Supermicro Ultra SYS-120U-TNR Review: Testing Dual 10nm Ice Lake Xeon in 1U
by Dr. Ian Cutress on July 22, 2021 9:00 AM EST
With the launch of Intel’s Ice Lake Xeon Scalable platform comes a new socket and a range of features that vendors like Supermicro have to design for. The server and enterprise market is so vast that every design can come in a range of configurations and settings, however one of the key elements is managing compute density with memory and accelerator support. The SYS-120U-TNR we are testing today is a dense system with lots of trimmings all within a 1U, to which Supermicro is aiming at virtualization workloads, HPC, Cloud, Software Defined Storage, and 5G. This system can be equipped with upwards of 80 cores, 12 TB of DRAM, and four PCIe 4.0 accelerators, defining a high-end solution from Supermicro.
Servers: General Purpose or Hyper Focused?
Due to the way the server and enterprise market is both expansive and optimized, vendors like Supermicro have to decide how to partition their server and enterprise offerings. Smaller vendors might choose to target one particular customer, or go for a general purpose design, whereas the larger vendors can have a wide portfolio of systems for different verticals. Supermicro falls into this latter category, designing targeted systems with large customers, but also enabling ‘standard’ systems that can do a bit of everything but still offer good total cost of ownership (TCO) over the lifetime of the system.

Server size compared to a standard 2.5-inch SATA SSD
When considering a ‘standard’ enterprise system, in the past we have typically observed a dual socket design in a 2U (3.5-inch, 8.9cm height) chassis, which allows for a sufficient cooling design along with a number of add-in accelerators such as GPUs or enhanced networking, or space on the front panel for storage or additional cooling. The system we’re testing today, the SYS-120U-TNR, certainly fields this ‘standard’ definition, although Supermicro does the additional step of optimizing for density by cramming everything into a 1U chassis.

With only 1.75-inches (4.4cm) vertical clearance on offer, cooling becomes a priority, which means substantial enough heatsinks and fast moving airflow backed by 8 powerful 56mm fans, which are running at up to 30k RPM with PWM control. The SYS-120U-TNR we’re testing has support for 2 Ice Lake Xeon processors at up to 40 cores and 270 W each, as well as additional add-in accelerators (one dual slot full height + two single slot full height), and comes equipped with dual 1200W Titanium or dual 800W Titanium power supplies, indicating that it is suited up should a customer want to fill it with plenty of hardware. You can see in the image above and on the right of the image below, Supermicro uses plastic baffles to ensure that airflow through the heatsink and memory is as laminar as possible.

LGA-4189 Socket with 1U Heatsink and 16 DDR4 slots
Even with the 1U form factor, Supermicro has enabled full memory support for Ice Lake Xeon, allowing both processors sixteen DDR4-3200 memory slots, capable of supporting a total of 12 TB of memory with Intel’s Optane DCPMM 200-series.

At the front are 12 2.5-inch SATA/NVMe PCIe 4.0 x4 hot swappable drive bays, with six apiece coming from each processor. If we start looking into where all the PCIe lanes from each processor go, it gets a bit confusing very quickly:
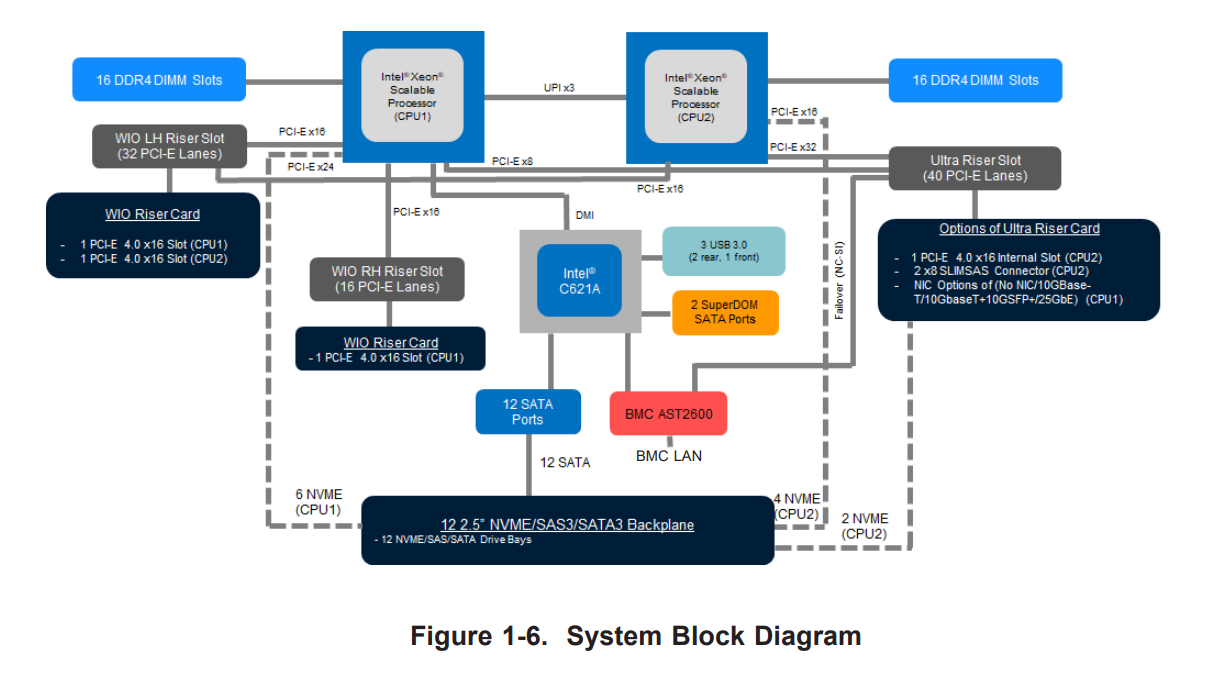
By default the system comes without network connectivity, only with a BMC connection for admin control. Network options requires an Ultra add-in riser card for dual 10GBase-T (X710-AT2), or dual 10GBase-T plus dual 10GbE SFP+ (X710-TM4). With the PCIe connectors, any other networking option might be configured, but Supermicro also lists the complete no-NIC option for air-gapped systems. The system also has three USB 3.0 ports (2 rear, 1 front), a rear VGA output, a rear COM port, and two SuperDOM ports internally.
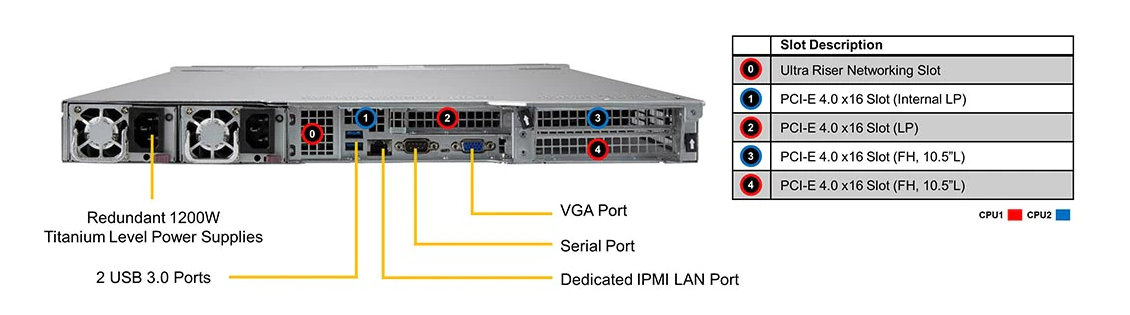
Admin control comes from the Aspeed AST2600 which supports IPMI v2.0, Redfish API, Intel Node Manager, Supermicro’s Update Manager, and Supermicro’s SuperDoctor 5 monitoring interface.

The configuration Supermicro sent to us for review contains the following:
- Supermicro SYS-120U-TNR
- Dual Intel Xeon Gold 6330 CPUs (2x28-core, 2.5-3.1 GHz, 2x205W, 2x$1894)
- 512 GB of DDR4-3200 ECC RDIMMs (16 x 32 GB)
- Dual Kioxia CD6-R 1.92TB PCIe 4.0x4 NVMe U.2
- Dual 10GBase-T via X710-AT2
Full support for the system includes:
| Supermicro SYS-120U-TNR | ||
| AnandTech | Info | |
| Motherboard | Super X12DPU-6 | |
| CPUs | Dual Socket P+ (LGA-4189) Support 3rd Gen Ice Lake Xeon Up to 270W TDP, 40C/80T 7+1 Phase Design Per Socket |
|
| DRAM | 32 DDR4-3200 ECC Slots Support RDIMM, LRDIMM |
|
| Up to 8 TB 32 x 256 GB LRDIMM |
Up to 12 TB 16 x 512 GB Optane 16 x 256 GB LRDIMM |
|
| Storage | 12 x SATA Front Panel Optional PCIe 4.0 x4 NVMe Cabling |
|
| PCIe | PCIe 4.0 x16 Low Profile PCIe 4.0 x16 Low Profile (Internal) 2 x PCIe 4.0 x16 Full Height (10.5-inch length) Ultra Riser for Networking |
|
| Networking | None by default Optional X710-AT2 dual 10GBase-T Optional X710-TM4 dual 10GBase-T + SFP+ |
|
| IO | RJ45 BMC via ASpeed AST2600 3 USB 3.0 Ports (2 rear, 1 front) VGA BMC 1 x COM 2 x SuperDOM |
|
| Fans | 8 x 40mm double thick 30k RPM with control 2 Shrouds, 1 per CPU socket+DRAM |
|
| Power | 1200W Titanium Redundant, Max 100A | |
| Chassis | CSE-119UH3TS-R1K22P-T | |
| Management Software |
IPMI 2.0 via ASpeed AST2600 Supermicro OOB License included Redfish API Intel Node Manager KVM with Dedicated LAN SUM NMI Watch Dog SuperDoctor 5 ACPI Power Management |
|
| Optional | 2x M.2 RAID Carrier Broadcom Cache Vaults Intel VROC Raid Key RAID Cards + Cabling Hardware-based TPM Ultra Riser Cards |
|
| Note | Sold as assembled system to resellers (2 CPU, 4xDDR, 1xStorage, 1xNIC) |
|
We reached out to Supermicro for some insight into how this system might be configured for the different verticals.
| Supermicro Ultra-E SYS-120U-TNR Configuration Variants |
||||
| AnandTech | CPU | Memory | Storage | Add-In |
| Virtualization | ++ | ++ | ||
| HPC | ++ | + | ||
| Cloud Computing | handles all mainstream configs | |||
| High-End Enterprise | ++ | ++ | ++ | ++ |
| Software Defined Storage | + or 2U | |||
| Application aaS | + | + | + | + |
| 5G/Telco | Ultra-E Short-Depth Version | |||
Read on for our benchmark results.








53 Comments
View All Comments
mode_13h - Friday, July 23, 2021 - link
> It's a real-world workloadExcept it's not. It started out that way, but then he gave it to Intel to optimize the AVX-512 path. So, the AVX-512 is optimized by "a world expert, according to Jim Keller" (to paraphrase Ian). And yet, the AVX-512 results are put up against the AVX2 results, on AMD CPUs, as if they're both optimized to the same degree and that just happens to be the *actual* difference in performance.
As an excuse for this, Ian points out that he gave AMD the same opportunity, but they haven't taken him up on it. Well, that still doesn't make it a fair representation of AVX2 vs. AVX-512 performance.
> I'm not sure the point should be to microoptimize it to the ends of the world,
> or it wouldn't be a realistic workload any longer.
A lot of workloads are heavily-optimized. This includes kernels in HPC programs, many games, and the most popular video compression engines. Probably a lot of stuff in SPEC Bench has been optimized a high degree. And let's not even start on AI frameworks.
All I want to do is see if people can close the gap between AVX2 and AVX-512 somewhat, or at least explain why it's as big as it is. Maybe there's some magic AVX-512 instructions that have no equivalent in AVX2, which turn out to be huge wins. It would at least be nice to know.
Plus, there's my point about optimizing it for ARM NEON and SVE, so it could be used in a somewhat apples-to-apples comparison with ARM processors.
GeoffreyA - Friday, July 23, 2021 - link
I agree it's unfair. On the "non-AVX" test, the Ryzens go to the top. On one hand, the test shows how much faster an AVX512 processor can be. On the other hand, it's unfair that some are running the AVX2 path and some the AVX512, and the results are put together. (Reminiscent of the Athlon XP's SSE not being used in some benchmarks.)Others, I don't know, but in a thing like HEVC encoding, the gains aren't all that much for these instructions. It leads me to feel the 3DPM test is gaining disproportionately from AVX512, in a narrow sort of way, and that's being magnified. The result shows, "Look at how fast these AVX512 CPUs are, leaving their AMD counterparts in the dust."
https://networkbuilders.intel.com/docs/acceleratin...
https://software.intel.com/content/www/us/en/devel...
mode_13h - Saturday, July 24, 2021 - link
> it's unfair that some are running the AVX2 path and some the AVX512,> and the results are put together.
That's a reasonable position, but I'm not even going that far. I'm okay with putting up AVX2 against AVX-512, but I think they need to be optimized somewhat comparably. That way, the difference you see only shows the true difference in hardware capability, and not also the (unknown) difference in the level of code optimization.
> "Look at how fast these AVX512 CPUs are, leaving their AMD counterparts in the dust."
It does have a few specialized instructions that have no AVX2 counterpart. And if you're doing something they were specifically designed to accelerate, then you can get a legit order of magnitude speedup. And it's not impossible 3DPM hit one of those cases. But, in order to know, Ian really needs to disclose the code.
GeoffreyA - Saturday, July 24, 2021 - link
"it's not impossible 3DPM hit one of those cases"Possible, even likely. And if so, it's a bit of an unbalanced picture. It will be interesting to see what happens when AMD adds support.
mode_13h - Sunday, July 25, 2021 - link
> Possible, even likely.We don't know, so don't presume. There are some obvious things you can get wrong that sabotage performance. Cache thrashing, pointer aliasing, and false sharing, just to name a few. Probably a lot of the speedup, in the AVX-512 case, was fixing just such things.
Spunjji - Monday, July 26, 2021 - link
@GeoffreyA - I would argue that it wouldn't necessarily be unbalanced if the benchmark benefits particularly heavily from AVX-512, simply because there are going to be workloads like that out there, and the people who have them are probably going to be aware of that to some extent.With comparable optimisation between the AVX2 and AVX-512 code paths, it could still be a helpful example of a best-case for the feature, for those few people for whom it's going to work out like that.
For everyone else, we could definitely do with more generalised real-world examples (like x264) where the AVX-512 part of the workload isn't necessarily dominant.
GeoffreyA - Wednesday, July 28, 2021 - link
That's a good way of looking at it, Spunjji. You're right. Hopefully we can those balanced, real-world examples in addition.GeoffreyA - Saturday, July 24, 2021 - link
And for a best AVX2 vs. best AVX512, I think we probably need some bigger test, something like encoding I would think. I could be wrong, but remember reading that x264 had AVX512 support. I doubt whether it's been optimised to the fullest, though. And most of the critical work on x264 was done a long time ago.GeoffreyA - Sunday, July 25, 2021 - link
My mistake. x265.mode_13h - Sunday, July 25, 2021 - link
Yeah, some of the rendering and encoding benchmarks use it.