The Microsoft Surface Laptop 3 Showdown: AMD's Ryzen Picasso vs. Intel's Ice Lake
by Brett Howse & Andrei Frumusanu on December 13, 2019 8:30 AM ESTSection by Andrei Frumusanu
SPEC2017 - ST & MT Performance
Starting off with SPEC, we’re trying to analyze the AMD and Intel systems in direct comparison to each other in a wide variety of workloads. In general, we shouldn’t be expecting too big surprises in the results as earlier this summer we had the opportunity to cover Intel’s Ice Lake CPUs, and the Surface Laptop 3 implementation of the Core i7-1065G7 should pretty much fall in line with those scores.
On AMD’s side, we hadn’t tested the company’s mobile processors in SPEC so this should represent a good opportunity to showcase the two companies’ products side-by-side. As a reminder, the Ryzen 7 3870U tested today is based on AMD’s Picasso chip, a 12nm implementation of the Zen+ microarchitecture, which isn’t quite as up-to-date as the 7nm Zen2 silicon that the company offers in its desktop Ryzen 3000 chips. In a sense, while both products tested today represent the companies’ best mobile products, for Intel it also represents the company’s best technologies, and thus the ICL part has a generational advantage over AMD's current product-line.
We’re limiting our testing this time around to SPEC2017 as it represents the more modern workload characterisations, and we’ve already covered the microarchitectural giveaways presented by SPEC2006 in past articles. We’re testing under WSL1 in Windows due to simplicity of compilation and compatibility, and are compiling the suite under LLVM compilers. The choice of LLVM is related to being able to have similar code generation across architectures and platforms. Our compiler versions and settings are as follows:
clang version 8.0.0-svn350067-1~exp1+0~20181226174230.701~1.gbp6019f2 (trunk) clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git 24bd54da5c41af04838bbe7b68f830840d47fc03) -Ofast -fomit-frame-pointer -march=x86-64 -mtune=core-avx2 -mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions.
Single-Threaded Performance: Intel Dominance
Starting off with single-threaded tests, we’re having a closer look at the integer SPEC20017 suite results.
We’re also adding in AMD and Intel’s top-performing desktop chips into the mix to better convey a context as to where these mobile parts fall in terms of absolute performance, which I think is a major consideration point for the Surface Laptop 3, particularly the Ice Lake models.
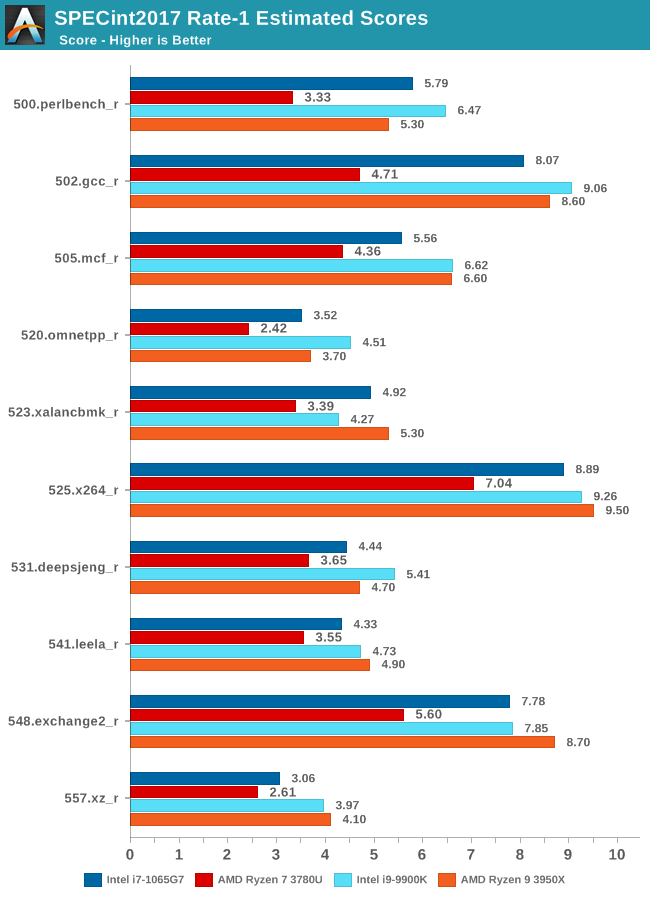
The first thing that comes to mind when looking at these results is that there’s a huge discrepancy between what the Intel and AMD models of the Surface Laptop 3. It’s very evident that Intel’s new Ice Lake CPUs and the Sunny Cove microarchitecture have quite a large lead over the Zen+ based Picasso SoC.
The Intel model's performance is near identical to what we’ve measured back in August on Intel’s development platform: we again see the chip being able to keep up with even Intel’s best performing desktop solutions which are running at far higher frequencies and larger power draw.
The Ryzen 7 3780U isn’t quite able to showcase a similar positioning, as it’s notably further behind the Ryzen 9 3950X with the newer Zen2 microarchitecture and faster memory configuration.
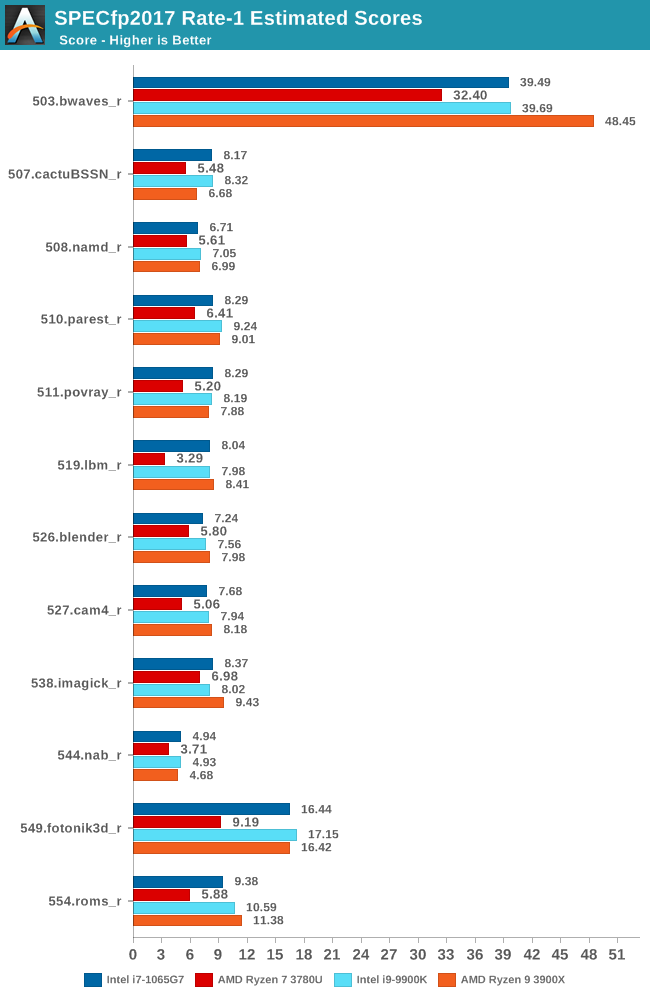
The situation in the floating-point suite is very similar, with the Core i7-1065G7 taking a quite considerable lead over the Ryzen 7 3780U. The 519.lbm results here are interesting due to the fact that AMD’s platform is behind by a factor greater than 2x – the test is memory bandwidth and subsystem limited so it’s possibly a bigger bottleneck on the slower DDR4-2400 memory that the system has to make due with. Intel’s LPDDR4X-3733 is able to well keep up with the desktop platforms in such situations.
But even in less memory intensive workloads such as 511.povray, AMD’s IPC disadvantage is too great and even with a theoretical higher peak frequency of 500MHz, the Zen+ based design is too far behind Intel’s new microarchitecture.
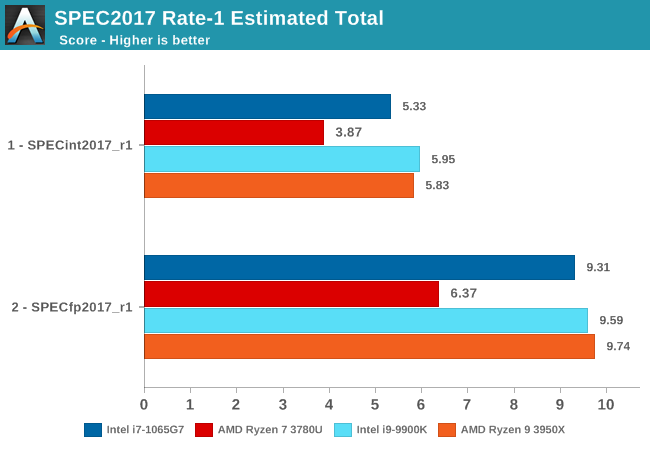
The overall SPEC2017 ST scores are pretty one-sided, with the Intel variant of the Surface Laptop 3 being ahead by 37% in the integer suite, and 46% in the floating-point suite. We hadn’t really expected the AMD system to be able to keep up with the Intel CPU, but these results really just expose the technological differences between the two designs. AMD’s Zen2 and LPDDR4X APUs can’t come early enough, as this is a gap that the company needs to close as soon as possible if it wants to compete in high-end laptop designs.
Multi-Threaded Performance: Continued Intel Advantage
While it’s clear that Intel has a large single-threaded performance advantage, we wanted to also see the competitive situation in a multi-threaded/multi-process comparison between the two chips. In the Rate-N test configuration of SPEC, we’re launching 8 instances on both platforms to fully saturate the system and have two processes per physical CPU.
In the MT tests, the AMD system ran at frequencies between 2.9-3.35GHz, whilst the Intel platform ran between 2.6-3.5GHz, depending on workload. TDP, or better said, peak power consumption, plays a bigger role in these tests as the 4-6 hours runtime of the test means we’re really stressing the cooling solutions of the laptops. Intel’s chip here is allowed to draw up to 44W for short durations before it falls down to a sustained 25W. We weren’t able to accurately measure the power draw for the AMD platform but we do note that it looks like under prolonged stress the CPU was around 10°C colder than the Intel variant, with ~70°C at 2.9GHz for the Ryzen system versus 80°C at 2.6GHz for the Intel system, which could point out to a lower sustained power draw for the AMD system.
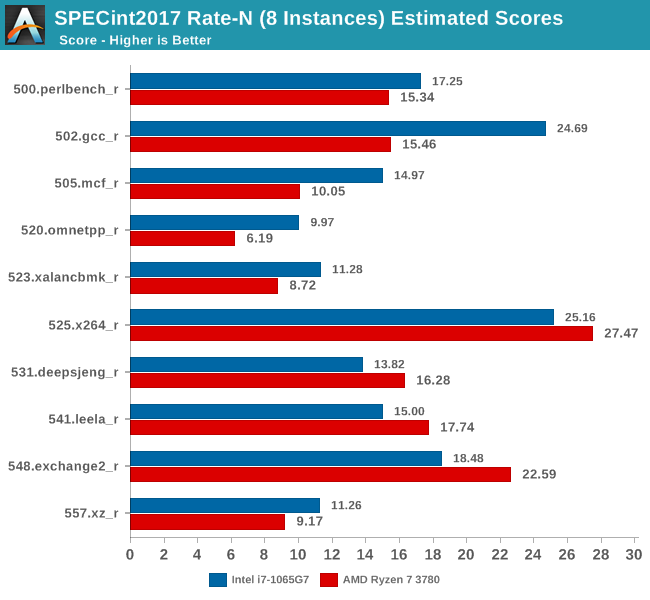
In the integer suite, we mostly seeing the Intel system being ahead, but this time around AMD also manages to win a few tests. The tests where AMD fared best were workloads which have a higher execution characterization, compared to more strictly memory-bound tests such as mcf or omnetpp, where Intel has a clear lead in. Intel’s lead in 502.gcc is pretty massive as well as surprising – I hadn’t expected such a gap, but then again, it’s quite in line with what we saw in the ST results.

In the floating-point suite AMD loses the few advantages that it had, and falls further behind the Intel platform. The FP suite is a lot more memory bound, and Picasso’s memory subsystem here just can’t keep up. The 519.lbm and 554.roms results are particularly shocking as they’re essentially almost no faster than the single-threaded results – the system here is utterly bottlenecked and can’t even scale up in performance over multiple cores.
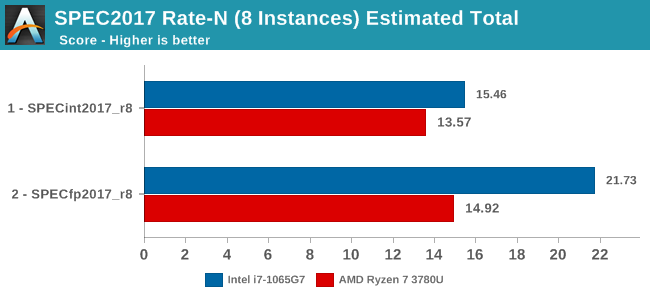
The overall results for the Rate-8 tests across all physical and logical cores of both the Ice Lake and Picasso systems see a similar performance discrepancy as showcased in the ST results: The Intel Core i7-1065G7 is ahead by 13.9% in the integer suite and a massive 45.6% in the FP suite. The one bottleneck that’s seemingly holding back the AMD system the most is its memory subsystem, and workloads which particularly stress this part of the CPU microarchitectures are the tests in which the Ryzen system fared by far the worst.
All in all, Intel’s process node, microarchitectural IPC, and memory technology lead in the Ice Lake solution is seemingly just too much for the Picasso chip to be able to compete with. Let’s move on to our standard test suite benchmarks and see if the we can correlate similar results in other workloads…








174 Comments
View All Comments
TheinsanegamerN - Friday, December 13, 2019 - link
It isnt just speed, the intel chip uses LPDDR4X. That's an entirely different beat from LPDDR4, let alone normal DDR4.AMD would need to redesign their memory controller, and they have just...not done it. The writing was on the wall, and I have no idea why AMD didnt put LPDDR4X compatibility in their chips, hell I dont know why intel waited so long. The sheer voltage difference makes a huge impact in the mobile space.
You are correct, pushing those speeds at normal DDR4 voltage levels would have tanked battery life.
ikjadoon - Friday, December 13, 2019 - link
Sigh, it is just speed. DDR4-2400 to DDR4-3200 is simply speed: there is no "entirely new controller" needed. The Zen+ desktop counterpart is rated between DDR4-2666 to 2933.LPDDR4X is almost identical to LPDDR4: "LPDDR4X is identical to LPDDR4 except additional power is saved by reducing the I/O voltage (Vddq) to 0.6 V from 1.1 V." Whoever confused you that LPDDR4X is "an entirely different beat" from LPDDR4 is talking out of their ass and I caution you to believe anything else they ever say.
And, no: DDR4-3200 vs DDR4-2400 would've tanked battery life, but simply made it somewhat worse. DDR4-3200 can still run on the stock 1.2V that SO-DIMM DDR4 relies on, but it's pricier and you'd still pay the MHz power penalty.
I don't think RAM speed/voltage has ever "tanked" a laptop's battery life: shaking my head here...
mczak - Friday, December 13, 2019 - link
I'm quite sure you're wrong here. The problem isn't the memory itself (as long as you get default 1.2V modules, which exist up to ddr4-3200 itself), but the cpu. Zen(+) cpus require higher SoC voltage for higher memory speeds (memory frequency is tied to the on-die interconnect frequency). And as far as I know, this makes quite a sizeable difference - not enough to really matter on the desktop, but enough to matter on mobile. (Although I thought Zen+ could use default SoC voltage up to ddr4-2666, but I could be wrong on that.)Byte - Friday, December 13, 2019 - link
Ryzen had huge problems with memory speed and even compatibility at launch. No doubt they had to play it safe on laptops. They should have it mostly sorted out with Zen 2 laptop, it is why the notebooks are a gen behind where as intel notebook are usually a gen ahead.ikjadoon - Saturday, December 14, 2019 - link
We both agree it would be bad for battery life and a clear AMD failure. But, the details...more errors:1. Zen+ is rated up to DDR4-2933. 3200 is a short jump. Even then, AMD couldn't even rate this custom SKU to 2666 (the bare minimum of Zen+). AMD put zero work into this custom SKU (whose only saving grace is graphics and even that was neutered). It's obviously a low-volume part (relative to what AMD sells otherwise) or such a high-profile design win.
2. If AMD can't rate (= bin) *any* of its mobile SoC batches to support even 2666MHz at normal voltages, I'd be shocked.
For any random Zen+ silicon, sure, it'd need more voltage. The whole impetus for my comments are that AMD created an entire SKU for Microsoft and seemed to take it out of oven half-baked.
Or, perhaps they had binned the GPU side too much that very few of those CU 11 units could've survived a second binning on the memory controller.
azazel1024 - Monday, December 16, 2019 - link
So all that being said, yes it had a huge impact. GPU based workloads are heavily memory speed dependent. Going from 2400 to 3200MHz likely would have seen a 10-25% increase in the various GPU benchmarks (on the lower end for those that are a bit more CPU biased). That changes AMD from being slightly better overall in GPU performance to a commanding lead.On the CPU side of things, many of the Intel wins were on workloads with a lot of memory performance needed. Going from 2400 to 3200 would probably have only resulted in the AMD chip moving up 3-5% in many workloads (20-40% in the more memory subsystem dependent SPEC INT tests), but that would have still evened the playing field a lot more.
Going to 3766 like the Intel chip would have just been even more of the same.
Zen 2 and much higher memory bandwidth can't come soon enough for AMD.
Zoolook - Saturday, December 21, 2019 - link
It's not about binning, they couldn't support that memory and keep within their desired TDP because they would have to run infinity fabric at a higher speed.They could have used faster memory and lower CPU and/or GPU speed but this is the compromise they settled on.
Dragonstongue - Friday, December 13, 2019 - link
AMD make/design for a client what that client wants, in this case, MSFT as "well known" for making sure to get (hopefully pay much for) what they want, for only reasons that they can understand.this case, AMD really cannot say "we are not doing that" as this would mean loss of likely into the millions (or more) vs just saying "not a problem, what would you like?"
MSFT is very well known for catering to INTC and NVDA whims (they have, still do, even if it cost everyone many things)
still they AMD and MSFT should have "made sure" to not hold back it's potential performance by using "min spec" memory speed, instead choosing the highest speed they know (through testing) it will support.
I imagine AMD (or others) could have chosen to use LP memory selection as I call BS on others saying AMD would have no choice but to rearchitecture their design to use the LP over standard power memory, seeing as the LP is likely very little changes need to be done (if any compared to ground up for an entirely different memory type)
they should have "upped" to the next speed levels however instead of 2400 baseline, 2666, 2933, 3000, 3200 as power draw difference is "negligible" with proper tuning (which MSFT likely would have made sure to do...but then again is MSFT whom pull stupid as heck all the time, so long it keeps their "buddies happy" who care about the consumers themselves)
mikeztm - Friday, December 13, 2019 - link
LPDDR4/LPDDR4X is not related to DDR4.It's a upgraded LPDDR3 which is also not related to DDR3.
LPDDR family is just like GDDR family and are total different type of DRAM standard.
They almost draw 0 watt when not in use. And in active ram access they do not draw less power significantly compare to DDR4.
LPDDR4 was first shipped with iPhone 6s in 2015 and it takes Intel 4 years to finally catch up.
BTW this article has a intentional typo: LPDDR4 3733 on Intel is actually quad channel because each channel is half width 32bit instead of DDR4 64bit.
Dragonstongue - Friday, December 13, 2019 - link
AMD make/design for a client what that client wants, in this case, MSFT as "well known" for making sure to get (hopefully pay much for) what they want, for only reasons that they can understand.this case, AMD really cannot say "we are not doing that" as this would mean loss of likely into the millions (or more) vs just saying "not a problem, what would you like?"
MSFT is very well known for catering to INTC and NVDA whims (they have, still do, even if it cost everyone many things)
still they AMD and MSFT should have "made sure" to not hold back it's potential performance by using "min spec" memory speed, instead choosing the highest speed they know (through testing) it will support.
I imagine AMD (or others) could have chosen to use LP memory selection as I call BS on others saying AMD would have no choice but to rearchitecture their design to use the LP over standard power memory, seeing as the LP is likely very little changes need to be done (if any compared to ground up for an entirely different memory type)
they should have "upped" to the next speed levels however instead of 2400 baseline, 2666, 2933, 3000, 3200 as power draw difference is "negligible" with proper tuning )
IMO