AMD Joins CXL Consortium: Playing in All The Interconnects
by Anton Shilov on July 19, 2019 5:00 PM EST- Posted in
- Interconnect
- AMD
- CXL
- PCIe 5.0

AMD's CTO, Mark Papermaster, has stated in a blog that AMD has joined the Compute Express Link (CXL) Consortium. The industry group is led by nine industry giants including Intel, Alibaba, Google, and Microsoft, but has over 35 members. The CXL 1.0 technology uses the PCIe 5.0 physical infrastructure to enable a coherent low-latency interconnect protocol that allows to share CPU and non-CPU resources efficiently and without using complex memory management. The announcement indicates that AMD now supports all of the current and upcoming non-proprietary high-speed interconnect protocols, including CCIX, Gen-Z, and OpenCAPI.
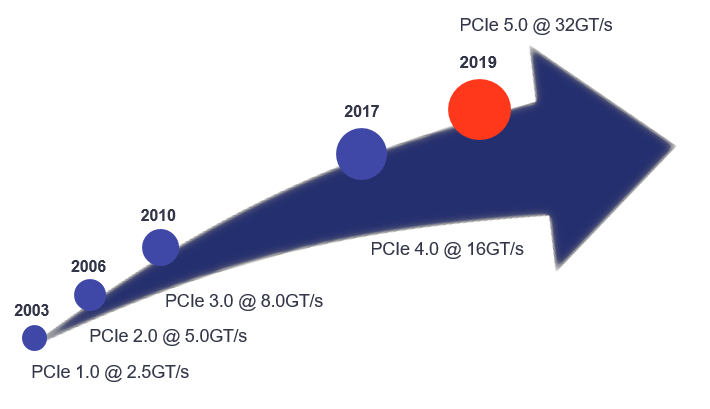
PCIe has enabled a tremendous increase of bandwidth from 2.5 GT/s per lane in 2003 to 32 GT/s per lane in 2019 and is set to remain a ubiquitous physical interface of upcoming SoCs. Over the past few years it turned out that to enable efficient coherent interconnect between CPUs and other devices, specific low-latency protocols were needed, so a variety of proprietary and open-standard technologies built upon PCIe PHY were developed, including CXL, CCIX, Gen-Z, Infinity Fabric, NVLink, CAPI, and other. In 2016, IBM (with a group of supporters) went as far as developing the OpenCAPI interface relying on a new physical layer and a new protocol (but this is a completely different story).

Each of the protocols that rely on PCIe have their peculiarities and numerous supporters. The CXL 1.0 specification introduced earlier this year was primarily designed to enable heterogeneous processing (by using accelerators) and memory systems (think memory expansion devices). The low-latency CXL runs on PCIe 5.0 PHY stack at 32 GT/s and supports x16, x8, and x4 link widths natively. Meanwhile, in degraded mode it also supports 16.0 GT/s and 8.0 GT/s data rates as well as x2 and x1 links. In case of a PCIe 5.0 x16 slot, CXL 1.0 devices will enjoy 64 GB/s bandwidth in each direction. It is also noteworthy that the CXL 1.0 features three protocols within itself: the mandatory CXL.io as well as CXL.cache for cache coherency and CXL.memory for memory coherency that are needed to effectively manage latencies.
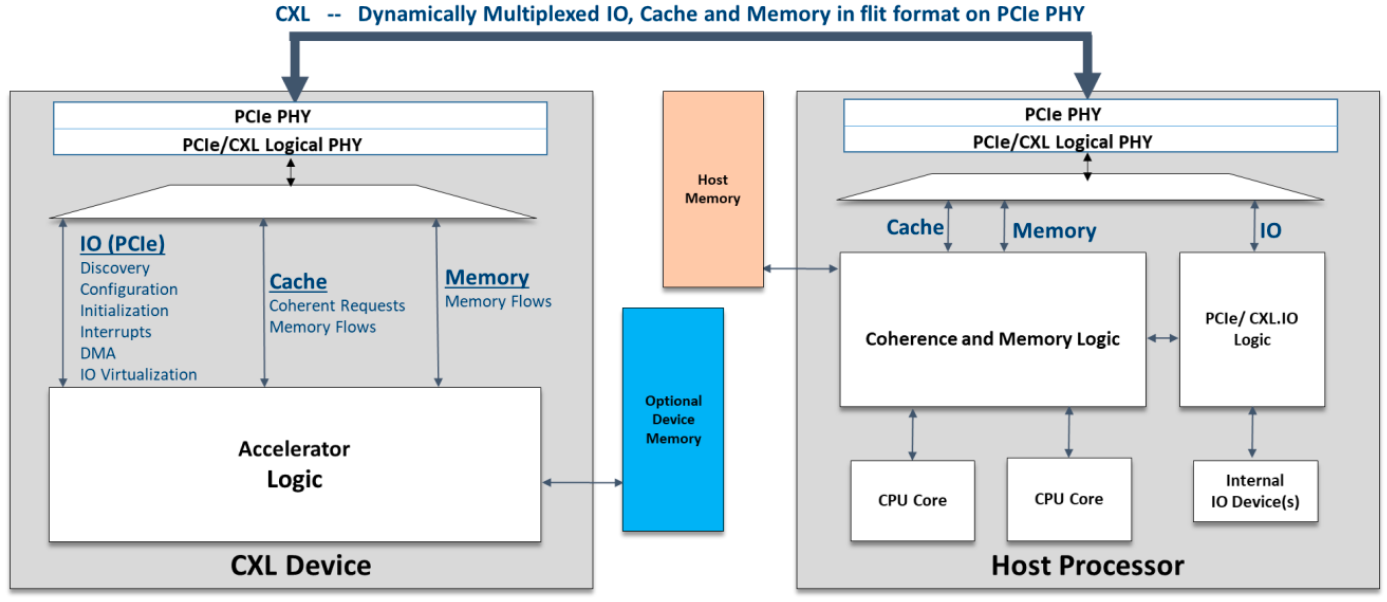
In the coming years computers in general and machines used for AI and ML processing will require a diverse combination of accelerators featuring scalar, vector, matrix and spatial architectures. For efficient operation, some of these accelerators will need to have low-latency cache coherency and memory semantics between them and processors, but since there is no ubiquitous protocol that supports appropriate functionality, there will be a fight between some of the standards that do not complement each other.
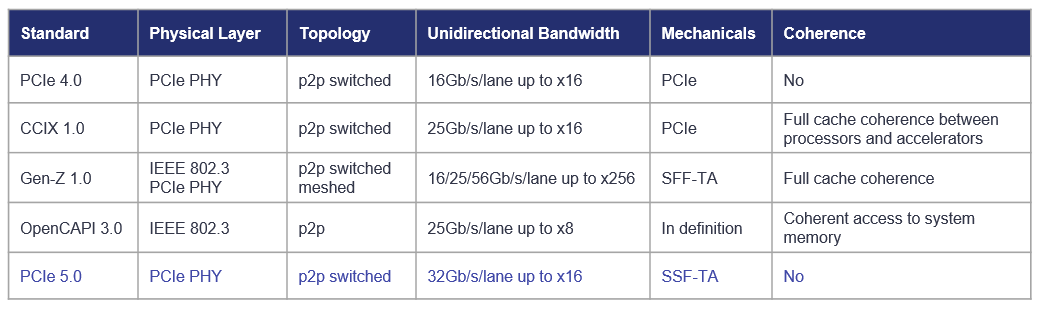
The biggest advantage of CXL is that it is not only supported by over 30 companies already, but its founding members include such heavyweights as Alibaba, DellEMC, Facebook, Google, HPE, Huawei, Intel, and Microsoft. All of these companies build their own hardware architectures and their support for CXL means that they plan to use the technology. Since AMD clearly does not want to be left behind the industry, it is natural for the company to join the CXL party.
Since CXL relies on PCIe 5.0 physical infrastructure, companies can use the same physical interconnects but develop the transmission logic required. At this point AMD is not committing to enabling CXL on future products, but is throwing its hat into the ring to discuss how the protocol develops, should it appear in a future AMD product.
Related Reading:
- Compute Express Link (CXL): From Nine Members to Thirty Three
- CXL Specification 1.0 Released: New Industry High-Speed Interconnect From Intel
- Gen-Z Interconnect Core Specification 1.0 Published
- Hot Chips: Intel EMIB and 14nm Stratix 10 FPGA Live Blog (8:45am PT, 3:45pm UTC)
Sources: AMD, CXL Consortium, PLDA








43 Comments
View All Comments
DanNeely - Sunday, July 21, 2019 - link
The latency of PCIe I assumenevcairiel - Saturday, July 20, 2019 - link
Quad Channel memory on eg. the Skylake-X platform doesn't really have a much higher latency, while doubling the theoretical bandwidth.mode_13h - Friday, July 19, 2019 - link
I wonder if mainstream will eventually move to PCIe 5.0, but probably not.ats - Saturday, July 20, 2019 - link
Never. The latency overhead of all these coherent I/O protocols is way to high to be viable for main memory.mode_13h - Saturday, July 20, 2019 - link
My point was that nevcairiel's concerns with memory bandwidth seemed rather premature, if not altogether presumptuous.Besides, the era of DDR4 will be past, if PCIe 5.0 ever hits the mainstream.
nevcairiel - Saturday, July 20, 2019 - link
I would assume that eventually everyone will move to PCIe 5.0, even if it'll be a while.And sure, at that point we'll likely be at DDR5 as well, which increases the bandwidth. But frequency alone only gets you so far, at some point it might be beneficial to go to Quad Channel.
But of course the complexity of routing 4 memory channel instead of 2, and all that, will probably mean it'll never be "mainstream", and people that require higher memory bandwidth should just go with a HEDT platform.
mode_13h - Tuesday, July 23, 2019 - link
Well, PCIe 5.0 uses yet more power and increases board costs. That's why I'm not sure it's destined for the mainstream.As for memory bandwidth, perhaps CPUs with in-package HBM-style memory will eventually happen.
Targon - Sunday, July 21, 2019 - link
People keep assuming that the Intel approach of doing things the same way, only faster is how the industry will continue to move forward. The idea of needing more memory channels to get more bandwidth is limited, and assumes a lack of innovation. Even PCI Express may be replaced in the next six years with something new.eek2121 - Saturday, July 20, 2019 - link
One thing you need to learn about the tech industry is "never" say "never". Latency of PCIE 4.0 is only around 150ns. PCIE 5.0 is even lower. It won't be long before latency is equal for both interfaces.eek2121 - Saturday, July 20, 2019 - link
Oh and one more thing to add, latency is not the most critical element of DRAM. It helps, sure, but latency has remained pretty much unchanged (very little variation) as memory speeds have increased. This is because the memory controller of the CPU itself along with the traces/interconnects add more latency than the DRAM modules. The actual latency of a DRAM module is between 8 and 10ns. The latency between the CPU and DRAM module is usually between 50 and 70ns.