Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
The most frustrating part about covering Intel’s journey into mobile over the past five years is just how long it’s taken to get here. The CPU cores used in Medfield, Clover Trail and Clover Trail+ are very similar to what Intel had with the first Atom in 2008. Obviously we’re dealing with higher levels of integration and tweaks for further power consumption, but the architecture and much of the core remains unchanged. Just consider what that means. A single Bonnell core, designed in 2004, released in 2008, is already faster than ARM’s Cortex A9. Intel had this architecture for five years now and from the market’s perspective, did absolutely nothing with it. You could argue that the part wasn’t really ready until Intel had its 32nm process, so perhaps we’ve only wasted 3 years (Intel debuted its 32nm process in 2010). It’s beyond frustrating to think about just how competitive Intel would have been had it aggressively pursued this market.
Today Intel is in a different position. After acquisitions, new hires and some significant internal organizational changes, Intel seems to finally have the foundation to iterate and innovate in mobile. Although Bonnell (the first Atom core) was the beginning of Intel’s journey into mobile, it’s Silvermont - Intel’s first new Atom microarchitecture since 2008 - that finally puts Intel on the right course.
Although Silvermont can find its way into everything from cars to servers, the architecture is primarily optimized for use in smartphones and then in tablets, in that order. This is a significant departure from the previous Bonnell core that was first designed to serve the now defunct Mobile Internet Devices category that Intel put so much faith in back in the early to mid 2000s. As Intel’s first Atom architecture designed for mobile, expectations are high for Silvermont. While we’ll have to wait until the end of the year to see Silvermont in tablets (and early next year for phones), the good news for Intel is that Silvermont seems competitive right out of the gate. The even better news is that Silvermont will only be with us for a year before it gets its first update: Airmont.
 Intel made this announcement last year, but Silvermont is the beginning of Intel’s tick-tock cadence for Atom. Intel plans on revving Atom yearly for at least the next three years. Silvermont introduces a new architecture, while Airmont will take that architecture and bring it down to 14nm in 2014/2015. One year later, we’ll see another brand new architecture take the stage also on 14nm. This is a shift that Intel needed to implement years ago, but it’s still not too late.
Intel made this announcement last year, but Silvermont is the beginning of Intel’s tick-tock cadence for Atom. Intel plans on revving Atom yearly for at least the next three years. Silvermont introduces a new architecture, while Airmont will take that architecture and bring it down to 14nm in 2014/2015. One year later, we’ll see another brand new architecture take the stage also on 14nm. This is a shift that Intel needed to implement years ago, but it’s still not too late.
Before we get into an architectural analysis of Silvermont, it’s important to get some codenames in order. Bonnell was the name of the original 45nm Atom core, it was later shrunk to 32nm and called Saltwell when it arrived in smartphones and tablets last year. Silvermont is the name of the CPU core alone, but when it shows up in tablets later this year it will do so as a part of the Baytrail SoC and a part of the Merrifield SoC next year in smartphones.
22nm
To really understand the Silvermont story, you need to first understand Intel’s 22nm SoC process. Two years ago Intel announced its 22nm tri-gate 3D transistors, which would eventually ship a year later in Intel’s Ivy Bridge processors. That process wasn’t suited for ultra mobile. It was optimized for the sort of high performance silicon that was deployed on it, but not the ultra compact, very affordable, low power silicon necessary in smartphones and tablets. A derivative of that process would be needed for mobile. Intel now makes two versions of all of its processes, one optimized for its high performance CPUs and one for low power SoCs. P1270 was the 22nm CPU process, and P1271 is the low power SoC version. Silvermont uses P1271. The high level characteristics are the same however. Intel’s 22nm process moves to tri-gate non-planar transistors that can significantly increase transistor performance and/or decrease power.

This part is huge. The move to 22nm 3D transistors lets Intel drop threshold voltage by approximately 100mV at the same leakage level. Remember that power scales with the square of voltage, so a 100mV savings depending on what voltage you’re talking about can be very huge. Intel’s numbers put the power savings at anywhere from 25 - 35% at threshold voltage. The gains don’t stop there either. At 1V, Intel’s 22nm process gives it an 18% improvement in transistor performance or at the same performance Intel can run the transistors at 0.8V - a 20% power savings. The benefits are even more pronounced at lower voltages: 37% faster performance at 0.7V or less than half the active power at the same performance.
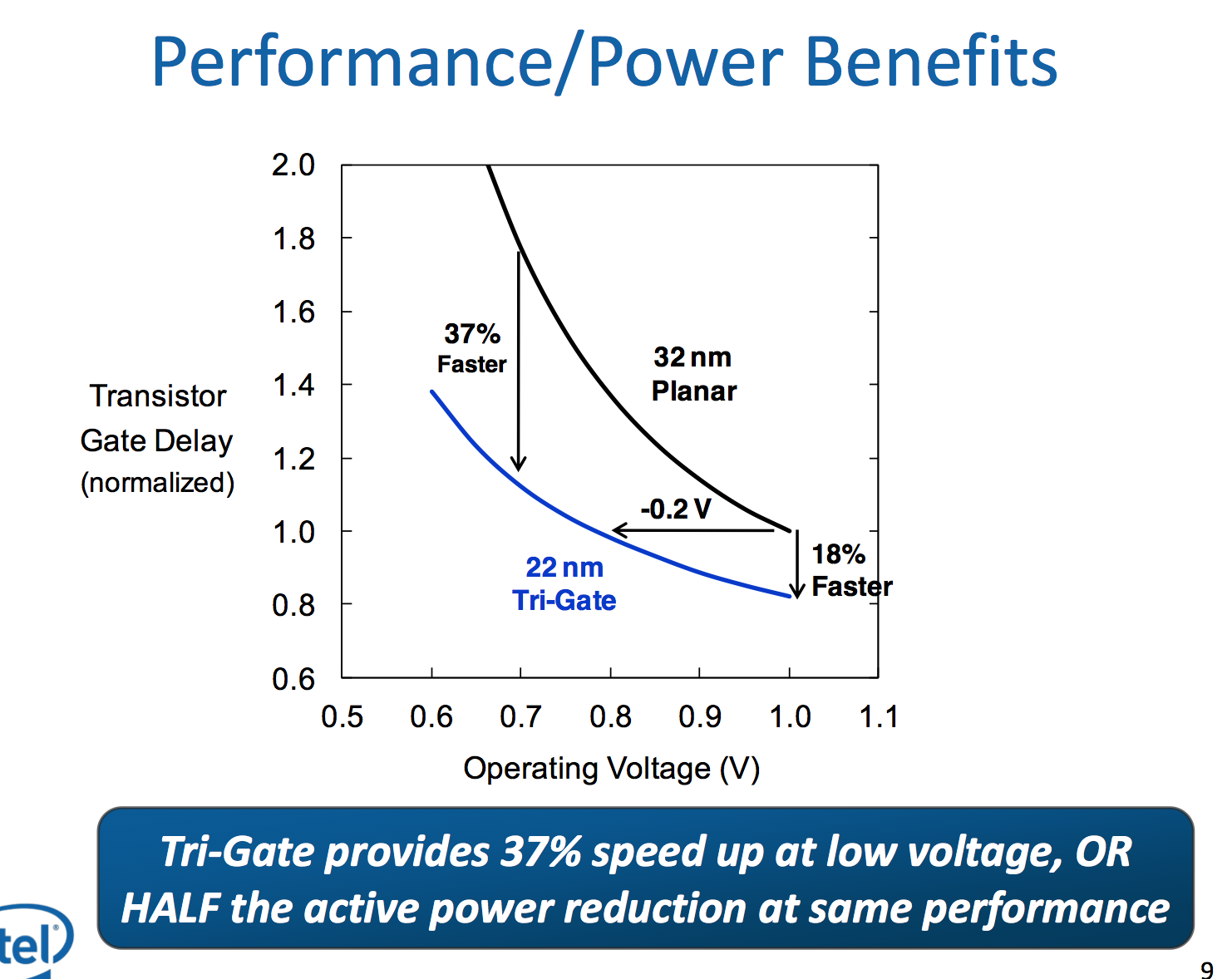
The end result here is Intel can scale frequency and/or add more active logic without drawing any more power than it did at 32nm. This helps at the top end with performance, but the vast majority of the time mobile devices are operating at very lower performance and power levels. Where performance doesn’t matter as much, Intel’s 22nm process gives it an insane advantage.
If we look back at our first x86 vs. ARM performance data we get a good indication of where Intel’s 32nm process had issues and where we should see tangible improvements with the move to 22nm:
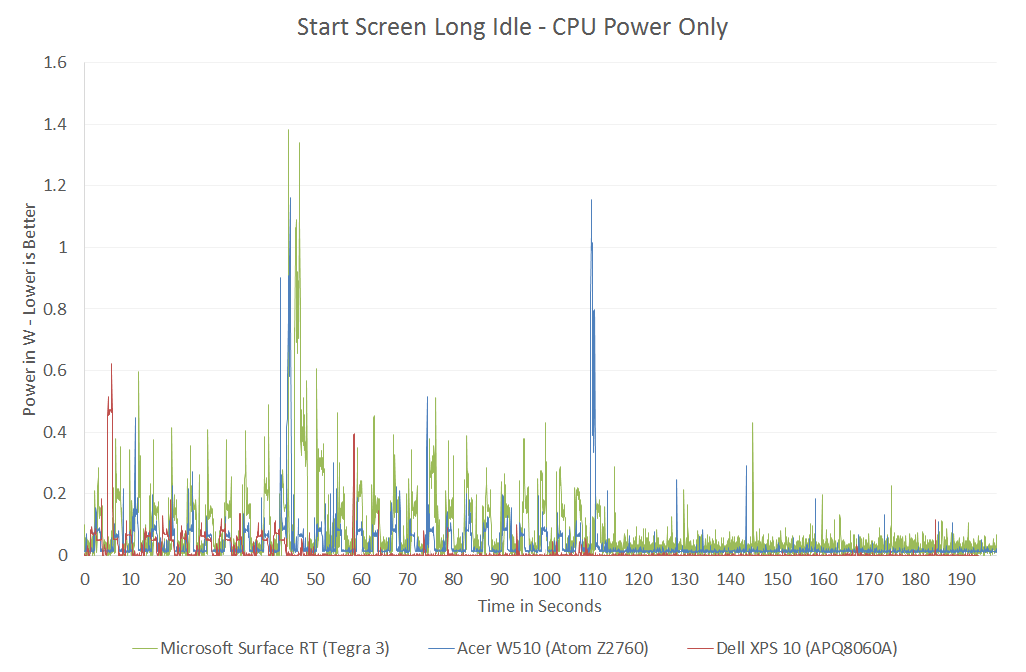
Qualcomm’s 28nm Krait 200 was actually able to get down to lower power levels than Intel could at 32nm. Without having specific data I can’t say for certain, but it’s extremely likely that with Silvermont Intel will be able to drive down to far lower power levels than anything we’ve ever measured.
Understanding what Intel’s 22nm process gives it is really key to understanding Silvermont.








174 Comments
View All Comments
Homeles - Monday, May 6, 2013 - link
Yay confirmation bias!R0H1T - Tuesday, May 7, 2013 - link
Nay, you fanboi(Intel's) much ?powerarmour - Monday, May 6, 2013 - link
Have to agree, starting to get tired of these almost Intel PR based previews. No mention to how poor Intel's graphics drivers have consistently been over many many years.Homeles - Monday, May 6, 2013 - link
"You can't make the ridiculous claims of 1.6x performance."Sure you can. It was already a close race between a 5 year old architecture and a brand new one. The floodgates have opened -- this is 5 years of pent up performance gains from the largest R&D spender in the industry, on top of being on a significantly superior process for mobile devices.
Wilco1 - Monday, May 6, 2013 - link
Absolute performance of Silvermont cannot be higher than A15 or Bobcat, it's just 2-way OoO, has a single-issue in-order memory pipeline (no speculative execution of memory operations or dual issue of load-store like A15/Bobcat) and fairly small buffers in general. All in all it is more like A9 than A15 or Bobcat/Jaguar.althaz - Monday, May 6, 2013 - link
Except that it certainly can (dependent on a lot of other factors)...That said, I suspect it will only be faster at the same power level, not at the same frequency.
beginner99 - Tuesday, May 7, 2013 - link
That's covered in the article but I must admit I don't fully understand it. Anyway Anand writes about macro-op fusion and clearly states that because of this the 2-wide is misleading when directly comparing to ARM. My interpretation being that ARM doesn't have this and if your 2-wide CPU is running macro-ops with 2 instructions in them it's actually like 4-wide (but I guess this naive viewpoint of mine is completely wrong.Wilco1 - Tuesday, May 7, 2013 - link
No, macro-ops don't make your CPU magically wider. For example Silvermont cannot actually execute 2 load+op instructions every cycle, and cannot even execute 1 read-modify-write every cycle...Also note that most ARM CPUs do have similar capabilities, for example Cortex-A9 can execute 2 shifts and 2 ALU instructions every cycle, and loads and stores can have base update for free. So Anand is quite wrong claiming this is an advantage to Atom.
As I mentioned, the big bottleneck of Silvermont is it's single load/store unit. Typical code contains many loads and stores, and Cortex-A15 can execute these twice as fast as Silvermont.
Jaybus - Wednesday, May 8, 2013 - link
It can, however, execute 1 load and 1 store simultaneously, and that is its saving grace. That fits very well with code being executed in OoO fashion and why I doubt very much A15 is twice as fast executing typical code.Wilco1 - Thursday, May 9, 2013 - link
No Silvermont can only execute 1 load or 1 store per cycle. A15 won't be twice as fast on typical code, but it will beat Silvermont on memory intensive code due to its single memory pipeline bottleneck.