Qualcomm's Snapdragon 808/810: 20nm High-End 64-bit SoCs with LTE Category 6/7 Support in 2015
by Anand Lal Shimpi on April 7, 2014 7:30 AM EST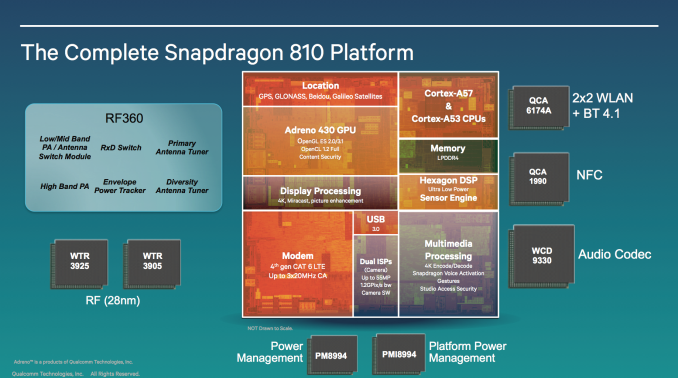
Today Qualcomm is rounding out its 64-bit family with the Snapdragon 808 and 810. Like the previous 64-bit announcements (Snapdragon 410, 610 and 615), the 808 and 810 leverage ARM's own CPU IP in lieu of a Qualcomm designed microarchitecture. We'll finally hear about Qualcomm's own custom 64-bit architecture later this year, but it's clear that all 64-bit Snapdragon SoCs shipping in 2014 (and early 2015) will use ARM CPU IP.
While the 410, 610 and 615 all use ARM Cortex A53 cores (simply varying the number of cores and operating frequency), the 808 and 810 move to a big.LITTLE design with a combination of Cortex A53s and Cortex A57s. The latter is an evolution of the Cortex A15, offering anywhere from a 25 - 55% increase in IPC over the A15. The substantial increase in performance comes at around a 20% increase in power consumption at 28nm. Thankfully both the Snapdragon 808 and 810 will be built at 20nm, which should help offset some of the power increase.
| Qualcomm's 64-bit Lineup | |||||||
| Snapdragon 810 | Snapdragon 808 | Snapdragon 615 | Snapdragon 610 | Snapdragon 410 | |||
| Internal Model Number | MSM8994 | MSM8992 | MSM8939 | MSM8936 | MSM8916 | ||
| Manufacturing Process | 20nm | 20nm | 28nm LP | 28nm LP | 28nm LP | ||
| CPU | 4 x ARM Cortex A57 + 4 x ARM Cortex A53 (big.LITTLE) | 2 x ARM Cortex A57 + 4 x ARM Cortex A53 (big.LITTLE) | 8 x ARM Cortex A53 | 4 x ARM Cortex A53 | 4 x ARM Cortex A53 | ||
| ISA | 32/64-bit ARMv8-A | 32/64-bit ARMv8-A | 32/64-bit ARMv8-A | 32/64-bit ARMv8-A | 32/64-bit ARMv8-A | ||
| GPU | Adreno 430 | Adreno 418 | Adreno 405 | Adreno 405 | Adreno 306 | ||
| H.265 Decode | Yes | Yes | Yes | Yes | No | ||
| H.265 Encode | Yes | No | No | No | No | ||
| Memory Interface | 2 x 32-bit LPDDR4-1600 | 2 x 32-bit LPDDR3-933 | 2 x 32-bit LPDDR3-800 | 2 x 32-bit LPDDR3-800 | 2 x 32-bit LPDDR2/3-533 | ||
| Integrated Modem | 9x35 core, LTE Category 6/7, DC-HSPA+, DS-DA | 9x35 core, LTE Category 6/7, DC-HSPA+, DS-DA | 9x25 core, LTE Category 4, DC-HSPA+, DS-DA | 9x25 core, LTE Category 4, DC-HSPA+, DS-DA | 9x25 core, LTE Category 4, DC-HSPA+, DS-DA | ||
| Integrated WiFi | - | - | Qualcomm VIVE 802.11ac 1-stream | Qualcomm VIVE 802.11ac 1-stream | Qualcomm VIVE 802.11ac 1-stream | ||
| eMMC Interface | 5.0 | 5.0 | 4.5 | 4.5 | 4.5 | ||
| Camera ISP | 14-bit dual-ISP | 12-bit dual-ISP | ? | ? | ? | ||
| Shipping in Devices | 1H 2015 | 1H 2015 | Q4 2014 | Q4 2014 | Q3 2014 | ||
The Snapdragon 808 features four Cortex A53s and two Cortex A57s, while the 810 moves to four of each. In both cases all six/eight cores can be active at once (Global Task Scheduling). The designs are divided into two discrete CPU clusters (one for the A53s and one for the A57s). Within a cluster all of the cores have to operate at the same frequency (a change from previous Snapdragon designs), but each cluster can operate at a different frequency (which makes sense given the different frequency targets for these two core types). Qualcomm isn't talking about cache sizes at this point, but I'm guessing we won't see anything as cool/exotic as a large shared cache between the two clusters. Although these are vanilla ARM designs, Qualcomm will be using its own optimized cells and libraries, which may translate into better power/performance compared to a truly off-the-shelf design.
The CPU is only one piece of the puzzle as the rest of the parts of these SoCs get upgraded as well. The Snapdragon 808 will use an Adreno 418 GPU, while the 810 gets an Adreno 430. I have no idea what either of those actually means in terms of architecture unfortunately (Qualcomm remains the sole tier 1 SoC vendor to refuse to publicly disclose meaningful architectural details about its GPUs). In terms of graphics performance, the Adreno 418 is apparently 20% faster than the Adreno 330, and the Adreno 430 is 30% faster than the Adreno 420 (100% faster in GPGPU performance). Note that the Adreno 420 itself is something like 40% faster than Adreno 330, which would make Adreno 430 over 80% faster than the Adreno 330 we have in Snapdragon 800/801 today.
Also on the video side: both SoCs boast dedicated HEVC/H.265 decode hardware. Only the Snapdragon 810 has a hardware HEVC encoder however. The 810 can support up to two 4Kx2K displays (1 x 60Hz + 1 x 30Hz), while the 808 supports a maximum primary display resolution of 2560 x 1600.
The 808/810 also feature upgraded ISPs, although once again details are limited. The 810 gets an upgraded 14-bit dual-ISP design, while the 808 (and below?) still use a 12-bit ISP. Qualcomm claims up to 1.2GPixels/s of throughput, putting ISP clock at 600MHz and offering a 20% increase in ISP throughput compared to the Snapdragon 805.
The Snapdragon 808 features a 64-bit wide LPDDR3-933 interface (1866MHz data rate, 15GB/s memory bandwidth). The 810 on the other hand features a 64-bit wide LPDDR4-1600 interface (3200MHz data rate, 25.6GB/s memory bandwidth). The difference in memory interface prevents the 808 and 810 from being pin-compatible. Despite the similarities otherwise, the 808 and 810 are two distinct pieces of silicon - the 808 isn't a harvested 810.
Both SoCs have a MDM9x35 derived LTE Category 6/7 modem. The SoCs feature essentially the same modem core as a 9x35 discrete modem, but with one exception: Qualcomm enabled support for 3 carrier aggregation LTE (up from 2). The discrete 9x35 modem implementation can aggregate up to two 20MHz LTE carriers in order to reach Cat 6 LTE's 300Mbps peak download rate. The 808/810, on the other hand, can combine up to three 20MHz LTE carriers (although you'll likely see 3x CA used with narrower channels, e.g. 20MHz + 5MHz + 5MHz or 20MHz + 10MHz + 10MHz).
Enabling 3x LTE CA requires two RF transceiver front ends: Qualcomm's WTR3925 and WTR3905. The WTR3925 is a single chip, 2x CA RF transceiver and you need the WTR3905 to add support for combining another carrier. Category 7 LTE is also supported by the hardware (100Mbps uplink), however due to operator readiness Qualcomm will be promoting the design primarily as category 6.
There's no integrated WiFi in either SoC. Qualcomm expects anyone implementing one of these designs to want to opt for a 2-stream, discrete solution such as the QCA6174.

Qualcomm refers to both designs as "multi-billion transistor" chips. I really hope we'll get to the point of actual disclosure of things like die sizes and transistor counts sooner rather than later (the die shot above is inaccurate).
The Snapdragon 808 is going to arrive as a successor to the 800/801, while the 810 sits above it in the stack (with a cost structure similar to the 805). We'll see some "advanced packaging" used in these designs. Both will be available in a PoP configuration, supporting up to 4GB of RAM in a stack. Based on everything above, it's safe to say that these designs are going to be a substantial upgrade over what Qualcomm offers today.
Unlike the rest of the 64-bit Snapdragon family, the 808 and 810 likely won't show up in devices until the first half of 2015 (410 devices will arrive in Q3 2014, while 610/615 will hit in Q4). The 810 will come first (and show up roughly two quarters after the Snapdragon 805, which will show up two quarters after the recently released 801). The 808 will follow shortly thereafter. This likely means we won't see Qualcomm's own 64-bit CPU microarchitecture show up in products until the second half of next year.
With the Snapdragon 808 and 810, Qualcomm rounds out almost all of its 64-bit lineup. The sole exception is the 200 series, but my guess is the pressure to move to 64-bit isn't quite as high down there.
What's interesting to me is just how quickly Qualcomm has shifted from not having any 64-bit silicon on its roadmap to a nearly complete product stack. Qualcomm appeared to stumble a bit after Apple's unexpected 64-bit Cyclone announcement last fall. Leaked roadmaps pointed to a 32-bit only future in 2014 prior to the introduction of Apple's A7. By the end of 2013 however, Qualcomm had quickly added its first 64-bit ARMv8 based SoC to the roadmap (Snapdragon 410). Now here we are, just over six months since the release of iPhone 5s and Qualcomm's 64-bit product stack seems complete. It'll still be roughly a year before all of these products are shipping, but if this was indeed an unexpected detour I really think the big story is just how quickly Qualcomm can move.
I don't know of any other silicon player that can move and ship this quickly. Whatever efficiencies and discipline Qualcomm has internally, I feel like that's the bigger threat to competing SoC vendors, not the modem IP.








101 Comments
View All Comments
Wilco1 - Monday, April 7, 2014 - link
No, however we know A57 is ~50% faster than A15. And we also know BT is already slower than A15, eg. 2.4GHz Z3770 barely outperforms 1.9GHz A15: http://browser.primatelabs.com/geekbench3/compare/... (that's with BT using hardware acceleration for AES).Mediatek says Q3 for some of its 64-bit cores, others are Q4. Not sure about Samsung. There is also NVidia of course, several benchmarks of Denver have been leaked, so launch must be near. As for the mobile version of BayTrail, the initial variants are relatively slow dual cores. I don't think they will be able to compete with existing 28nm Exynos, Tegra and Krait quad cores, let alone next-generation 20nm A57. Intel will need a completely new microarchitecture to compete or be relegated to mid and low-end.
smartypnt4 - Monday, April 7, 2014 - link
Those are all excellent points, and you may very well be correct in all of them.However, Intel's Cherry Trail (new microarchitecture codenamed Airmont) at 14nm is supposed to ship in 2014 for tablets and hit clocks of 2.7GHz (according to very, very sparse rumors). This will be what competes with the quad-A57 designs. No idea on Airmont's performance vs. Silvermont's, though (not even rumors). Intel's Moorefield (dual and quad Bay Trail for phones) will again be relegated to mid-tier status in Q3/Q4 of this year when the A57's launch. So while yes, Intel still will be substantially behind in phones, I don't think they're far behind at all in tablets, provided they can actually launch Cherry Trail in Q4 of this year, and provided Airmont provides a decent uptick in performance. But we shall see, I suppose.
Wilco1 - Monday, April 7, 2014 - link
Based on Anand, Cherry Trail is a shrink of Bay Trail to 14nm. Obviously there will be some performance tweaks, and a frequency gain to 2.7GHz seems plausible, but I'd be surprised if maximum performance increases by more than 20% - not enough to compete with Tegra K1, let alone Denver or A57. A Q4 release means it will be in the middle of the big wave of 64-bit ARM chips starting from Q3, so it may be leapfrogged before it is even released...2014 is certainly going to be an interesting tech year!
In any case, it looks like 2014 is going to be a very exciting tech year!
smartypnt4 - Monday, April 7, 2014 - link
I was under the impression that Airmont qualified as another "tock" in the roadmap due to Intel wanting to catch up, but I could be wrong there. Most of what I've seen seems to indicate that Airmont is closer to a "tock" than a pure "tick" in Intel's parlance. Then again, maybe I'm thinking of Willow Trail, which is the Goldmont microarchitecture, and is supposed to release somehow within 6-8 months of Cherry Trail. No idea, really. This fall is going to be incredibly jam-packed with stuff, though, what with Apple's new stuff that's rumored to use LPDDR4, Intel's Cherry Trail, Snapdragon 805 (not that interesting on the CPU side, but still), and especially NVIDIA's Project Denver.In any case, I'm more interested in seeing how 16 Broadwell EUs compete with the Adreno 420 and Tegra K1 on the GPU side.
2014 is indeed shaping up to be a very, very interesting year.
Gondalf - Monday, April 7, 2014 - link
Goldmond, a quarter after Airmontvirtual void - Monday, April 7, 2014 - link
Most benchmark sucks, especially for mobile units where the ability to react quickly to short burst are way more important for the perceived performance of the SoC than the maximum throughput.How do "we" know that A57 is ~50% faster than A15? I can "prove" that going to IA32 to Intel64 yields a 57% on Silvermont: compile this
http://benchmarksgame.alioth.debian.org/u32/progra...
program with gcc 4.8.1 with "-O3 -m32" and "-O3 -m64" on Silvermont machine running 64-bit version of Linux. The Intel64 version is 57% faster than the IA32, you can even get an additional 7% speed-up by using x32 ABI ("-O3 -mx32").
That is clearly not a typical performance increase, but Silvermont (for whatever reason) benefit more from IA32->Intel64 than the "big-core" models do.
If Cortex A57 is so fantastic, how come that AMD predicts its upcoming Cortex A57 microserver to have a lower SPECint score than Intels Avoton? Both are 8 core parts but Avoton has somewhat lower TDP.
http://www.anandtech.com/show/7724/it-begins-amd-a...
Wilco1 - Monday, April 7, 2014 - link
Anand quoted 25-55% in this article. I expect good gains from 64-bit just like A7 in Anand's review. You're right that Silvermont will likely show a slightly higher gain from 64-bit due to being register starved in 32-bit mode. Although we don't have good comparisons today, it doesn't mean we can't conclude that A57 will be significantly faster given the fact A15 already has significantly better IPC than Silvermont.Comparing SPEC is fraught with issues. Intel uses ICC which games several of the SPEC benchmarks resulting in huge speedups. While this results in great SPEC scores, it doesn't translate into real world performance (unless all your code is exactly like libquantum). So if you were hoping Avoton can somehow beat A57 then you're going to be very disappointed.
virtual void - Tuesday, April 8, 2014 - link
Ah, so what you claiming is that SPECInt is not relevant because running real programs like gcc, bzip2, perl-interpreter are all things that can be "fooled" by "compiler tricks" while real benchmarks like GeekBench really show the truth?You do realize that Geekbench include test like "stream copy" that look like this
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
something that gcc recognize and replace with a call to memcpy()... A little more complicated one is "stream scale"
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
b[j] = scalar*c[j];
where one for some reason decide to use floating point arithmetics (which do use x87-ops on IA32 but uses SSE2 on Intel64).
You can't be serious about Geekbench being more relevant than SPECint... Not that SPECint is very good at predicting how good/bad a CPU for mobile apps.
Wilco1 - Tuesday, April 8, 2014 - link
No, I am claiming that SPEC comparisons are more compiler trick contests rather than real CPU performance comparisons. I know as I've been writing compilers and doing benchmarking for decades now.If you compare SPEC compiled with the same GCC compiler with the same options used for ARM and Silvermont then you can get a good idea of the performance advantage of A15 or A57. If you use ICC than the 30-40% advantage it has on SPEC can completely hide any CPU performance difference. Then Intel obviously claims it has a huge performance advantage when it is solely the result of special optimizations in their ICC compiler. And as I said those special optimizations ONLY help SPEC, nothing else.
Geekbench does not suffer from this as it uses GCC and LLVM. Geekbench is not the best benchmark in the world, but at least it tries to give an HONEST indication of CPU performance, unlike what Intel is doing with SPEC.
virtual void - Tuesday, April 8, 2014 - link
The difference between ICC and gcc is minimal these days, even clang is very close. There are odd corner cases one could use to show that any of these three compilers is better or worse than the others. You cannot be serious in claiming that ICC can make things like the bzip2, gcc-compiler and perl-interpreter go fast via "compiler tricks", ICC doesn't those program any faster than gcc and if it did, then it would just be a superior compiler as we are talking about _real_ programs that solves _real_ problems.And come on, apart from Geekbench, point to any other benchmark/program where Z3770 does not clearly beat Tegra4 in CPU performance. How come that Geekbench, the only thing that seem to deviate, is the "one true benchmark"?
Ignoring other flaws, Geekbench and SPECint still both fail at being any good at predicting how good a CPU would be for mobile/tablet as they contain too much floating point tests (and Silvermont kind of suck at floating point by design, Intel know it is not important here and don't want to waste space on that).
I can understand that one would assume that A15 clearly beat Silvermont if one look at the microarchitechture, but people seem to forget/ignore just how much better Intel is at cache-design compared to any other CPU-designer right now. An we all know that cache is king!