Imagination Announces A-Series GPU Architecture: "Most Important Launch in 15 Years"
by Andrei Frumusanu on December 2, 2019 8:00 PM ESTHyperLane Technology
Another new addition to the A-Series GPU is Imagination's “HyperLane” technology, which promises to vastly expand the flexibility of the architecture in terms of multi-tasking as well as security. Imagination GPUs have had virtualization abilities for some time now, and this had given them an advantage in focus areas such as automotive designs.
The new HyperLane technology is said to be an extension to virtualization, going beyond it in terms of separation of tasks executed by a single GPU.
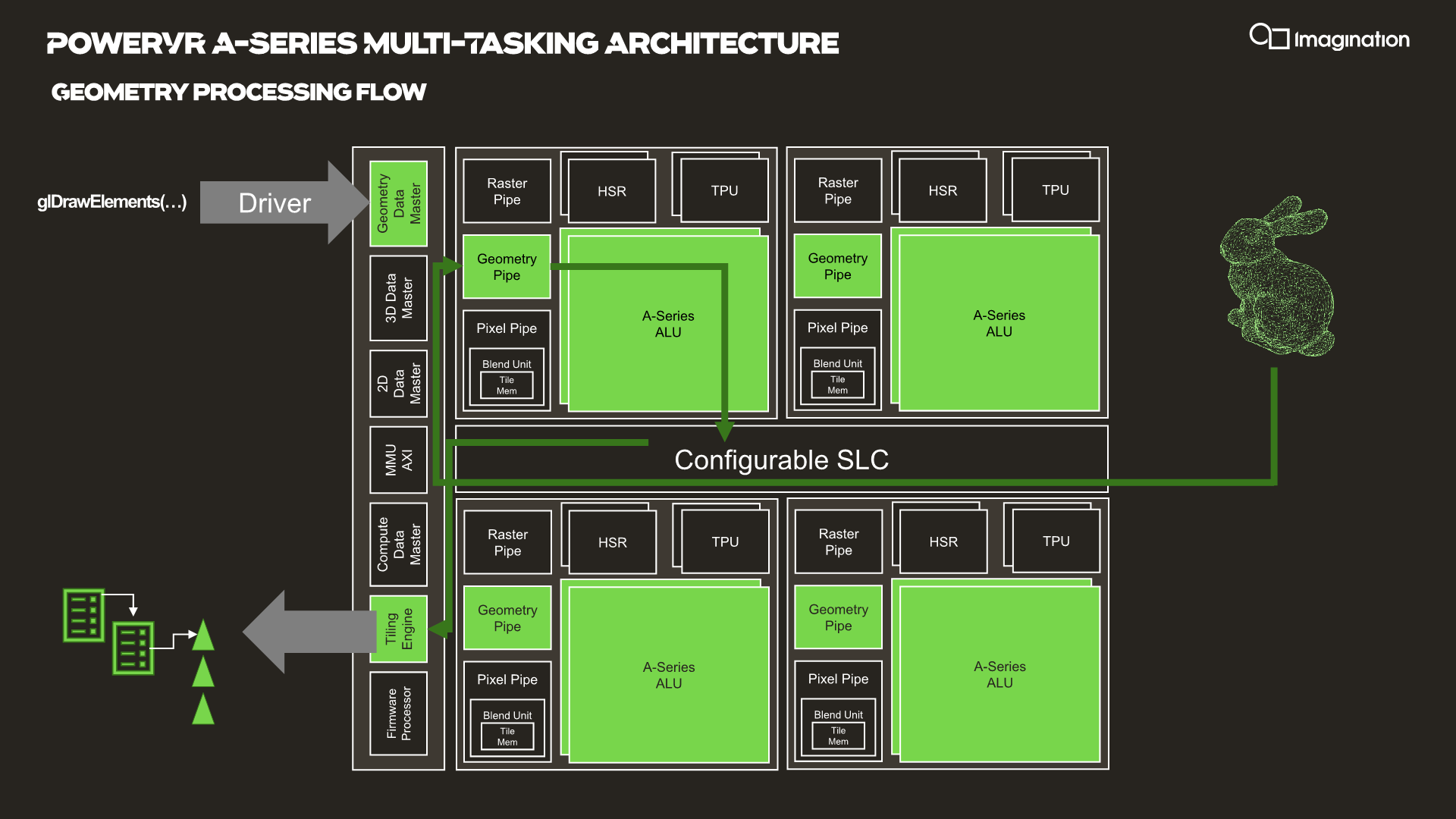
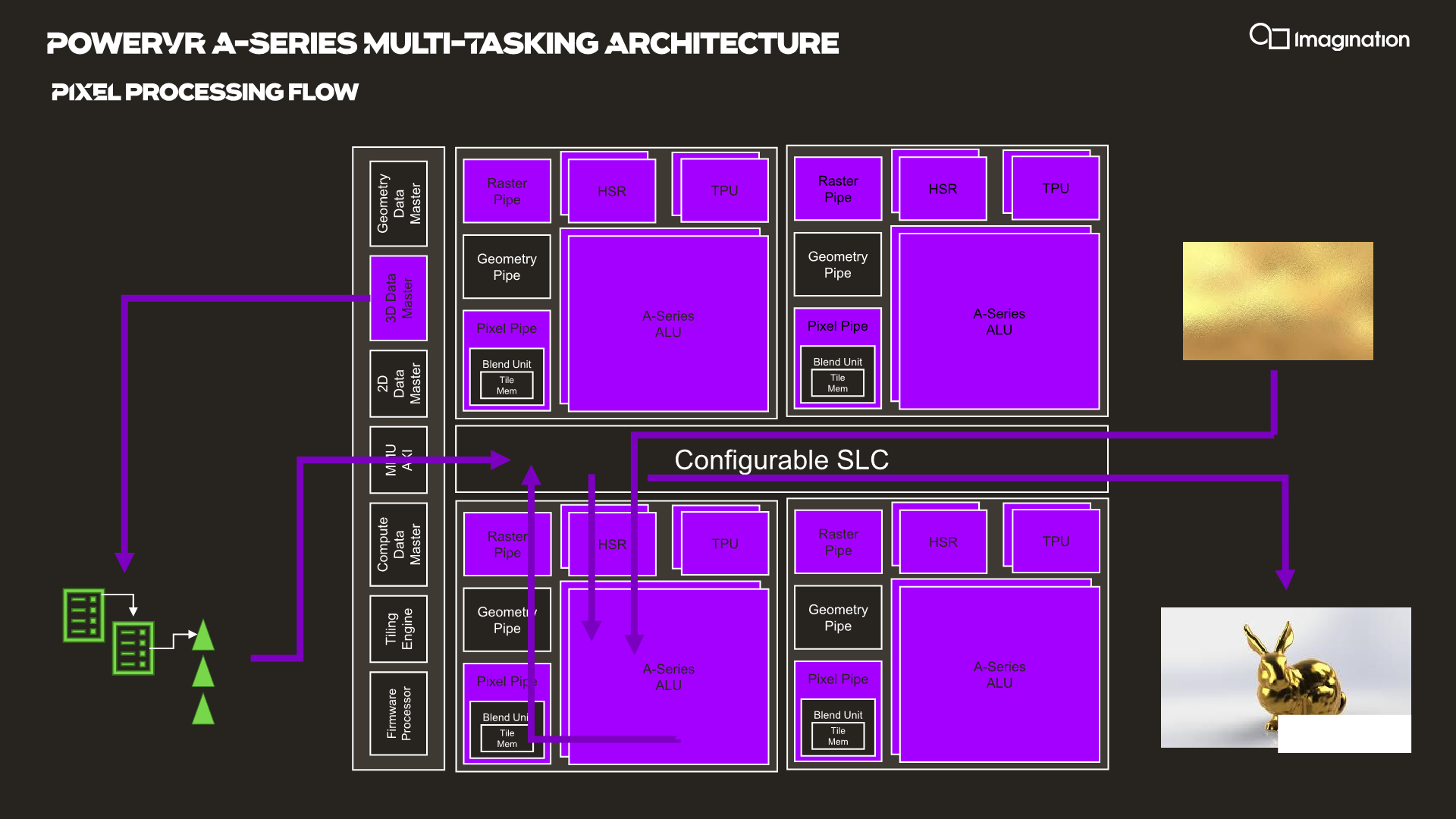
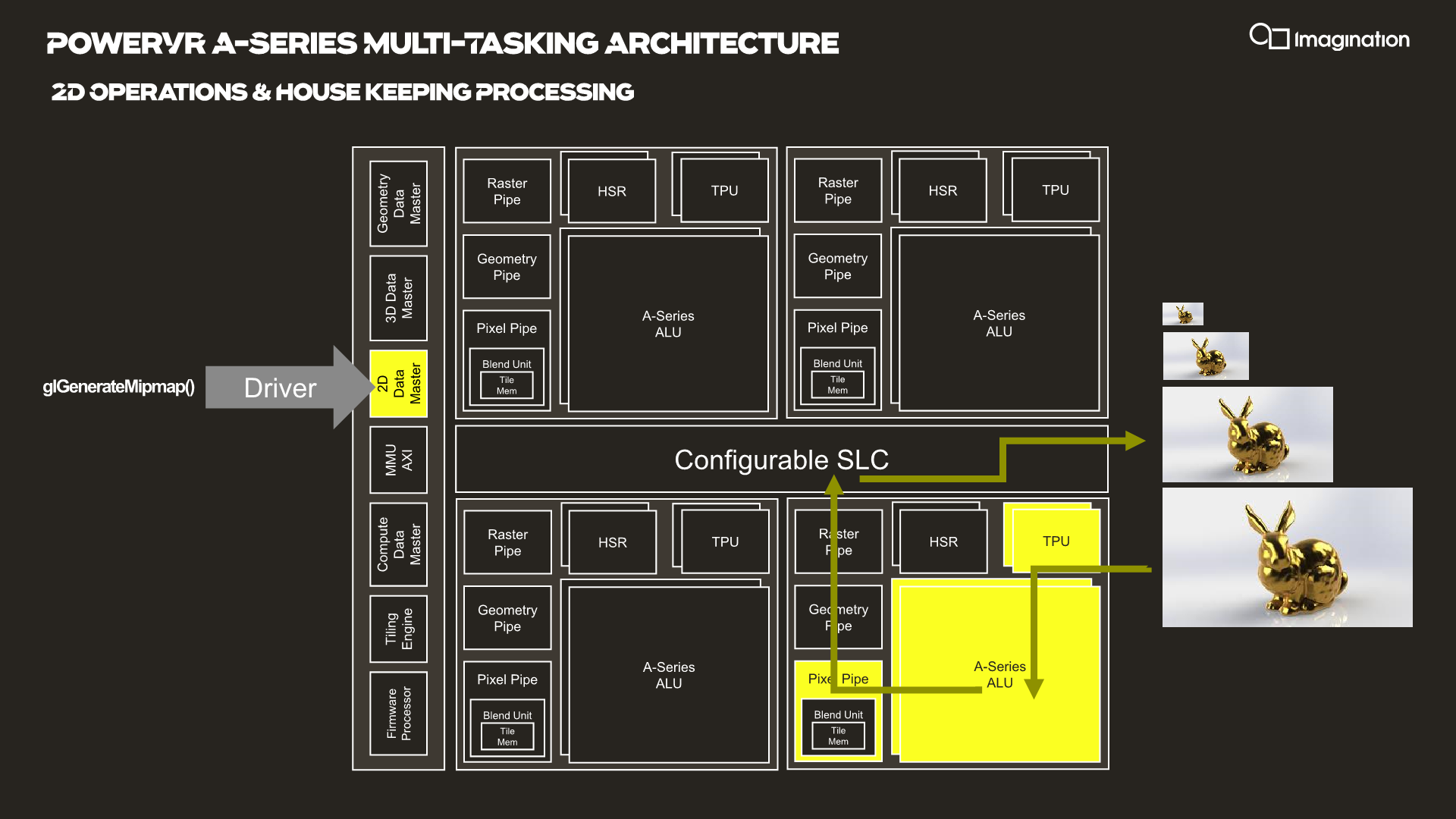
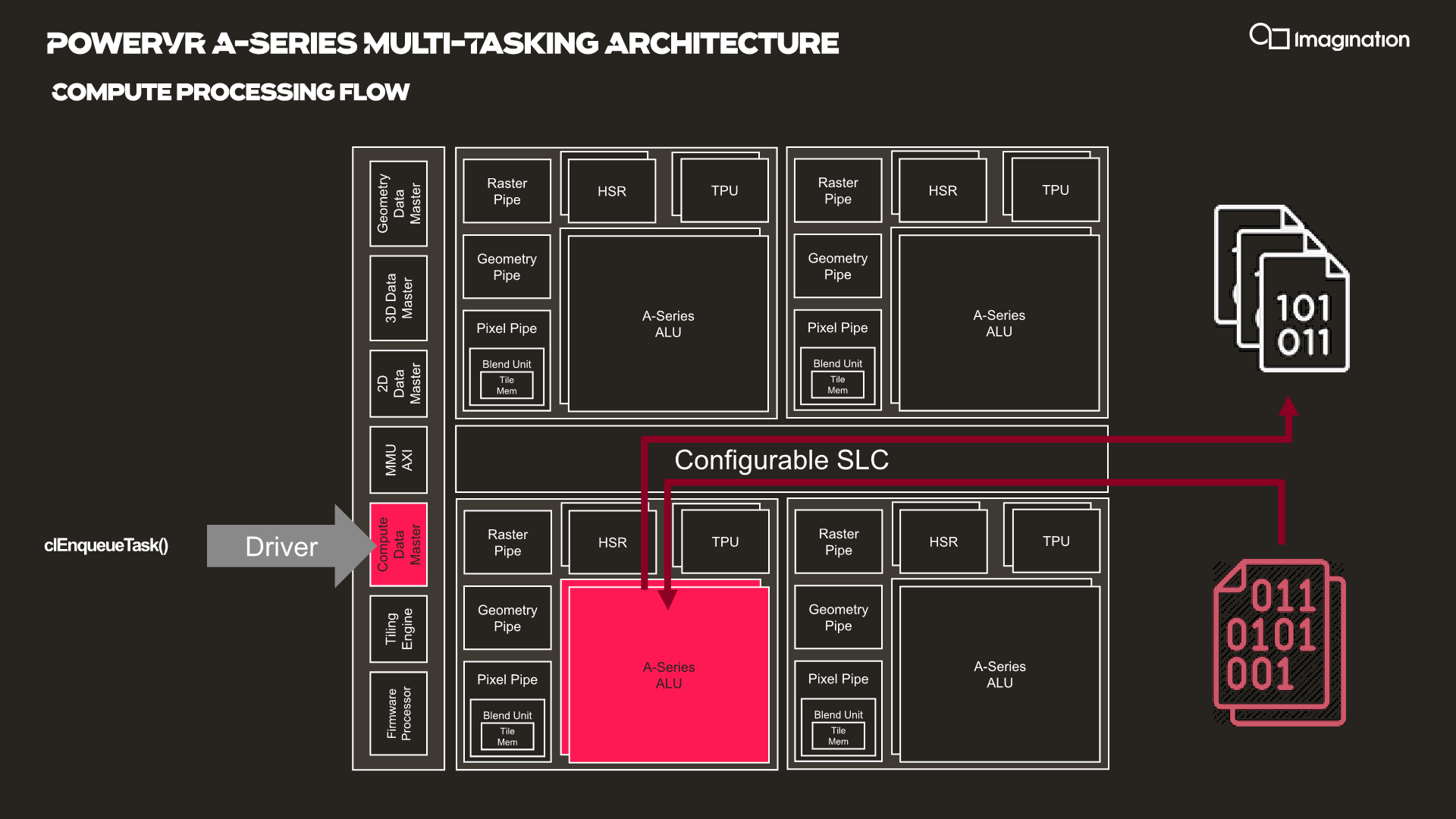
In your usual rendering flows, there are different kinds of “master” controllers each handling the dispatching of workloads to the GPU; geometry is handled by the geometry data master, pixel processing and shading by the 3D data master, 2D operations are handled by the 2D data, master, and compute workloads are processed by the, you guessed it, the compute data master.
In each of these processing flows various blocks of the GPU are active for a given task, while other blocks remain idle.
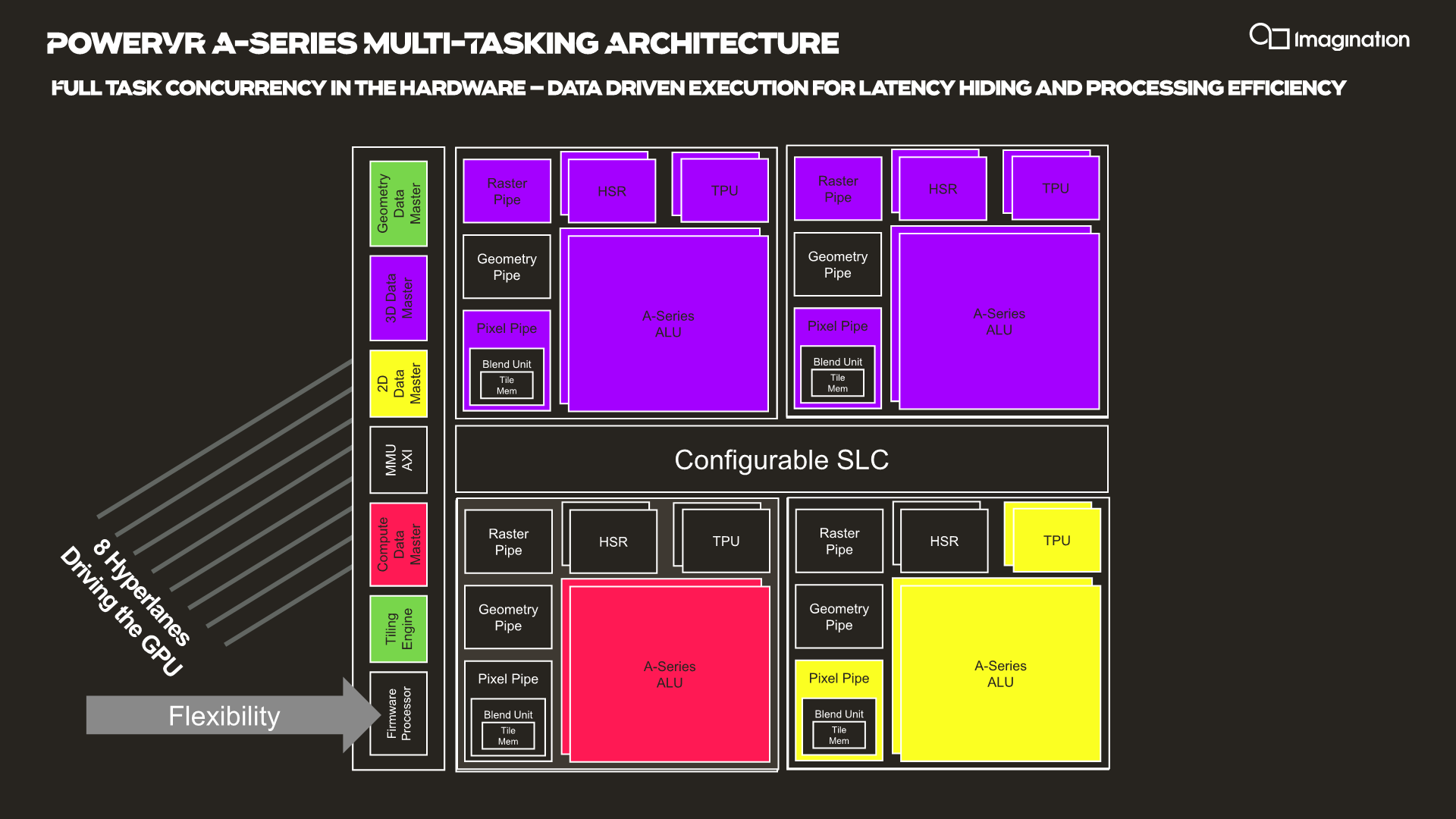
HyperLane technology is said to be able to enable full task concurrency of the GPU hardware, with multiple data masters being able to be active simultaneously, executing work dynamically across the GPU’s hardware resources. In essence, the whole GPU becomes multi-tasking capable, receiving different task submissions from up to 8 sources (hence 8 HyperLanes).
The new feature sounded to me like a hardware based scheduler for task submissions, although when I brought up this description the Imagination spokespeople were rather dismissive of the simplification, saying that HyperLanes go far deeper into the hardware architecture, with for example each HyperLane having being able to be configured with its own virtual memory space (or also sharing arbitrary memory spaces across hyperlanes).
Splitting GPU resources can happens on a block-level concurrently with other tasks, or also be shared in the time-domain with time-slices between HyperLanes. Priority can be given to HyperLanes, such as prioritizing graphics over a possible background AI task using the remaining free resources.
The security advantages of such a technology also seem advanced, with the company use-cases such as isolation for protected content and rights management.
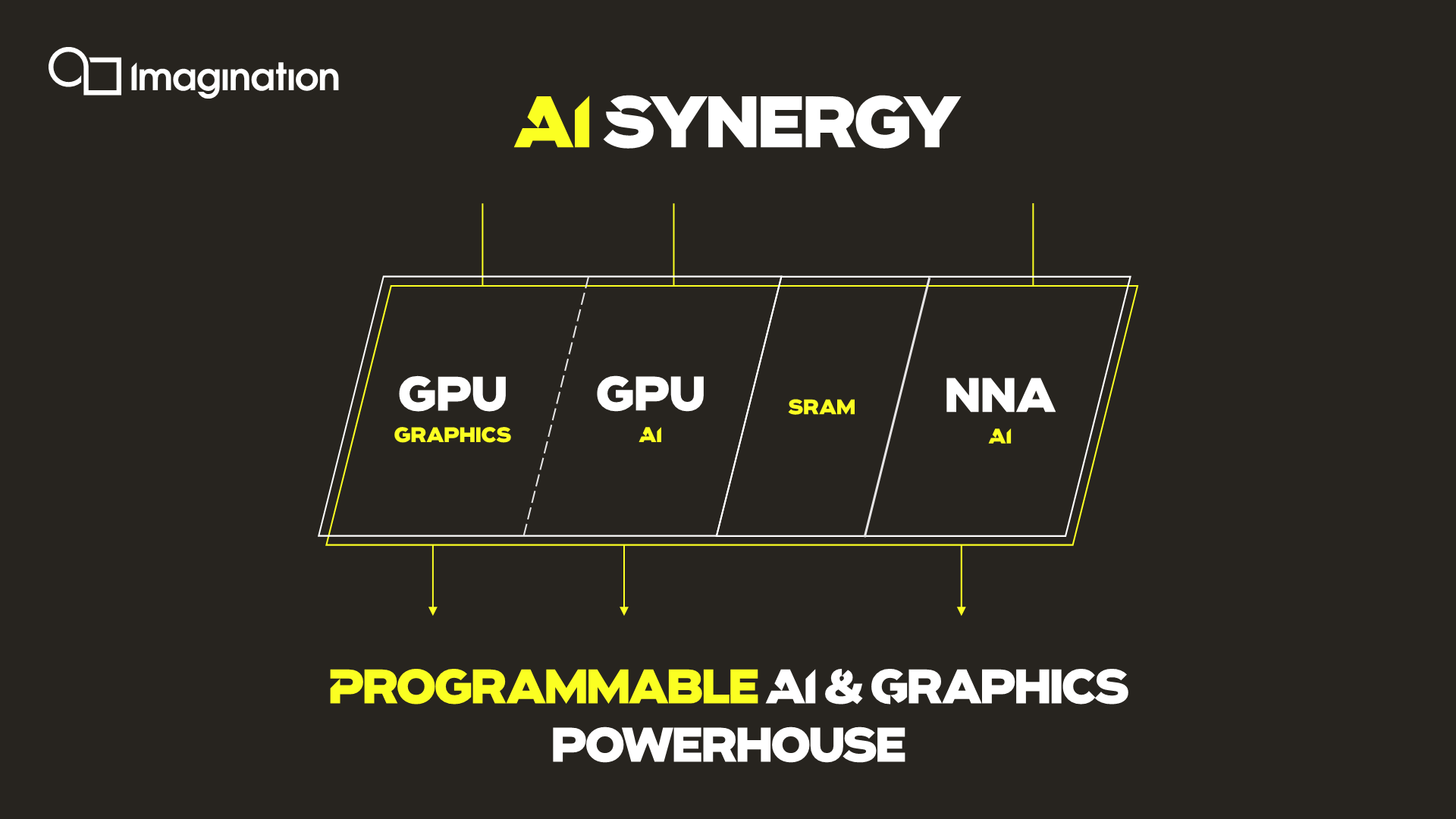
An interesting application of the technology is the synergy it allows between an A-Series GPU and the company’s in-house neural network accelerator IP. It would be able to share AI workloads between the two IP blocks, with the GPU for example handling the more programmable layers of a model while still taking advantage of the NNA’s efficiency for the fixed function fully connected layer processing.
Three Dozen Other Microarchitectural Improvements
The A-Series comes with other numerous microarchitectural advancements that are said to be advantageous to the GPU IP.

One such existing feature is the integration of a small dedicated CPU (which we understand to be RISC-V based) acting as a firmware processor, handling GPU management tasks that in other architectures might be still be handled by drivers on the host system CPU. The firmware processor approach is said to achieve more performant and efficient handling of various housekeeping tasks such as debugging, data logging, GPIO handling and even DVFS algorithms. In contrast as an example, DVFS for Arm Mali GPUs for example is still handled by the kernel GPU driver on the host CPUs.

An interesting new development feature that is enabled by profiling the GPU’s hardware counters through the firmware processor is creating tile heatmaps of execution resources used. This seems relatively banal, but isn’t something that’s readily available for software developers and could be extremely useful in terms of quick debugging and optimizations of 3D workloads thanks to a more visual approach.








143 Comments
View All Comments
Eliadbu - Tuesday, December 3, 2019 - link
Same as Nvidia AMD Apple ARM and almost all other fabless manufacturers "bring it out". Actual manufacturing is one part of story of creating and bringing processor to life.mode_13h - Wednesday, December 4, 2019 - link
Actually, like *none* of those! Those guys all sell chips.Imagination sells IP to other companies, which bundle it into their SoCs. However, Imagination still needs to work with fabs to make their design compatible with the process nodes customers are likely to want to use.
mode_13h - Wednesday, December 4, 2019 - link
Oops, I see you said ARM. Okay, so that's the one example that's like Imagination - ARM doesn't sell chips, either.rpg1966 - Monday, December 2, 2019 - link
"currently there’s no publicly announced or available chips which make use of the company’s 8XT or 9XTP designs"Does this mean they went through two entire design processes with zero sales? Surely not?
rpg1966 - Monday, December 2, 2019 - link
nvm, that's just the XT series, it seems.Spunjji - Tuesday, December 3, 2019 - link
Yeah, I think they only really ever sold those larger GPUs to Apple before.melgross - Tuesday, December 3, 2019 - link
Correct.ABR - Tuesday, December 3, 2019 - link
Nice article, but need to see products to see it working in practice. So how about that RDNA architecture article? There are a few out there now, working off of AMD's material, but it would be nice to see AT's perspective on how much it resets the competition with Nvidia, and what we could expect Samsung will be able to come up with out of it on mobile.mode_13h - Wednesday, December 4, 2019 - link
Nobody knows the precise details of the AMD/Samsung collaboration, so it's really hard to speculate on how the result will turn out.techjam - Tuesday, December 3, 2019 - link
Exciting news! Hopefully this will push Qualcomm to up their game. Not that the Adreno GPU's are bad but the yearly increases are fairly modest.One concern though, that naming scheme is awful. Starting with A and moving down to D? Seriously?