPU helping each other when they will be paired together for life.
Kevin G - Tuesday, January 27, 2015 - link
The bloat didn't stem from abstracting different types of hardware from each other so that they could be compatible. Rather, it was the software architecture itself that became bloated to maintain compatibility with existing applications using that API while the hardware continue to evolved. Many of the early assumptions of GPU hardware no longer apply but legacy DirectX imposes artificial limitations. For example, AMD and nVidia GPU's have supported far larger texture sizes than is what DiectX lists as a maximum.Flunk - Monday, January 26, 2015 - link
I personally don't think this would be a big concern to me, Even if it only had 3.5GB of RAM the 970 would still be a good deal.Oxford Guy - Tuesday, January 27, 2015 - link
"Even if it only had 3.5GB of RAM the 970 would still be a good deal."Red herring.
dagnamit - Monday, January 26, 2015 - link
I see why you're willing to give them the benefit of the doubt here, and I may after some time, but holy cow, that's a pretty big boat of mistakes . I mean NO ONE at Nvidia saw the reviews and felt the need to correct them (or if they're barred by contract from contacting review sites, send the reports up the chain of command.). It defies credulity, but stupider things have happened, I guess.That shuffling noise you hear is the sound of 1000's of lawyer attempting to file to be the representative for the inevitable class action.
jeffkibuule - Monday, January 26, 2015 - link
Would the people with this kind of intimate knowledge really bother reading in detail a review of a product they worked on for months/years anyway?airman231 - Monday, January 26, 2015 - link
One possible reason can be to 'correct' any mistakes or misrepresentations that a major reviewer might make. And IIRC, there are instances where some review sites have made noted edits to their reviews after being contacted by NVIDIA (or AMD)I suspect many wouldn't want to work so hard on a product and see it misrepresented. They take the time and cost to ship out free cards to some of these review sites, and so I wouldn't be surprised that they'd have some interest in how it's reviewed and viewed by media that can influence opinion and sales.
RazrLeaf - Monday, January 26, 2015 - link
I know from working on long term projects/products that once you're done, you tend not to look back. I've only ever looked back when someone came to me asking questions.Ryan Smith - Monday, January 26, 2015 - link
This is actually a very good point. Especially in chip design due to the long development cycle.By the time GTX 970 launched, the architectural team would already be working on the n+2 GPU architecture. The manufacturing team would be working on finalizing the next card. The only people actively vested in the product at launch were support, product management, and technical marketing. The latter of which is technically the division that evaluates reviews, and they of course thought 64 ROPs was correct.
We get quite a bit of traffic from the companies whose products we review. But when most of those employees either don't know the specs of a specific SKU (Jonah Alben won't know that GTX 970 has 56 ROPs off of the top of his head) or those employees have the wrong value, there really isn't anyone to correct it.