Futuremark Releases 3DMark Time Spy DirectX 12 Benchmark
by Daniel Williams on July 14, 2016 1:00 PM EST- Posted in
- GPUs
- Futuremark
- 3DMark
- Benchmarks
- DirectX 12

Today Futuremark is pulling the covers off of their new Time Spy benchmark, which is being released today for all Windows editions of 3DMark. A showcase of sorts of the last decade or so of 3DMark benchmarks, Time Spy is a modern DirectX 12 benchmark implementing a number of the API's important features. All of this comes together in a demanding test for those who think their GPU hasn’t earned its keep yet.
DirectX 12 support for game engines has been coming along for a few months now. To join in the fray Futuremark has written the Time Spy benchmark on top of a pure DirectX 12 engine. This brings features such as asynchronous compute, explicit multi-adapter, and of course multi-threading/multi-core work submission improvements. All of this comes together into what I think is not only visually interesting, but also borrows a large number of gaming assets from benchmarks of 3DMarks past.

For those who haven’t been following the 3DMark franchise for more than a decade, there are portions of the prior benchmarks showcased as shrunken museum exhibits. These exhibits come to life as the titular Time Spy wanders the hall, giving a throwback to past demos. I must admit a bit of fun was had watching to see what I recognized. I personally couldn’t spot anything older than 3DMark 2005, but I would be interested in hearing about anything I missed.
Unlike many of the benchmarks exhibited in this museum, the entirety of this benchmark takes place in the same environment. Fortunately, the large variety of eye candy present gives a varied backdrop for the tests presented. To add story in, we see a crystalline ivy entangled with the entire museum. In parts of the exhibit there are deceased in orange hazmat suits demonstrating signs of a previous struggle. Meanwhile, the Time Spy examines the museum with a handheld time portal. Through said portal she can view a bright and clean museum, and view bustling air traffic outside. I’ll not spoil the entire brief story here, but the benchmark makes good work of providing both eye candy for the newcomers and tributes for the enthusiasts that will spend ample time watching the events unroll.
From a technical perspective, this benchmark is, as you might imagine, designed to be the successor to Fire Strike. The system requirements are higher than ever, and while Fire Strike Ultra could run at 4K, 1440p is enough to bring even the latest cards to their knees with Time Spy.

Under the hood, the engine only makes use of FL 11_0 features, which means it can run on video cards as far back as GeForce GTX 680 and Radeon HD 7970. At the same time it doesn't use any of the features from the newer feature levels, so while it ensures a consistent test between all cards, it doesn't push the very newest graphics features such as conservative rasterization.
That said, Futuremark has definitely set out to make full use of FL 11_0. Futuremark has published an excellent technical guide for the benchmark, which should go live at the same time as this article, so I won't recap it verbatim. But in brief, everything from asynchronous compute to resource heaps get used. In the case of async compute, Futuremark is using it to overlap rendering passes, though they do note that "the asynchronous compute workload per frame varies between 10-20%." On the work submission front, they're making full use of multi-threaded command queue submission, noting that every logical core in a system is used to submit work.

Meanwhile on the multi-GPU front, Time Spy is also mGPU capable. Futuremark is essentially meeting the GPUs half-way here, using DX12 explicit multi-adapter's linked-node mode. Linked-node mode is designed for matching GPUs - so there isn't any Ashes-style wacky heterogeneous configurations supported here - trading off some of the fine-grained power of explicit multi-adapter for the simplicity of matching GPUs and useful features that can only be done with matching GPUs such as cross-node resource sharing. For their mGPU implementation Futuremark is using otherwise common AFR, which for a non-interactive demo should offer the best performance.
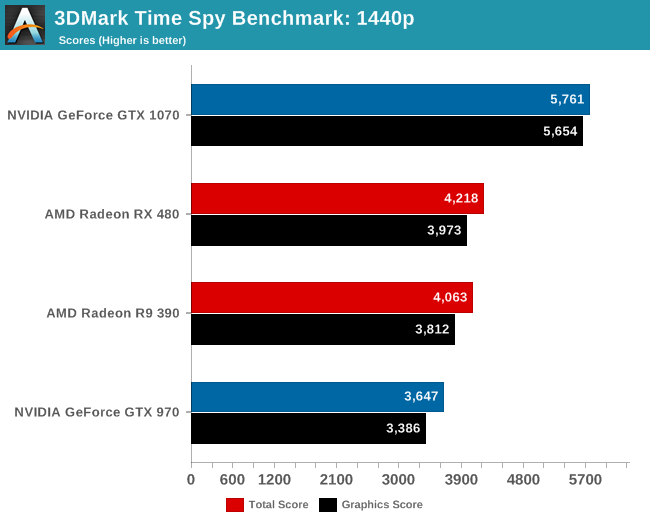
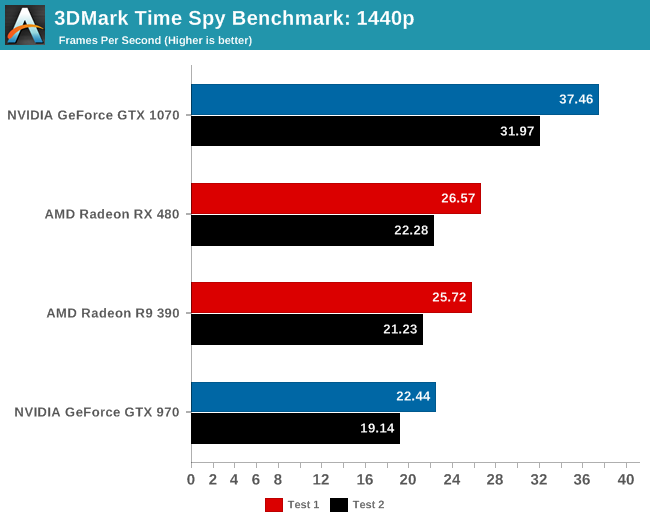
To take a quick look at the benchmark, we ran the full test on a small number of cards on the default 1440p setting. In our previous testing AMD’s RX 480 and R9 390 traded blows with each other and NVIDIA’s GTX 970. Here though, the RX 480 pulls a small lead over the R9 390 while they both leave a slightly larger gap ahead of the GTX 970. Only to then see the GeForce GTX 1070 appropriately zip past the lot of them.
The graphics tests scale similarly to the overall score in this case, and if these tests were a real game anything less than the GTX 1070 would provide a poor gameplay experience with framerates under 30 fps. While we didn’t get any 4K numbers off our test bench, I ran a GTX 1080 in my personal rig (i7-2600k @4.2GHz) and saw 4K scores that were about half of my 1440p scores. While this is a synthetic test, the graphical demands this benchmark can place on a system will provide a plenty hefty workload for any seeking it out.
Meanwhile, for the Advanced and Professional versions of the benchmark there's an interesting ability to run it with async compute disabled. Since this is one of the only pieces of software out right now that can use async on Pascal GPUs, I went ahead and quickly ran the graphics test on the GTX 1070 and RX 480. It's not an apples-to-apples comparison in that they have much different performance levels, but for now it's the best look we can take at async on Pascal.
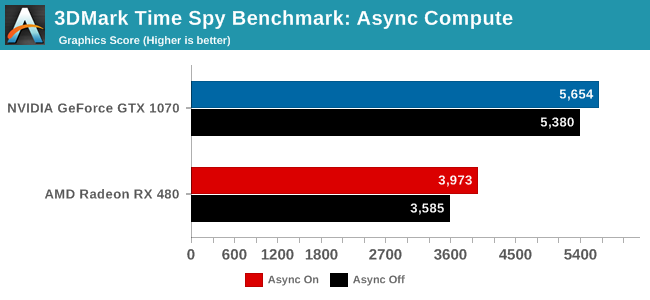
Both cards pick up 300-400 points in score. On a relative basis this is a 10.8% gain for the RX 480, and a 5.4% gain for the GTX 1070. Though whenever working with async, I should note that the primary performance benefit as implemented in Time Spy is via concurrency, so everything here is dependent on a game having additional work to submit and a GPU having execution bubbles to fill.
The new Time Spy test will be coming today to Windows users of 3DMark. This walk down memory lane not only puts demands on the latest gaming hardware but also provides another showcase of the benefits DX12 can bring to our games. To anyone who’s found FireStrike too easy of a benchmark, keep an eye out for Time Spy in the near future.








75 Comments
View All Comments
Yojimbo - Friday, July 15, 2016 - link
On further exploration it does seem like the driver is the one who tries to set up the static partitioning, by looking at the application. But I think with Pascal the programmer can request the driver to not allow dynamic load balancing.Scali - Saturday, July 16, 2016 - link
There shouldn't be 'static partitioning'... In the D3D API you can create a number of queues to submit work to, and you can assign low or high priority to each queue. See here: https://msdn.microsoft.com/en-us/library/windows/d...So both the number of queues, and the priority of each queue, is configured by the application.
It is up to the driver to dynamically schedule the workloads in these queues, while maintaining the requested priorities.
looncraz - Friday, July 15, 2016 - link
One of us is not understanding things accurately...Preemption has a lot to do with async compute's performance, but more to do with how well the GPU can shuffle multiple long-running compute tasks. Both AMD and Intel have been FAR ahead of nVidia in this area, nVidia is desperately attempting to seek parity.
The 5% they are gaining from async compute now here can be mostly (if not entirely) attributed to their work on preemption, in fact.
nVidia in no way had async compute in DX11. While their drivers did a great job of optimizing the graphics queue their hardware was so horribly inefficient with concurrent computation and intensive graphics that they had to create time windows for PhysX. There, though, they had so much control their hardware's weaknesses wasn't really an issue - therefore not a weakness at all, really, when it came to gaming.
The new APIs have simply revealed where AMD was strong - in context switching. AMD's original GCN is an order of magnitude faster than nVidia's Maxwell when it comes to context switching - which occurs in preemption - so nVidia is just playing catch-up. Pascal helps to remove a small part of AMD's advantage here.
Further, AMD uses dedicated schedulers (ACEs) to help with asynchronous compute - the RX 480 has cut their numbers in half, so it is the worst-case scenario for async compute scaling moving forward (well, Polaris 11 should be worse still). Fury is seeing 50% scaling with Vulkan...
Scali - Friday, July 15, 2016 - link
"Both AMD and Intel have been FAR ahead of nVidia in this area, nVidia is desperately attempting to seek parity."Say what?
Afaik Intel does not implement async compute yet in DX12.
nVidia has introduced async compute in the form of HyperQ for CUDA on Kepler.
I suggest you read up on HyperQ and what it's supposed to do.
TL;DR: It solves the problem of running multiple processes (or threads) with GPGPU tasks on a single GPU, by having multiple work queues that the processes/threads can submit work to. In the case of Kepler, these were 32 separate queues, so up to 32 streams of compute workloads could be sent to the GPU in parallel, and the GPU would execute these concurrently.
DX12 async compute is the same principle, except that they seamlessly integrate it with graphics as well, so one of the queues can accept both graphics and compute workloads, where the other queues accept only compute workloads (CUDA was compute-only, and could be used in parallel with OpenGL or Direct3D for graphics).
I understand that 99.9999999% of the people online don't understand more than 1% of this stuff.
I just wish they would not post on the subject and spread all sorts of damaging misinformation.
Yojimbo - Friday, July 15, 2016 - link
But I think he's right that AMD did do a lot of early work in the area. When AMD bought ATI their hope was to create a heterogeneous processor combining both the CPU and the GPU. Therefore these issues were something they immediately came up against. I think maybe they didn't optimize their GCN design for DirectX 11 or the use of their GPUs as coprocessors because they had more ambitious goals. Those goals fell through and it wasn't until Mantle that some of the features of their architecture could be taken advantage of. NVIDIA was more conservative in their approach and I'm sure these issues were on their long-term radar, but they weren't directly concerned with them because they believed that the latency mismatch between GPUs and CPUs and the memory technologies available meant that a marriage of the CPU with the GPU was not advantageous. Plus they didn't have a good means of doing such a marriage themselves (although AMD reportedly wanted to buyout NVIDIA rather than ATI and NVIDIA declined).At this point, though, I think NVIDIA with an x86 license would be a pretty interesting competitor to Intel. I'm guessing that a big reason KNL was made a bootable processor was to allow Xeon Phi high speed access to main memory without allowing it to NVIDIA's GPUs. It was so important to them that they sacrificed the ability to have flexible node topologies (multiple processors per node).
Scali - Friday, July 15, 2016 - link
Well, given that GCN and Kepler are about as old, and both implement pretty much the same async compute technology, I don't think you can say one did more 'early work' than the other.If anyone did any 'early work', then I would say it is nVidia, who pretty much single-handedly invented compute shaders and everything that goes with it, with the first version of CUDA in the 8800.
Async compute was just an evolution of CUDA, as they found that traditional HPC tended to work with MPI solutions with multiple processes. So this led to HyperQ. I would certainly not say that nVidia is the 'conservative one' when it comes to compute.
AMD isn't a big player in the HPC market, so I'm not quite sure what they wanted to achieve with their ACE's. I don't think it has anything to do with heterogeneous processing though.
bluesoul - Saturday, July 16, 2016 - link
Asynchronous compute + graphics does not work due to the lack of proper Ressource Barrier support under HyperQ that prevents further command execution until the GPU has finished doing any work needed to convert the resources as requested. Without Ressource Barrier support, HyperQ implementation cannot be used by DX12 in order to execute Graphics and Compute commands in parallel.Scali - Saturday, July 16, 2016 - link
Do you have any sources for these claims?The nVidia documentation I read states that command lists are split up at any fences. As long as you have good pre-emption/scheduling, it's a perfectly workable solution.
See also: https://developer.nvidia.com/dx12-dos-and-donts
donkay - Thursday, July 14, 2016 - link
Yes, both nvidia (pascal) and amd get better performance with async. The possible performance increase is just much bigger for AMD.Yojimbo - Thursday, July 14, 2016 - link
True, but I don't think it's well-understood in the fan community at large whether AMD's greater performance benefit from asynchronous compute is because of a superior asynchronous compute implementation or rather because AMD's architecture is simply less efficient at filling its pipelines than NVIDIA's and asynchronous compute simply closes that gap somewhat by taking some of the "air" out of the pipelines.In the end what matters is the comparative performance in real-world situations of course, regardless of how it gets there. But as people like to say that AMD has an advantage in DX12, or that NVIDIA sucks at DX12, the accuracy of those statements hinge partly on the answer to the above question. If the case is the latter, that DX12 helps to compensate for inefficiencies in AMD's GPUs through additional work by the developer, then such statements are not accurate.