Investigating NVIDIA's Jetson AGX: A Look at Xavier and Its Carmel Cores
by Andrei Frumusanu on January 4, 2019 11:00 AM EST- Posted in
- NVIDIA
- SoCs
- Xavier
- Automotive
- Jetson
- Jetson AGX
NVIDIA's Carmel CPU Core - SPEC2006 Speed
While the Xavier’s vision and machine processing capabilities are definitely interesting, it’s use-cases will be largely out-of-scope for the average AnandTech reader. One of the aspects of the chip that I was personally more interested in was NVIDIA’s newest generation Carmel CPU cores, as it represents one of the rare custom Arm CPU efforts in the industry.
Memory Latency
Before going into the SPEC2006 results, I wanted to see how NVIDIA’s memory subsystem compares against some comparable platform in the Arm space.
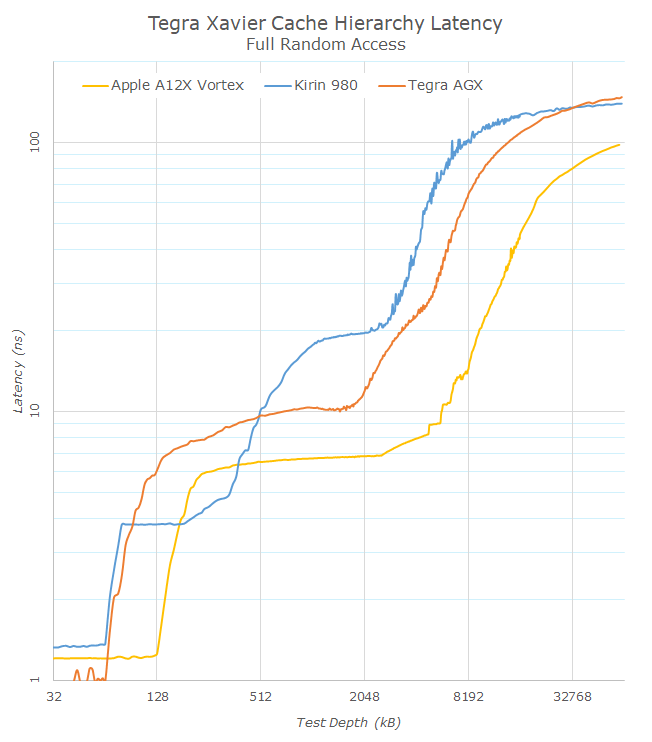
In the first logarithmic latency graph, we see the exaggerated latency curves which make it easy to determine the various cache hierarchy levels of the systems. As NVIDIA advertises, we see the 64KB L1D cache of the Carmel cores. What is interesting here is that NVIDIA is able to achieve quite a high performance L1 implementation with just under 1ns access times, representing a 2-cycle access which is quite uncommon. The second hierarchy cache is the L2 that continues on to the 2MB depth, after which we see the 4MB L3 cache. The L3 cache here looks to be of a non-uniform-access design as its latency steadily rises the further we go.
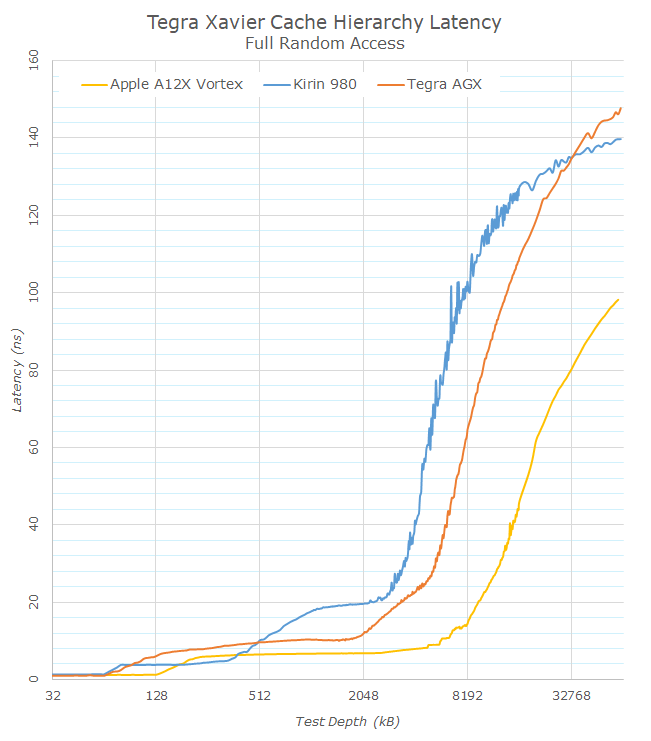
Switching back to a linear graph, NVIDIA does have a latency advantage over Arm’s Cortex-A76 and the DSU L3 of the Kirin 980, however it loses out at deeper test depths and latencies at the memory controller level. The Xavier SoC comes with 8x 32bit (256bit total) LPDDR4X memory controller channels, representing a peak bandwidth of 137GB/s, significantly higher than the 64 or 128bit interfaces on the Kirin 980 or the Apple A12X. Apple overall still has an enormous memory latency advantage over the competition as its massive 8MB L2 cache as well as the 8MB SLC (System level cache) allows for significant lower latencies across all test depths.
SPEC2006 Speed Results
A rarity for whenever we're looking at Arm SoCs and products built around them, NVIDIA’s Jetson AGX comes with a custom image for Ubuntu Linux (18.04 LTS). On one hand, including a Linux OS gives us a lot of flexibility in terms of test platform tools; but on the other hand, it also shows the relatively immaturity of Arm on Linux. One of the more regretful aspects of Arm on Linux is browser performance; to date the available browsers are still lacking optimised Javascript JIT engines, resulting in performance that is far worse than any commodity mobile device.
While we can’t really test our usual web workloads, we do have the flexibility of Linux to just simply compile whatever we want. In this case we’re continuing our use of SPEC2006 as we have a relatively established set of figures on all relevant competing ARMv8 cores.
To best mimic the setup of the iOS and Android harnesses, we chose the Clang 8.0.0 compiler. To keep things simple, we didn’t use any special flags other than –Ofast and a scheduling model targeting the Cortex-A53 (It performed overall better than no model or A57 targets). We also have to remind readers that SPEC2006 has been retired in favour of SPEC2017, and that the results published here are not officially submitted scores, rather internal figures that we have to describe as estimates.
The power efficiency figures presented for the AGX, much like all other mobile platforms, represent the active workload power usage of the system. This means we’re measuring the total system power under a workload, and subtracting the idle power of the system under similar circumstances. The Jetson AGX has a relatively high idle power consumption of 8.92W in this scenario, much that can be simply be attributed from a relatively non-power optimised board as well as the fact that we’re actively outputting via HDMI while having the board connected to GbE.
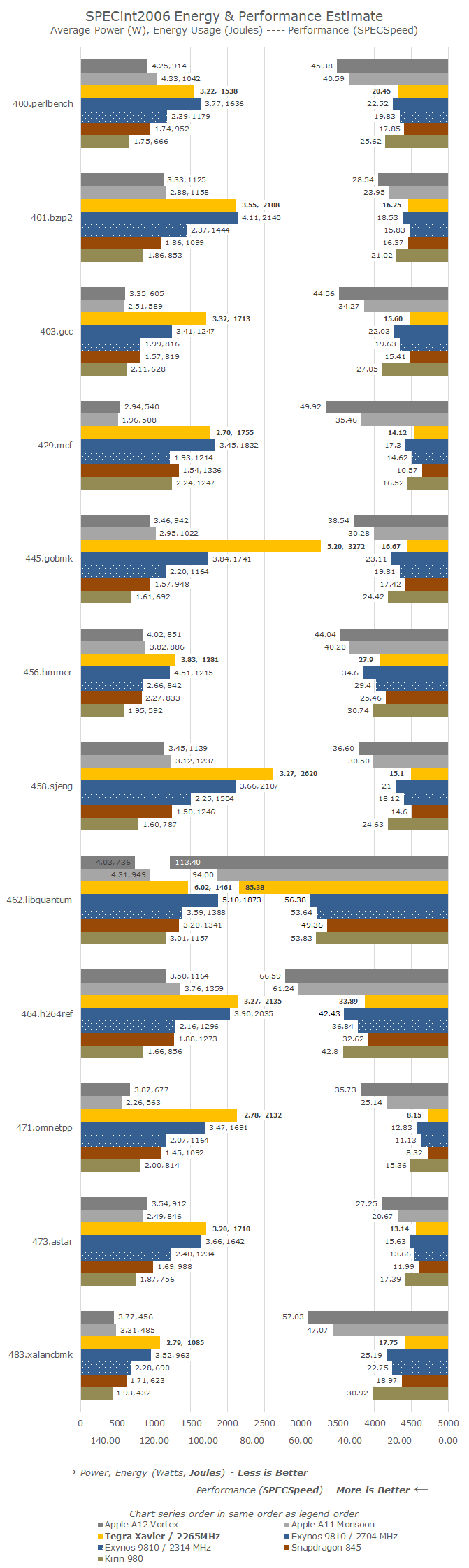
In the integer workloads, the Carmel CPU cores' performance is quite average. Overall, the performance across most workloads is extremely similar to that of Arm’s Cortex-A75 inside the Snapdragon 845, with the only outlier being 462.libquantum which showcases larger gains due to Xavier’s increased memory bandwidth.
In terms of power and efficiency, the NVIDIA Carmel cores again aren’t quite the best. The fact that the Xavier module is targeted at a totally different industry means that its power delivery possibly isn’t quite as power optimised as on a mobile device. We also must not forget that the Xavier has an inherent technical disadvantage of being manufactured on a 12FFN TSMC process node, which should be lagging behind Samsung’s 10LPP processes of the Exynos 9810 and the Snapdragon 845, and most certainly represents a major disadvantage against the newer 7nm Kirin 980 and Apple A12.
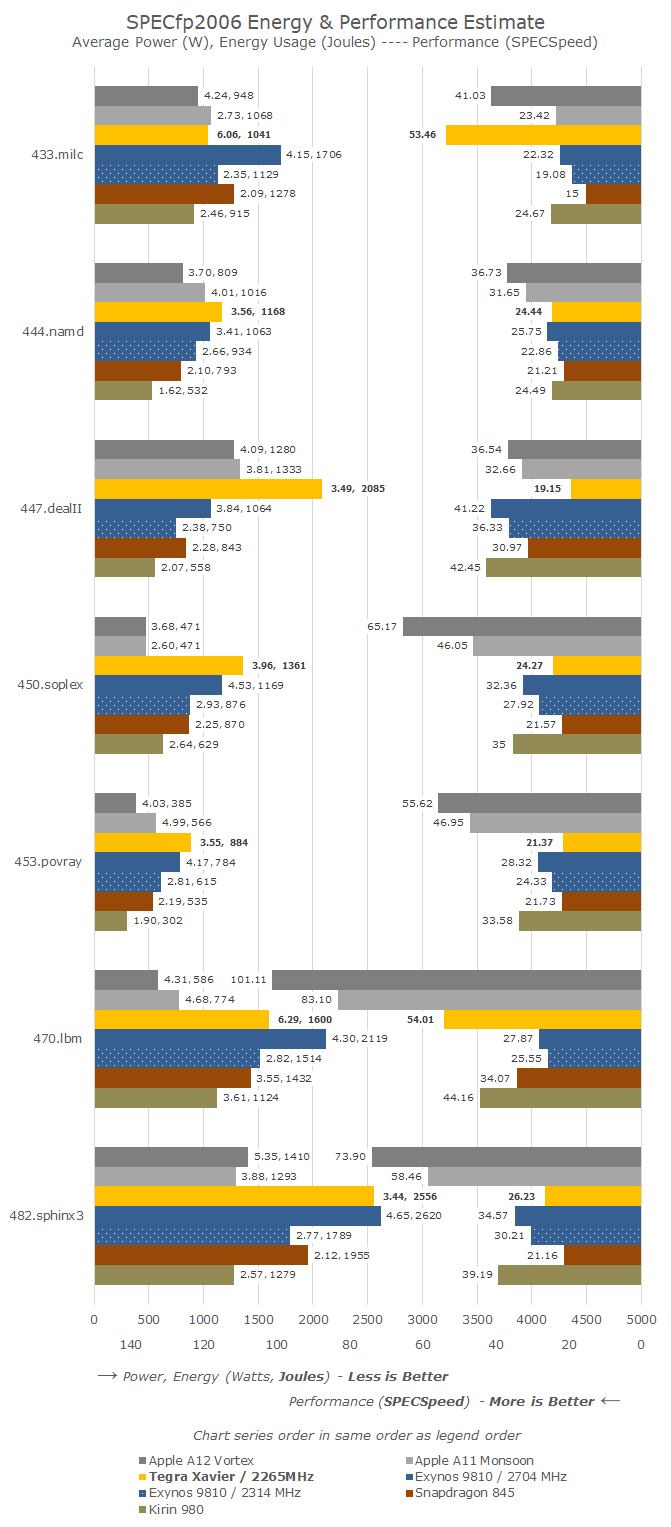
On the floating point benchmarks, Xavier fares overall better because some of the benchmarks are characterised by their sensitivity to the memory subsystem; in 433.milc this is most obvious. 470.lbm also sees the Carmel cores perform relatively well. In the other workloads however, again we see Xavier having trouble to differentiate itself much from the performance of a Cortex A75.
Here’s a wider performance comparison across SPEC2006 workloads among the most recent and important ARMv8 CPU microarchitectures:
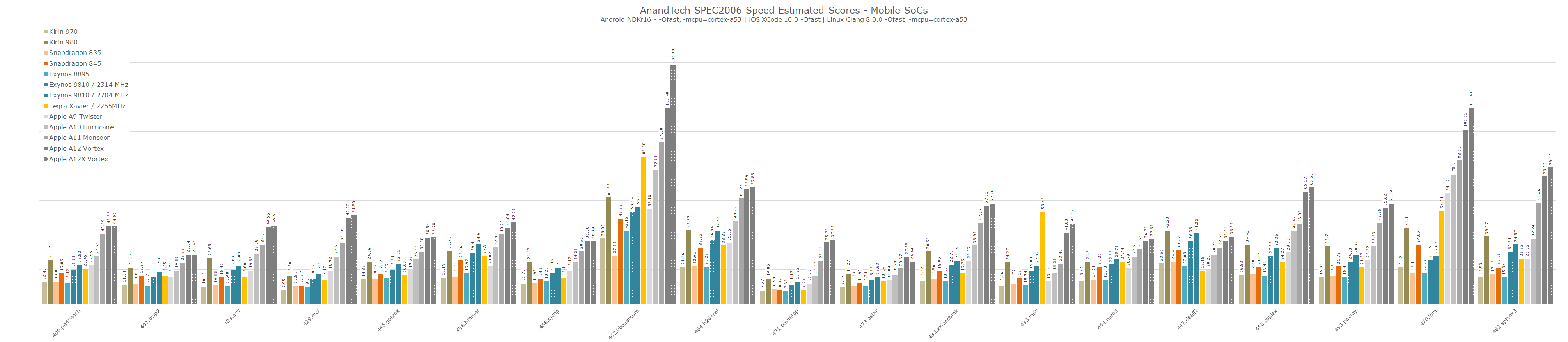
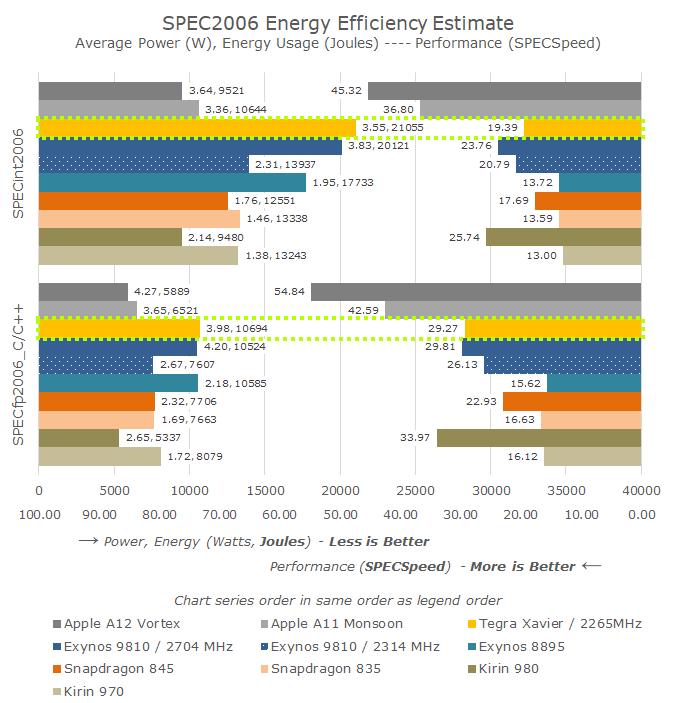
Overall, NVIDIA’s Carmel core seems like a big step up for NVIDIA and their in-house microarchitecture. However when compared against most recent cores from the competition, we see the new core having trouble able to really distinguish itself in terms of performance. Power efficiency of the AGX also lags behind, however this is something that was to be expected given the fact that the Jetson AGX is not a power optimised platform, beyond the fact that the chip’s 12FFN manufacturing process is a generation or two behind the latest mobile chips.
The one aspect which we can’t quantize NVIDIA’s Carmel cores is its features: This is a shipping CPU with ASIL-C functional safety features that we have in our hands today. The only competition in this regard would be Arm’s new Cortex A76AE, which we won’t see in silicon for at least another year or more. When taking this into account, it could possibly make sense for NVIDIA to have gone with its in-house designs, however as Arm starts to offer more designs for this space I’m having a bit of a hard time seeing a path forward in following generations after Xavier, as competitively, the Carmel cores don’t position themselves too well.








51 Comments
View All Comments
tipoo - Monday, January 7, 2019 - link
Man. Vortex continues to be streets ahead.