The Intel Core i7-12700K and Core i5-12600K Review: High Performance For the Mid-Range
by Gavin Bonshor on March 29, 2022 8:00 AM ESTCPU Benchmark Performance: Legacy and Web
In order to gather data to compare with older benchmarks, we are still keeping a number of tests under our ‘legacy’ section. This includes all the former major versions of CineBench (R15, R11.5, R10) as well as x264 HD 3.0 and the first very naïve version of 3DPM v2.1. We won’t be transferring the data over from the old testing into Bench, otherwise, it would be populated with 200 CPUs with only one data point, so it will fill up as we test more CPUs like the others.
The other section here is our web tests.
We are using DDR5 memory at the following settings:
- DDR5-4800(B) CL40
Legacy
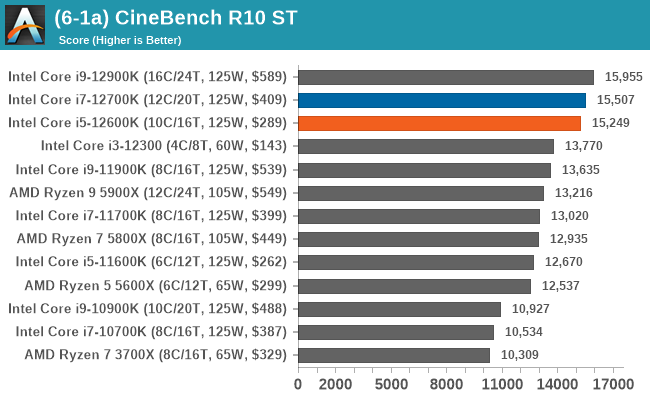
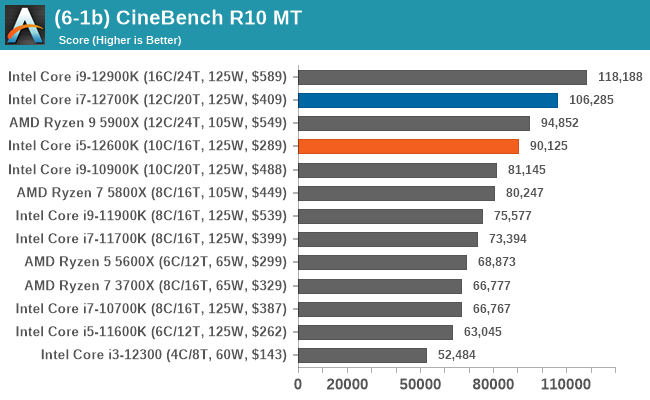
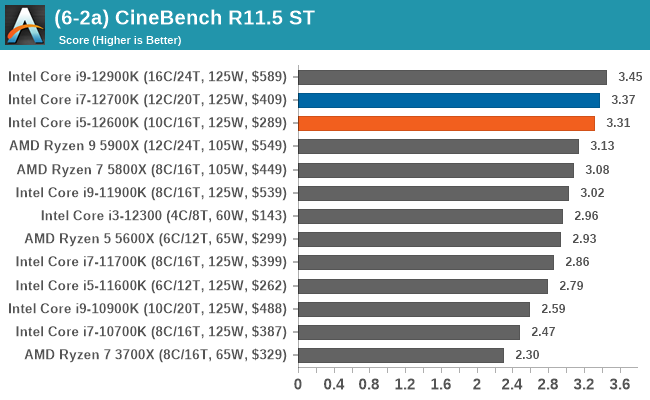
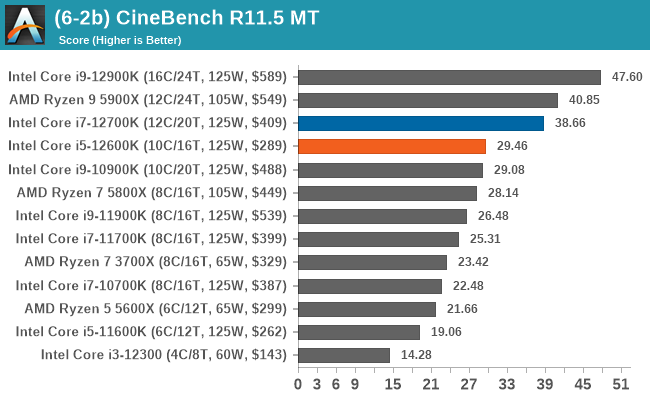
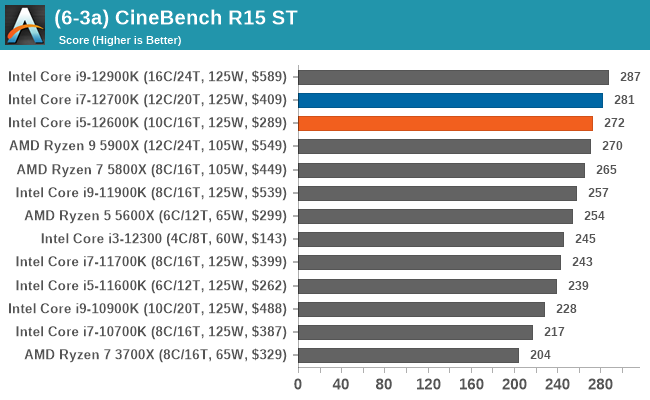
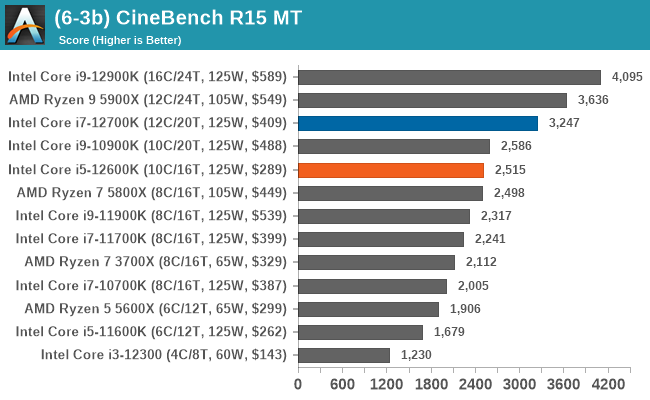
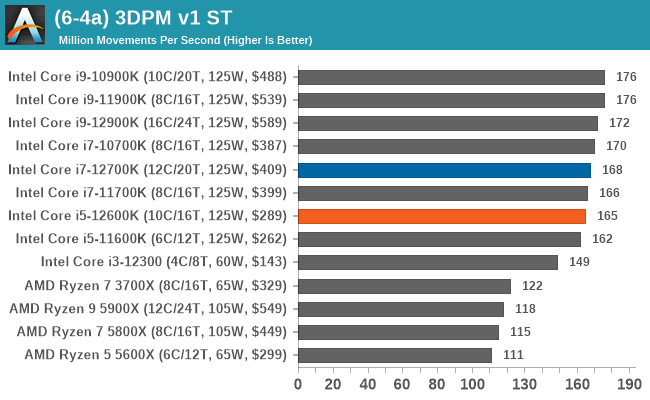
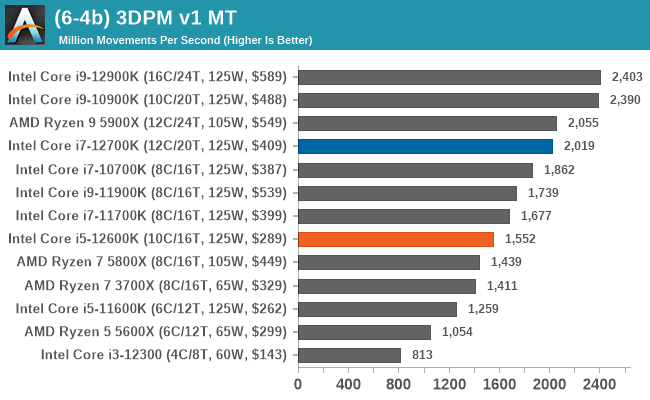
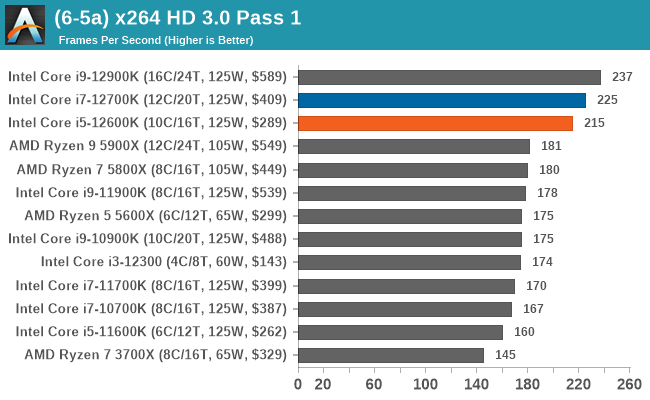

In our legacy section of the suite, both the Core i7-12700K and Core i5-12600K perform well in older benchmarks. It's worth pointing out that all of Intel's 12th Gen Core series processors do well here, with the combination of high core frequency, core count, and IPC performance all playing its part.
Web
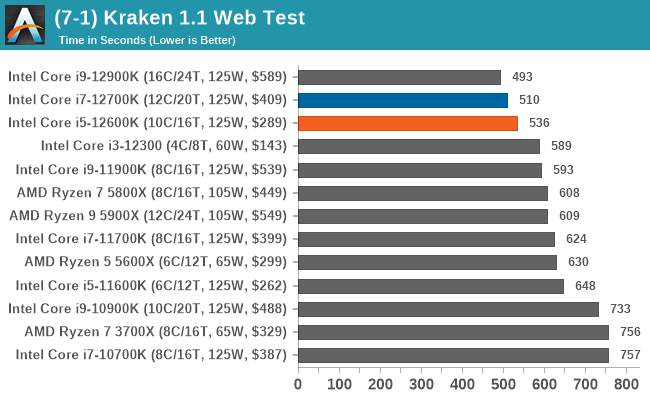
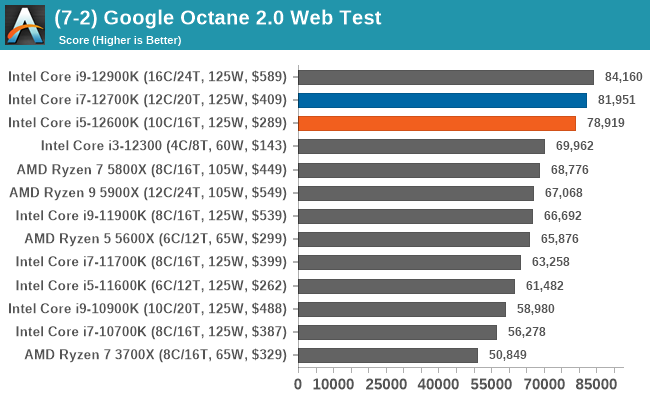
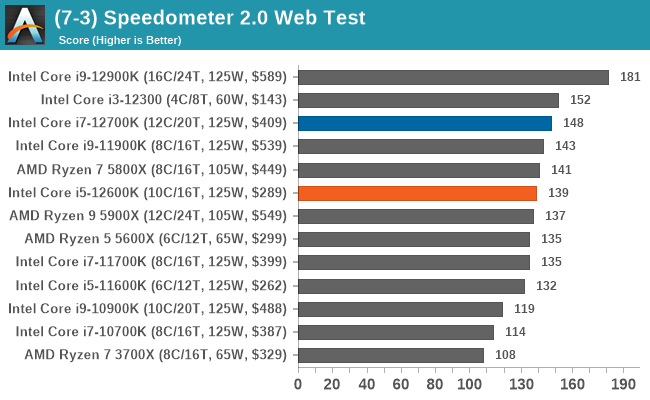
Looking at performance in our web-based tests, the three premium K SKUs in Intel's Alder Lake stack once again shows its dominance over the rest of the competition.








196 Comments
View All Comments
kwohlt - Wednesday, March 30, 2022 - link
E cores are getting double the L2 cache in Raptor Lake, so that is certainly not 0% gain.vlad42 - Friday, April 1, 2022 - link
Yes, and from Ice Lake to Tiger Lake there was a 2.5x L2 cache size increase (512KB -> 1.25 MB) and ~0% gain per clock. It all depends on whether or not the 2x L2 increase in Intel's next gen E cores is countered by something else such as increased L2 cache latency, longer pipeline depth, etc.mode_13h - Saturday, April 2, 2022 - link
> from Ice Lake to Tiger Lake there was a 2.5x L2 cache size increase (512KB -> 1.25 MB)> and ~0% gain per clock.
Your point seems to be that L2 cache doesn't matter, but that's not what Ian & Andrei concluded. From the Tiger Lake review:
"IPC improvements of Willow Cove are quite mixed. In some rare workloads which can fully take advantage of the cache increases we’re seeing 9-10% improvements, but these are more of an exception rather than the rule. In other workloads we saw some quite odd performance regressions, especially in tests with high memory pressure where the design saw ~5-12% regressions. As a geometric mean across all the SPEC workloads and normalised for frequency, Tiger Lake showed 97% of the performance per clock of Ice Lake."
So, it seemed to make a significant impact in *some* cases. Without deep analysis, one can't conclude exactly why the regressions occurred, because there are other differences between the chips than their caches.
However, another point worth remembering is that performance increases from clock speed alone tend to be sub-linear. Therefore, it takes more than merely cranking up the clocks to even maintain IPC-parity.
https://www.anandtech.com/show/16084/intel-tiger-l...
Mike Bruzzone - Tuesday, April 5, 2022 - link
I'll toss this in for consideration. Not a design consideration but a fabrication consideration.Density can be an enemy to performance as well as a friend.
Ice U quad to Tiger U quad to Tiger Octa to Sapphire Rapids 14C incremental fabrication improvement is how Intel validated SF10/x; getting back on process track.
Pursuing design process validation this way quad/octa/dodedeca Intel seriously over produced TL quad and I suspect a wide variance from spec across TL quad production volume. I also believe this to be a great undergraduate / graduate studies project to record variance across all three architectures in relation to spec. My thesis is its all over the place on Tiger quad U and may be with Tiger octa? I don't have the time or resources to do this but for those who do, you'll get a job after graduation on this project.
I think Alder Lake structurally is an improvement, but architecturally on design process I am not sure.
Fabrication yield assessment on SUPPLY
https://seekingalpha.com/instablog/5030701-mike-br... a design
This is getting dated but it examines the cost change between Comet mobile 14/12 to Ice 10 nm production cost.
https://seekingalpha.com/instablog/5030701-mike-br...
mb
drothgery - Wednesday, March 30, 2022 - link
The abysmal IPC gains were on Skylake respins. Of course they didn't gain much on IPC, they were basically the same core (which was still better than Zen 1; it took Zen 2 to beat Skylake+++ on a core per core basis)!Spunjji - Friday, April 1, 2022 - link
The abysmal ~5% IPC gains were consistent across every Intel generation after Sandy Bridge and only stopped with Ice Lake, which lost so much in clock speed that overall performance didn't improve. We finally got a proper improvement with Tiger Lake on mobile and then Alder Lake on desktop.mode_13h - Saturday, April 2, 2022 - link
> The abysmal ~5% IPC gains were consistent across every Intel generation after Sandy Bridge and only stopped with Ice Lake,Intel was busy adding things like AVX2, AVX-512, TSX, and bigger iGPUs. That's the direction they went with the additional transistors they were willing to use. That's not to say they couldn't have done more on IPC as well, but I think they made a conscious decision to invest in other aspects.
Khanan - Thursday, April 7, 2022 - link
Rocket Lake recently would like a word with you. A nice disaster that was, again a abysmal IPC gain that was offset or more than offset in most cases by the larger cache of 10900K. Intel up to 12th gen didn’t really do many good things. 12th then again only is up to par with 5950X when running on over 200W, not really as good, I would certainly buy the 5950X and not the 12900K if I needed 16 cores and a lot of threads.mode_13h - Monday, April 11, 2022 - link
> Rocket Lake recently would like a word with you.Yeah, that was an interesting experiment. It turned out better than I expected, but still not great. The problem with backporting a uArch is that each is designed around the properties of a process node - most importantly, the critical path. If such assumptions go out the window, then you might be looking at things like adding more pipeline stages, which then potentially invalidates other tradeoffs.
> abysmal IPC gain that was offset or more than offset in most
> cases by the larger cache of 10900K.
I'll have to go back and look at benchmarks, because the sense I got was that only those which had good scaling vs. number of cores were the ones that still came out ahead on Comet Lake. The ones with poorer scaling favored the IPC gains on Rocket Lake.
Here's what Ian concluded about Rocket Lake's IPC:
"Compared to the previous generation, clock-for-clock performance gains for math workloads are 16-22% or 6-18% for other workloads"
Source: https://www.anandtech.com/show/16495/intel-rocket-...
Since that review lacked SPEC2017 tests, you have to go back to the i7 "surprise!" review, for those:
"Here, the new generation from Intel is showcasing a +5.8% and +16.2% performance improvement over its direct predecessor. Given the power draw increases we’ve seen this generation, those are rather unimpressive results, and actually represent a perf/W regression."
https://www.anandtech.com/show/16535/intel-core-i7...
It's weird that you mention cache, because Rocket Lake actually boosted L1D by 50% and doubled L2! It's only L3 that's a little smaller, but we're still talking about 2 MB per core.
yankeeDDL - Tuesday, March 29, 2022 - link
I'm not sure about the flip/flop. AMD has been in the lead in most relevant benchmarks since Zen (1xxx).Zen3 vs TGL was a bloodbath. I am glad to see Intel back up: I think AMD was starting to slouch a bit with the improvements: competition is awesome.
And yes, ADL is only marginally better than Zen3 (generally speaking: more power hungry, but slightly better perf/watt, ending up in a decent advantage in peak performance, despite the massive consumption). So it's likely that Zen4 will re-establish AMD dominance.
The chiplet approach also should make Ryzen noticeably cheaper to manufacture, which means Intel would really need to bump up the performance on the next Gen.