NVIDIA Tegra X1 Preview & Architecture Analysis
by Joshua Ho & Ryan Smith on January 5, 2015 1:00 AM EST- Posted in
- SoCs
- Arm
- Project Denver
- Mobile
- 20nm
- GPUs
- Tablets
- NVIDIA
- Cortex A57
- Tegra X1

In the past few years, we’ve seen NVIDIA shift their mobile strategy dramatically with time. With Tegra 2 and 3, we saw multiple design wins in the smartphone space, along with the tablet space. These SoCs often had dedicated GPUs that were quite unlike what we saw in NVIDIA’s desktop and laptop GPUs, with a reduced feature set and unique architecture. However, with Tegra K1 we saw a distinct shift in NVIDIA’s SoC strategy, as the Tegra K1 was the first mobile SoC to achieve parity in GPU architecture with desktop GPUs. In the case of the Tegra K1, this meant a single Kepler SMX which made for truly incredible GPU performance. However, in the time since we’ve seen companies like Apple release new SoCs such as the A8X, which managed to bring largely similar performance with less power.
NVIDIA of course is never content to stay idle for too long and let themselves be surpassed, which has led to the company developing their Tegra SoCs on a roughly yearly cadence. In NVIDIA’s development timeline, 2014 brought us the Tegra K1-32, the company’s first SoC to integrate a modern high-performance GPU architecture (Kepler), and later on the TK1-64, a K1 with NVIDIA’s own in-house developed ARMv8 Denver CPU in place of the 32bit ARM A15 CPU.
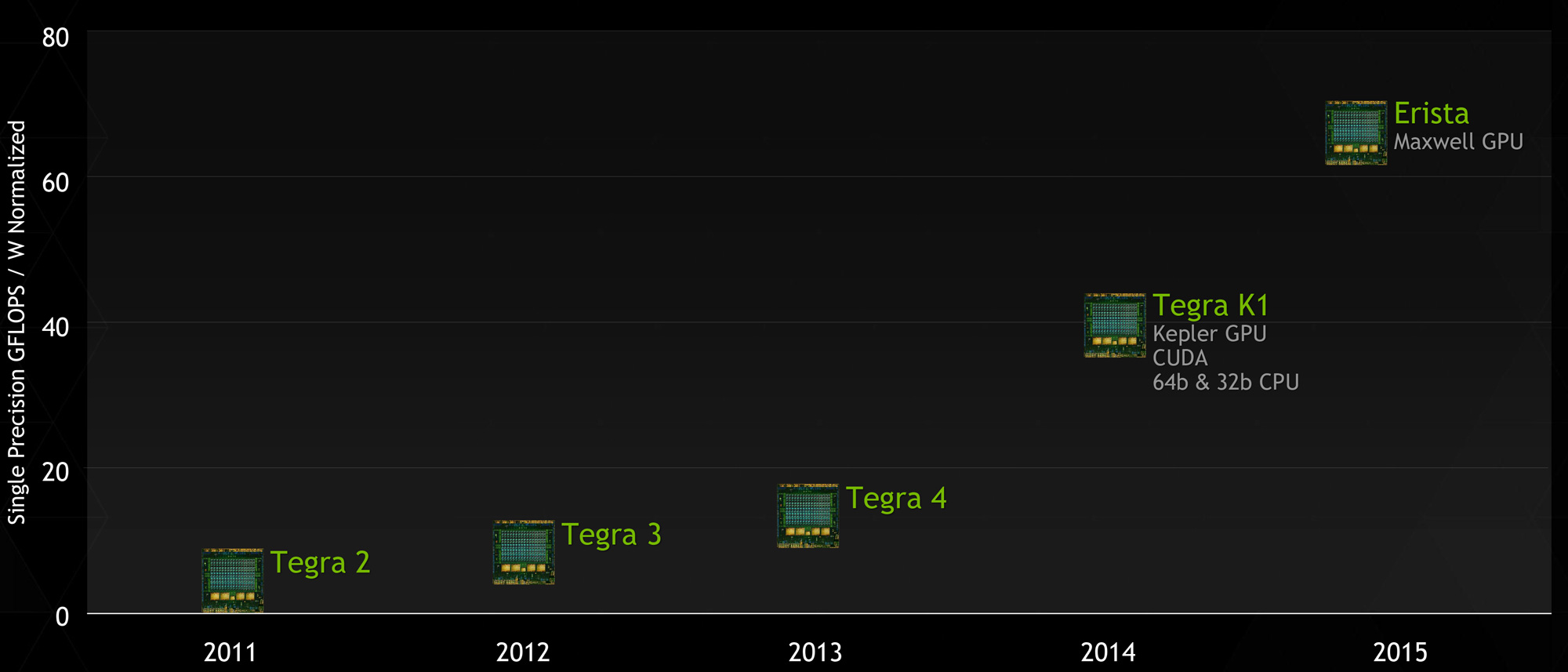
NVIDIA's GTC 2014 Tegra Roadmap
2014 also brought a revision to NVIDIA’s public Tegra roadmap: for 2015 NVIDIA would bump the previously announced Parker SoC and release a new in its place, Erista. This schedule change ended up being quite a surprise due to the fact that NVIDIA had up until this time released their roadmaps roughly 2 years out, whereas Erista was put on the map less than a year before it was to be announced. More unusual, NVIDIA offered up minimal details of Erista; it would be powered by a Maxwell GPU with no additional information on the CPU or manufacturing process. Parker on the other hand – NVIDIA’s planned Denver + Maxwell + 16nm FinFet part – fell off the schedule, with NVIDIA not officially canceling it but also saying little else about it.
Now in 2015 and with the launch of the Tegra X1, we can finally begin putting the picture together. Erista as it turns out is something of a rapid release product for NVIDIA; what had been plans to produce a 16nm FF part in 2015 became plans to produce a 20nm part, with Erista to be that part. To pull together Erista NVIDIA would go for a quick time-to-market approach in SoC design, pairing up a Maxwell GPU with ARM Cortex A57 & A53 GPUs, to be produced on TSMC’s 20nm SoC process.
CPU

We’ll kick off our look at Erista then with a look at Erista’s CPUs, where one of the bigger surprises in Erista is the CPU configuration. While Tegra K1 had a version with NVIDIA’s custom Denver core for the CPU, NVIDIA has elected to use ARM’s Cortex A57 and A53 in the Tegra X1. The A57 CPU cluster has 2MB of L2 cache shared across the four cores, with 48KB/32KB L1s (I$+D$) per core. The A53 cluster has 512KB of L2 cache shared by all four cores and 32KB/32KB L1s (I$+D$) per core. NVIDIA representatives stated that this was done for time to market reasons.
However, rather than a somewhat standard big.LITTLE configuration as one might expect, NVIDIA continues to use their own unique system. This includes a custom interconnect rather than ARM’s CCI-400, and cluster migration rather than global task scheduling which exposes all eight cores to userspace applications. It’s important to note that NVIDIA’s solution is cache coherent, so this system won't suffer from the power/performance penalties that one might expect given experience with previous SoCs that use cluster migration.
Although cluster migration is usually a detriment to power and performance (especially without a cache coherent interconnect), NVIDIA claims that Tegra X1 significantly outperforms Samsung System LSI’s Exynos 5433 in performance per watt with 1.4x more performance at the same amount of power or half the power for the same performance on the CPU. It's likely that this difference comes from optimizing the implemented logic and differences between Samsung and TSMC 20nm processes rather than differences in thread management. NVIDIA continues to use System EDP (Electrical Design Point) management to control throttling and turbo rather than ARM's IPA (Intelligent Power Allocation) drivers, and in general it seems that while the CPU architecture is ARM's reference design it's quite clear that everything else is distinctly NVIDIA in design.
All of this of course raises the question of where’s Denver, and what is to happen to it? The use of the ARM Cortex A57 and A53, as NVIDIA tells it, was based on a time-to-market decision, and that NVIDIA could bring an off-the-shelf Cortex-based SoC to the market sooner than they could another Denver SoC. On the surface there is at least some evidence to agree with this, as NVIDIA would be able to buy a 20nm design from ARM versus spending the time porting Denver over from TSMC’s 28nm process to their 20nm process. At the same time however integrating an ARM CPU core into an SoC is not an easy task – logic LEGO this is not – so it’s hard to say whether this actually saved NVIDIA much time.
In any case, much like the still in the dark Parker design, NVIDIA is holding their cards close to their chest and hinting that Denver will still be in future generation products. If Parker is still part of NVIDIA’s plans – and they are without a doubt working on some kind of 16nm FF Tegra SoC – then we may still see Denver as part of the original Parker plan. Otherwise at this point while there’s no reason not to believe NVIDIA about the fate of future Denver SoCs, it’s anyone’s guess when we might see it again.
Uncore

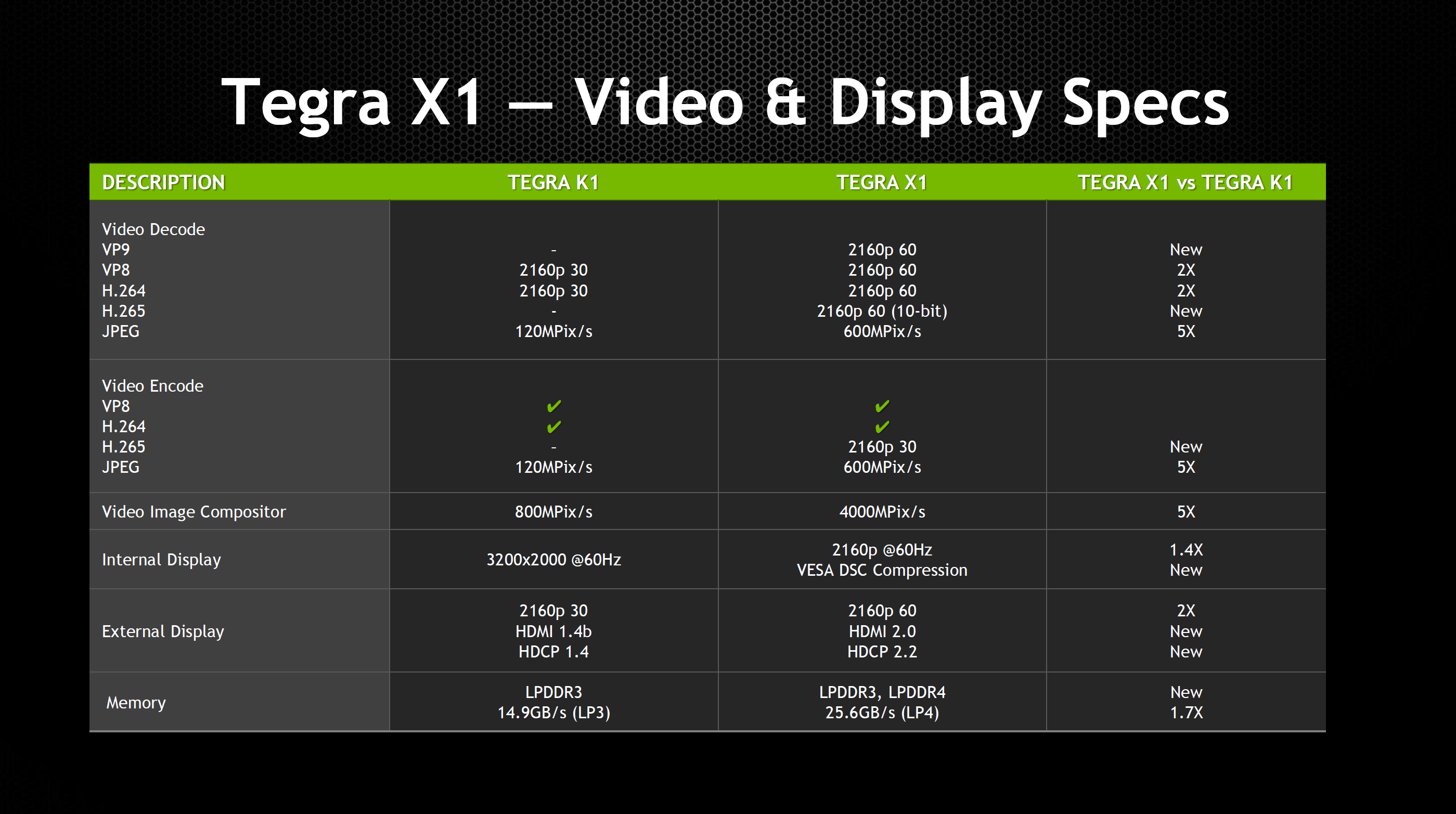
Outside of the CPU and GPU, NVIDIA has also dramatically improved the rest of Tegra X1 in comparison with Tegra K1. We see a move from 64-bit wide LPDDR3 to 64-bit wide LPDDR4 on the memory interface, which improves peak memory bandwidth from 14.9 GB/s to 25.6 GB/s and improves power efficiency by around 40%. In addition, the maximum internal display resolution moves from 3200x2000 at 60 Hz to 3840x2160 at 60 Hz with support for VESA’s display stream compression. For external displays, we see a significant improvement with support for HDMI 2.0 and HDCP 2.2, which means that 4K60 is supported in contrast with the Tegra K1, which only supported 4K30.
The ISP is largely similar to the one we see in the Tegra K1 when it comes to feature set, but JPEG encode and decode rate is now five times as fast, going from 120 MP/s to 600 MP/s. For video encode and decode, we see support for 4K60 H.265 and VP9, with support for 10 bit color on decode on H.265. In addition to support for new codecs in the hardware blocks, we see that H.264 and VP8 now support 4K60, a notable improvement over the 4K30 that was the maximum for Tegra K1. We also see that the storage controller now supports eMMC 5.1 for faster storage performance.








194 Comments
View All Comments
chizow - Monday, January 5, 2015 - link
Nvidia is only catching up on process node, because what they've shown is when comparing apples to apples:1) They have a much faster custom 64-bit CPU (A8X needed 50% more CPU to edge Denver K1)
2) They have a much faster GPU architecture (A8X also needed 50% more GPU cores to edge Denver K1, but get destroyed by Tegra X1 on the same 20nm node).
As we can see, once it is an even playing field at 20nm, A8X isn't going to be competitive.
GC2:CS - Monday, January 5, 2015 - link
Thy just postponed their "much faster custom 64-bit CPU" in favor of off the shelf design and compared to A8X is much higher clocked.A8X has just 33% percent more "cores" than k1 and aggain the GXA6850 GPU is probably miles under ~1Ghz clockspeed that nvidia targets.
And what's wrong with using a wider CPU/GPU ?
And yeah Tegrax1 is up to 2x faster than A8X, but considering it also runs at the same power as K1, it is not a lot more efficient.
chizow - Monday, January 5, 2015 - link
How do you get only 33% for A8X? A8 = 2 core, Denver K1 = 2 core, A8X = 3 core. 1/2 = 50% increase.Same for A8X over A8. GPU cores went from 4 to 6, again, 2/4 = 50% increase. Total transistors went from 2Bn to 3Bn, again 50% increase.
In summary, Apple fully leveraged 20nm advantage to match Denver K1 GPU and edge in CPU (still losing in single-core) using a brute-force 50% increase in transistors and functional units.
Obviously they won't be able to pull the same rabbit out of the hat unless they go to FinFet early, which is certainly possible, but then again, its not really a magic trick when you pay a hefty premium for early access to the best node is it?
Bottomline is Nvidia is doing more on the same process node as Apple, simple as that, and that's nothing to be ashamed of from an engineering standpoint.
GC2:CS - Monday, January 5, 2015 - link
A8X got 8 GPU clusetrs. And I still can't get your idea, you think that A8X is worse because it's brute force ~ 50% faster ? Yeah it is brute force, but I don't know how can you preceive that as a bad thing.They will certainly try to push finfet and rather hard I think.
And how can you say that nvidia is doing more on the same node while boasting how apple is the one who is doing more and how it's bad just above ?
chizow - Monday, January 5, 2015 - link
Wow A8X is 8 clusters and doesn't even offer a 100% increase over A8? Even worst than I thought, I guess I missed that update at some point over the holiday season.The point is that in order to match the "disappointing" Denver K1, Apple had to basically redouble their efforts to produce a massive 3Bn transistor SoC while fully leveraging 20nm. You do understand that's really not much of an accomplishment when you are on a more advanced process node right?
Sure Apple may push FinFET hard, but from everything I've read, FinFET will be more widely available for ramp compared to the problematic 20nm, which was always limited capacity outside of the premium allocation Apple pushed for (since they obviously needed it to distinguish their otherwise unremarkable SoCs).
It should be obvious why I am saying Nvidia is doing more on the same process node, because when you compare apple to Apples, Nvidia's chip on the 28nm node is more than competitive with the 20nm Apple chips, and when both are on 20nm, its going to be no contest in Nvidia's favor.
Logical conclusion = Nvidia is doing more on the same process node, ie. outperforming their competition when the playing field is leveled.
lucam - Tuesday, January 6, 2015 - link
Chizow the more I read and the more I laugh. You compare clusters with cores they have different technologies and you still state this crap. Maybe would be better to compare how much both of them are capable in term of of GFLOPS at same frequency? This is count. Regarding your absurd discussion of processing node, since the Nvidia chip is so efficient, I look forward to see it in smartphones.aenews - Saturday, January 24, 2015 - link
The A8X isn't on any phones either. In fact, they left it out of both iPhones AND the iPad Mini.And take in mind, even the Qualcomm Snapdragon 805 had few design wins... only the Kindle Fire HDX for tablets. They scored two major phones (Nexus 6 and Note 4) but the other manufacturers haven't used it.
squngy - Monday, January 5, 2015 - link
He did not say it is worse, his whole point is that Apple most likely will not be able to do the same thing again.tipoo - Tuesday, May 17, 2016 - link
Core counts are irrelevant across GPU architectures, they're just different ways of doing something.If someone gets to the same power draw, performance, and die size with 100 cores as someone else does with 10, what does it matter?
Jumangi - Monday, January 5, 2015 - link
Uh the A8 is an actual product that exists and wait for it you can actually BUY a product with it in there. This is another mobile paper launch by Nvidia with the consumer having no idea when or where it will actually be. The only thing real enthusiasts should care about is the companies that can actually deliver parts people can actually use. Nvidia still has a loooong ways to go in that department. Paper specs mean shit.