NVIDIA's GeForce GTX 580: Fermi Refined
by Ryan Smith on November 9, 2010 9:00 AM ESTGF110: Fermi Learns Some New Tricks
We’ll start our in-depth look at the GTX 580 with a look at GF110, the new GPU at the heart of the card.
There have been rumors about GF110 for some time now, and while they ultimately weren’t very clear it was obvious NVIDIA would have to follow up GF100 with something else similar to it on 40nm to carry them through the rest of the processes’ lifecycle. So for some time now we’ve been speculating on what we might see with GF100’s follow-up part – an outright bigger chip was unlikely given GF100’s already large die size, but NVIDIA has a number of tricks they can use to optimize things.
Many of those tricks we’ve already seen in GF104, and had you asked us a month ago what we thought GF110 would be, we were expecting some kind of fusion of GF104 and GF100. Primarily our bet was on the 48 CUDA Core SM making its way over to a high-end part, bringing with it GF104’s higher theoretical performance and enhancements such as superscalar execution and additional special function and texture units for each SM. What we got wasn’t quite what we were imagining – GF110 is much more heavily rooted in GF100 than GF104, but that doesn’t mean NVIDIA hasn’t learned a trick or two.
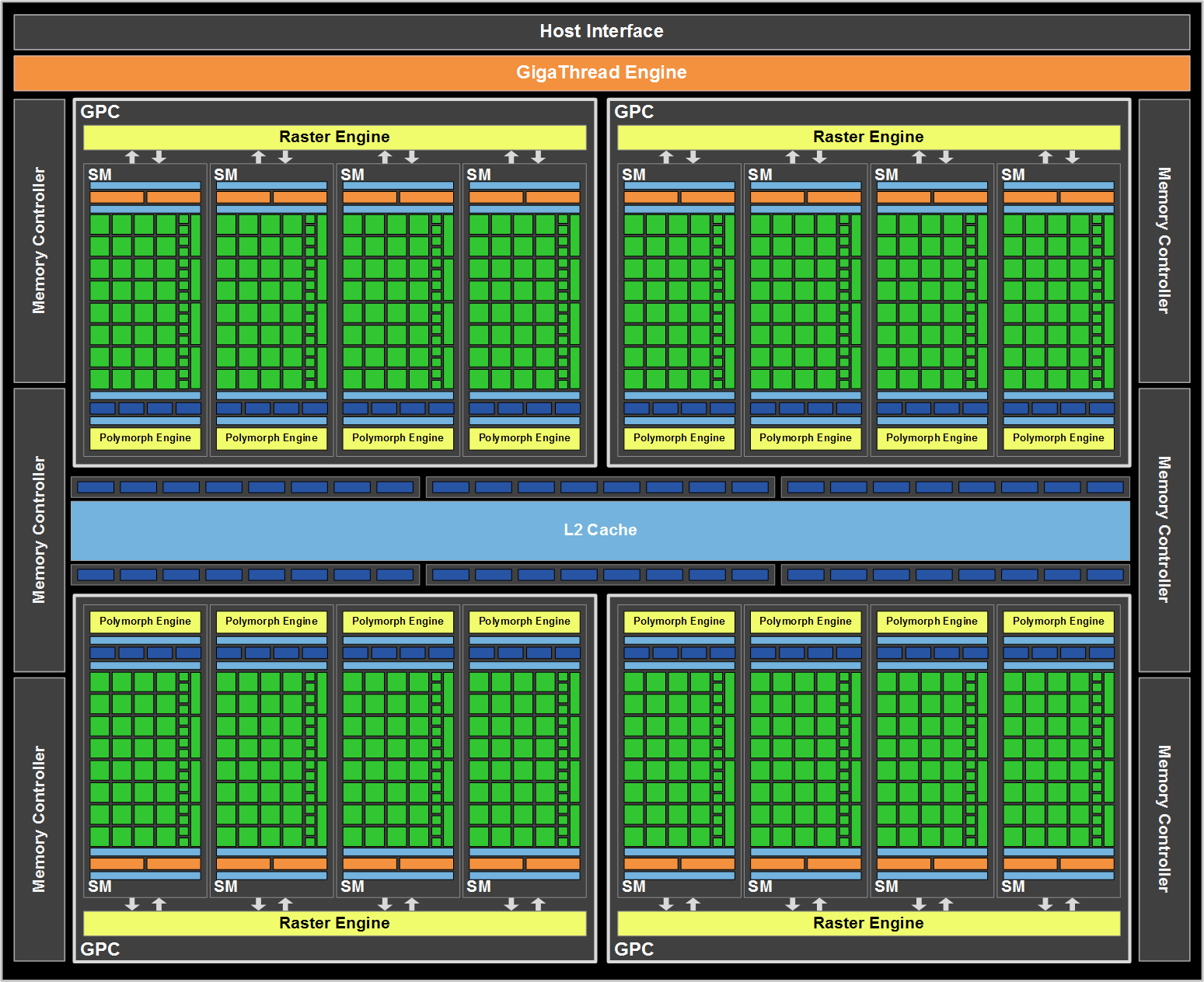
Fundamentally GF110 is the same architecture as GF100, especially when it comes to compute. 512 CUDA Cores are divided up among 4 GPCs, and in turn each GPC contains 1 raster engine and 4 SMs. At the SM level each SM contains 32 CUDA cores, 16 load/store units, 4 special function units, 4 texture units, 2 warp schedulers with 1 dispatch unit each, 1 Polymorph unit (containing NVIDIA’s tessellator) and then the 48KB+16KB L1 cache, registers, and other glue that brought an SM together. At this level NVIDIA relies on TLP to keep a GF110 SM occupied with work. Attached to this are the ROPs and L2 cache, with 768KB of L2 cache serving as the guardian between the SMs and the 6 64bit memory controllers. Ultimately GF110’s compute performance per clock remains unchanged from GF100 – at least if we had a GF100 part with all of its SMs enabled.
On the graphics side however, NVIDIA has been hard at work. They did not port over GF104’s shader design, but they did port over GF104’s texture hardware. Previously with GF100, each unit could compute 1 texture address and fetch 4 32bit/INT8 texture samples per clock, 2 64bit/FP16 texture samples per clock, or 1 128bit/FP32 texture sample per clock. GF104’s texture units improved this to 4 samples/clock for 32bit and 64bit, and it’s these texture units that have been brought over for GF110. GF110 can now do 64bit/FP16 filtering at full speed versus half-speed on GF100, and this is the first of the two major steps NVIDIA took to increase GF110’s performance over GF100’s performance on a clock-for-clock basis.
| NVIDIA Texture Filtering Speed (Per Texture Unit) | |||||
| GF110 | GF104 | GF100 | |||
| 32bit (INT8) | 4 Texels/Clock | 4 Texels/Clock | 4 Texels/Clock | ||
| 64bit (FP16) | 4 Texels/Clock | 4 Texels/Clock | 2 Texels/Clock | ||
| 128bit (FP32) | 1 Texel/Clock | 1 Texel/Clock | 1 Texel/Clock | ||
Like most optimizations, the impact of this one is going to be felt more on newer games than older games. Games that make heavy use of 64bit/FP16 texturing stand to gain the most, while older games that rarely (if at all) used 64bit texturing will gain the least. Also note that while 64bit/FP16 texturing has been sped up, 64bit/FP16 rendering has not – the ROPs still need 2 cycles to digest 64bit/FP16 pixels, and 4 cycles to digest 128bit/FP32 pixels.
It’s also worth noting that this means that NVIDIA’s texture:compute ratio schism remains. Compared to GF100, GF104 doubled up on texture units while only increasing the shader count by 50%; the final result was that per SM 32 texels were processed to 96 instructions computed (seeing as how the shader clock is 2x the base clock), giving us 1:3 ratio. GF100 and GF110 on the other hand retain the 1:4 (16:64) ratio. Ultimately at equal clocks GF104 and GF110 widely differ in shading, but with 64 texture units total in both designs, both have equal texturing performance.
Moving on, GF110’s second trick is brand-new to GF110, and it goes hand-in-hand with NVIDIA’s focus on tessellation: improved Z-culling. As a quick refresher, Z-culling is a method of improving GPU performance by throwing out pixels that will never be seen early in the rendering process. By comparing the depth and transparency of a new pixel to existing pixels in the Z-buffer, it’s possible to determine whether that pixel will be seen or not; pixels that fall behind other opaque objects are discarded rather than rendered any further, saving on compute and memory resources. GPUs have had this feature for ages, and after a spurt of development early last decade under branded names such as HyperZ (AMD) and Lightspeed Memory Architecture (NVIDIA), Z-culling hasn’t been promoted in great detail since then.

Z-Culling In Action: Not Rendering What You Can't See
For GF110 this is changing somewhat as Z-culling is once again being brought back to the surface, although not with the zeal of past efforts. NVIDIA has improved the efficiency of the Z-cull units in their raster engine, allowing them to retire additional pixels that were not caught in the previous iteration of their Z-cull unit. Without getting too deep into details, internal rasterizing and Z-culling take place in groups of pixels called tiles; we don’t believe NVIDIA has reduced the size of their tiles (which Beyond3D estimates at 4x2); instead we believe NVIDIA has done something to better reject individual pixels within a tile. NVIDIA hasn’t come forth with too many details beyond the fact that their new Z-cull unit supports “finer resolution occluder tracking”, so this will have to remain a mystery for another day.
In any case, the importance of this improvement is that it’s particularly weighted towards small triangles, which are fairly rare in traditional rendering setups but can be extremely common with heavily tessellated images. Or in other words, improving their Z-cull unit primarily serves to improve their tessellation performance by allowing NVIDIA to better reject pixels on small triangles. This should offer some benefit even in games with fewer, larger triangles, but as framed by NVIDIA the benefit is likely less pronounced.
In the end these are probably the most aggressive changes NVIDIA could make in such a short period of time. Considering the GF110 project really only kicked off in earnest in February, NVIDIA only had around half a year to tinker with the design before it had to be taped out. As GPUs get larger and more complex, the amount of tweaking that can get done inside such a short window is going to continue to shrink – and this is a far cry from the days where we used to get major GPU refreshes inside of a year.








160 Comments
View All Comments
cjb110 - Tuesday, November 9, 2010 - link
"The thermal pads connecting the memory to the shroud have once again wiped out the chip markets", wow powerful adhesive that! Bet Intel's pissed.cjb110 - Tuesday, November 9, 2010 - link
"While the difference is’ earthshattering, it’s big enough..." nt got dropped, though not yet at my workplace:)Invader Mig - Tuesday, November 9, 2010 - link
I don't know the stance on posting links to other reviews since I'm a new poster, so I wont. I would like to make note that in another review they claim to have found a work around the power throttling that allowed them to use furmark to get accurate temps and power readings. This review has the 580 at 28w above the 480 at max load. I don't mean to step on anyone's toe's, but I have seen so many different numbers because of this garbage nvidia has pulled, and the only person who claims to have furmark working gets higher numbers. I would really like to see something definitive.7Enigma - Tuesday, November 9, 2010 - link
Here's my conundrum. What is the point of something like Furmark that has no purpose except to overstress a product? In this case the 580 (with modified X program) doesn't explode and remains within some set thermal envelope that is safe to the card. I like using Crysis as it's a real-world application that stresses the GPU heavily.Until we have another game/program that is used routinely (be it game or coding) that surpasses the heat generation and power draw of Crysis I just don't see the need to try to max out the cards with a benchmark. OC your card to the ends of the earth and run something real, that is understandable. But just using a program that has no real use to artificially create a power draw just doesn't have any benefit IMO.
Gonemad - Tuesday, November 9, 2010 - link
I beg to differ. (be careful, high doses of flaming.)Let me put it like this. The Abrams M1 Tank is tested on a 60º ramp (yes, that is sixty degrees), where it must park. Just park there, hold the brakes, and then let go. It proves the brakes on a 120-ton 1200hp vehicle will work. It is also tested on emergency brakes, where this sucker can pull a full stop from 50mph on 3 rubber-burning meters. (The treads have rubber pads, for the ill informed).
Will ever a tank need to hold on a 60º ramp? Probably not. Would it ever need to come to a screeching halt in 3 meters? In Iraqi, they probably did, in order to avoid IEDs. But you know, if there were no prior testing, nobody would know.
I think there should be programs specifically designed to stress the GPU in unintended ways, and it must protect itself from destruction, regardless of what code is being thrown at it. NVIDIA should be grateful somebody pointed that out to them. AMD was thankful when they found out the 5800 series GPUs (and others, but this was worse) had lousy performance on 2D acceleration, or none at all, and rushed to fix its drivers. Instead, NVIDIA tries to cheat Furmark by recognizing its code and throttling. Pathetic.
Perhaps someday, a scientific application may come up with repeatable math operations that just behave exactly like Furmark. So, out of the blue, you got a $500 worth of equipment that gets burned out, and nobody can tell why??? Would you like that happening to you? Wouldn't you like to be informed that this or that code, at least, could destroy your equipment?
What if Furmark wasn't designed to stress GPUs, but it was an actual game, (with furry creatures, lol)?
Ever heard of Final Fantasy XIII killing off PS3s for good, due to overload, thermal runaway, followed by meltdown? Rumors are there, if you believe them is entirely to you.
Ever heard of Nissan GTR (skyline) being released with a top-speed limiter with GPS that unlocks itself when the car enters the premises of Nissan-approved racetracks? Inherent safety, or meddling? Can't you drive on a Autoban at 300km/h?
Remember back in the day of early benchmark tools, (3DMark 2001 if I am not mistaken), where the Geforce drivers detected the 3DMark executable and cheated the hell out of the results, and some reviewers got NVIDIA red-handed when they renamed and changed the checksum of the benchmark??? Rumors, rumors...
The point is, if there is a flaw, a risk of an unintended instruction kill the hardware, the buyer should be rightfully informed of such conditions, specially if the company has no intention at all to fix it. Since Anand warned us, they will probably release the GTX 585 with full hardware thermal safeties. Or new drivers. Or not.
Just like the instruction #PROCHOT was inserted in the Pentium (which version?) and some reviewers tested it against an AMD chip. I never forgot that AMD processor billowing blue smoke the moment the heatsink was torn off. Good PR, bad PR. The video didn´t look fake to me back then, just unfair.
In the end, it becomes matter of PR. If suddenly all the people that played Crysis on this card caused it to be torched, we would have something really interesting.
Sihastru - Tuesday, November 9, 2010 - link
AMD has a similar system in place since the HD4xx0 generation. Remember when Furmark used to blow up 48x0 cards? Of course not. But look it up...What nVidia did here is what AMD has in all their mid/high end cards since HD4xx0. At least nVidia will only throttle when it detects Furmark/OCCT. AMD cards will throttle in any situation if the power limiter requires it.
JimmiG - Tuesday, November 9, 2010 - link
It's a very unfortunate situation that both companies are to blame for. That's what happens when you push the limits of power consumption and heat output too far while at the same time trying to keep manufacturing costs down.The point of a stress test is to push the system to the very limit (but *not* beyond it, like AMD and Nvidia would have you believe). You can then be 100% assured that it will run all current and future games and HPC applications, not matter what unusual workloads they dump on your GPU or CPU, without crashes or reduced performance.
cactusdog - Tuesday, November 9, 2010 - link
So if you want to use multiple monitors do you still need 2 cards to run it or have they enabled a third monitor on the 580?Sihastru - Tuesday, November 9, 2010 - link
Yes.Haydyn323 - Tuesday, November 9, 2010 - link
The 580 as with the previous generation still only supports 2 monitors max per card.