A Look at Altera's OpenCL SDK for FPGAs
by Rahul Garg on October 9, 2013 8:00 AM EST
Efficiency vs flexibility is one of the fundamental tradeoffs in any engineering discipline and it is true in computer architecture as well. For any given task, for example video decode, dedicated hardware is a more power-efficient solution than writing a software decoder that runs on a general purpose processor such as the CPU, or even a GPU's SIMD arrays. Chips designed for a specific purpose are called Application Specific ICs or ASICs. However, designing and manufacturing ASICs is obviously difficult and once a chip is deployed, you cannot use the dedicated silicon area to anything else.
FPGAs, or field programmable gate arrays, fall somewhere between general purpose processors such as CPUs and ASICs in the spectrum of programmability and efficiency. FPGAs consist of a large array of logic blocks and memory cells. The logic blocks are typically small programmable lookup tables that can be used to compute simple logic functions. The connections between the cells are also reconfigurable. Multiple programmable logic blocks and the connections can be configured to create more complex units such as ALUs.
You can utilize the reconfigurability of the FPGA to convert it into a computing device specialized for your application. For example, consider an algorithm that is only performing certain types of integer arithmetic. In this case, you can reconfigure the FPGA to act as a large set of integer ALUs with support for the integer operations needed by your application. There is no need to waste any logic cells on floating point logic, and further the integer ALU can be custom for your application instead of a generic unit. Thus, for some applications, an FPGA implementation can often offer much higher performance/watt than a CPU or a GPU implementation of the same algorithm. The efficiency of FPGAs comes partly from the fact that the hardware is reconfigured for your application.
In turn, the integer units in your FPGA will likely not be as efficient (power or area-wise) as an ASIC specifically designed and optimized for your application. However, unlike an ASIC, if you decide to tweak your algorithm in the future, you can simply reflash your FPGA with the new program rather than going to the drawing board again to design, validate and manufacture new ASICs while throwing out the old ones. Some FPGAs even allow for dynamic partial reconfiguration, where one part of the FPGA is reprogrammed while the other part is still active.
However, programming FPGAs has traditionally been difficult and requires expertise in specialized "hardware description languages" (HDLs) like VHDL or Verilog. Some other options, such as SystemC, have also remained somewhat niche. There has been considerable interest in easier tools for programming FPGAs and this is where OpenCL comes in. OpenCL is considerably easier to learn and use than tools like VHDL and Verilog thus addressing one of the traditional weakenesses of FPGAs. Further, there is already university courses and industrial workshops teaching heterogeneous programming concepts in OpenCL or similar languages like CUDA or C++ AMP and thus the number of programmers familiar with OpenCL concepts is increasing quite rapidly.
While experts will likely continue using HDLs, OpenCL will enable many more programmers to use FPGAs. Even HDL experts may use OpenCL as a quick way to prototype their ideas on an FPGA. Interestingly, Xilinx (the biggest FPGA vendor currently) has recently also announced that they are working to bring OpenCL for their FPGAs in the future but no timeline has been announced. In this article we are looking at Altera's OpenCL offering which is already available and shipping. I will add one caveat before proceeding further. My own expertise and experience is primarily in using OpenCL (and similar APIs) on GPUs and CPUs, and not in FPGA or HDLs. You can think of this article as CPU/GPU programmer's view of the FPGA world. I don't have first-hand experience with Altera's SDK yet. This article is based upon my reading of the Altera documentation and whitepapers as well as various FPGA related literature around the web. The folks from Altera were also a big help for this article, as they were able to get answers for many of my questions.
Altera's Products and Roadmap
Altera designs and manufactures FPGA chips and these chips are then sold to partners and clients. CPU and GPU companies typically have multiple products differing in specificatons such as number of cores, frequency, features, memory interfaces etc. Similarly, Altera offers multiple product lines and multiple products within each line. Products are differentiated along specifications such as the number of adaptive logic modules (ALMs), the type and size of on-chip memory and external I/O bandwidth. FPGA vendors have also started including some additional programmable processors on-chip. For example, some of Altera's Stratix V FPGAs integrate DSP blocks on chip and Cyclone V FPGAs integrate ARM CPU cores on-chip. FPGAs may also have high-speed transceivers on-chip to connect to external I/O devices such as video cameras, medical imaging devices, network devices and high-speed storage devices. Networking and high-speed streaming/filtering type applications are particularly suited for such devices.
A block diagram of Altera's Stratix V FPGA (source) showing the core logic fabric with logic blocks and interconnects, on-chip memory (m20k blocks), DSP blocks, transceivers and other I/O interfaces is shown below:
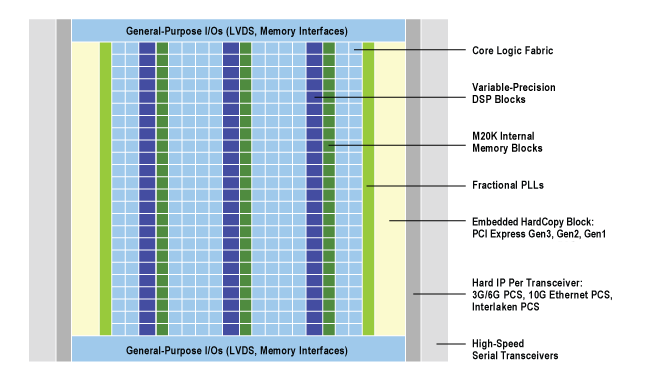
Altera partners will design a product, for example a PCIe based board, around the FPGA and may add their own customizations such as I/O interfaces supported on the board, peripherals as well as the size and bandwidth of associated onboard memory (if any). PCIe based boards are far from the only way to deploy FPGAs and some customers may choose a custom solution. However, we will focus on the PCIe based use case for this article.
Altera's current generation high-end product line is under the brand Stratix V and is currently their only product series to support OpenCL. Stratix V series is currently built on a 28nm process at TSMC. Interestingly, FPGA manufacturs are typically one of the first products to adopt new process technologies. Altera's 28nm products started shipping well before the first 28nm GPUs or mobile CPUs. Altera has also announced 20nm products (branded Arria 10). Significantly, Altera has announced a deal with Intel to fabricate their upcoming Stratix 10 branded 14nm FPGAs in Intel's manufacturing facilities.
Altera introduced a private beta for OpenCL on FPGAs late last year. The SDK has now been made public. Altera's implementation is built on top of OpenCL 1.0 but offers custom extensions to tap into the unique features of FPGAs. More information can be found on Altera's OpenCL page. They are also adopting some features, such as pipes, from the OpenCL 2.0 provisional spec. From a performance standpoint, Altera has posted whitepapers where they show that FPGAs offer much higher performance/watt on some applications compared to CPUs and GPUs. Typical FPGA board power used in Altera's studies is somewhere in the range of 20W which is much lower than the high-end discrete GPUs such as Tesla series GPUs which are often in the 200W range. Altera claims that OpenCL running on an FPGA will either outperform the GPU or match its performance at considerably lower power on some applications. Altera does not claim that this will be true for every application but I do think it is a reasonable claim for some types of applications.
We will go into some OpenCL terminology and how the concepts map to FPGAs. Next we will look at some details of Altera's OpenCL implementation and finally I will offer some concluding remarks.








56 Comments
View All Comments
ET - Tuesday, October 15, 2013 - link
Thanks. That's enlightening. Doesn't support a lot of stuff. (And the table is on page 22 in the document I found.)jarjarbink - Tuesday, February 25, 2014 - link
Can you point a link to the document ?DonnaCabel16 - Monday, October 14, 2013 - link
my Aunty Aaliyah just got an awesome 9 month old Audi allroad Wagon by working parttime from the internet... pop over to this web-site ℰxit35.commike8675309 - Monday, October 14, 2013 - link
I've been following FPGA's for the past 9 months or so and have also been stymied by the costs. Most recently I have been following the development of the Parallella which was a kickstarter project "supercomputer on a chip" development board. While not exactly a FPGA, it does have supporting Zynq-7000 Series Dual-core ARM A9 that has FPGA logic. And the main chip contains 16 cores that can operate concurrently on shared or different workloads. Not very mature for development yet, but OpenCL is one of the languages being targeted for it.0xc000005 - Saturday, October 19, 2013 - link
You didn't mention (afaict) one of the big benefits of using FPGAs - they require much less power (~ 10x less) than GPUs for the same amount of computation. Some readers may find this useful if they want to do gigantic computations under some type of cost constraint. Bitcoin miners moved from GPUs to FPGAs long ago since the cost of electricity is an important factor in Bitcoin mining.OpenCL isn't the only game in town for programming FPGAs either. Xilinx (Altera's main competitor) has a nice product called Vivado High-Level Synthesis where you can write your algorithms in C++. Whether this is a benefit or not remains to be seen - it's harder to design parallel algorithms in C++ than in OpenCL. It's important to be aware that there are a lot of algorithms that are not massively parallel, for which GPUs and OpenCL offer no speedup. This is where C++ is useful, since Vivado can take your sequential, easy-to-simulate algorithm and still make it N times faster - the value of N depends on your algorithm of course.
More about which algorithms can be speeded up using OpenCL can be found at http://www.hpcwire.com/hpcwire/2013-10-14/reprisin...
chaos215bar2 - Sunday, October 20, 2013 - link
Use of local memory in OpenCL generally also requires some kind of synchronization between the threads in a workgroup, as the entire point is to share information between these threads. (A basic example is loading some data into local memory so that all threads can operate on it. A synchronization point is necessary to ensure that all threads have loaded the data they're responsible for before any others attempt to use it.)I'm curious how Altera handles this, since it doesn't map to the pipeline model you described in an obvious way. If, for instance, there's only room for n instances (via vectorization or replication) of the pipeline on the FPGA, does that mean the workgroup size is n? If not, how is the state of one thread saved while waiting for others to reach the synchronization point, and then subsequently restored?